




此处记录了我觉得有意思的一些问答,所有回答均来自本人在各平台的回复,不定期更新
| SOURCE:CSDN_ASK |
| ASK_ID:7726256 |
| ANSWER_ID:53801385 |
| TITLE:如何截取指定的内容生成新的字段 |
ANSWER:
这样的话,假设你已经把简称存到了 A表 的 name列 里,且原始字符串不存在歧义(可能判断出多个小区),那么可以使用like或者instr函数进行关联.假设原字符串存在于B表的ADDR列 当然也可以使用标量子查询,方法类似。 |
| LINK:https://ask.csdn.net/questions/7726256?answer=53801385 |
| SOURCE:CSDN_ASK |
| ASK_ID:7726274 |
| ANSWER_ID:53801377 |
| TITLE:虚拟机配置后出现的问题,如何解决 |
| ANSWER: 没有设置启动光盘,请确保选择了正确的启动光盘
|
| LINK:https://ask.csdn.net/questions/7726274?answer=53801377 |

| SOURCE:CSDN_ASK |
| ASK_ID:7724256 |
| ANSWER_ID:53800897 |
| TITLE:sql,将一个表的数据按照某字段分组 |
| ANSWER: 你这个格式像个json又不是json,这样输出出来,应用识别不了啊,而且你这分组啥都没做,直接一个select *查给应用,让应用自己做分组展示不好么?
|
| LINK:https://ask.csdn.net/questions/7724256?answer=53800897 |

| SOURCE:CSDN_ASK |
| ASK_ID:7724389 |
| ANSWER_ID:53800891 |
| TITLE:请问oracle数据这个数据块怎么实现 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7724389?answer=53800891 |

| SOURCE:CSDN_ASK |
| ASK_ID:7725962 |
| ANSWER_ID:53800888 |
| TITLE:oracle存储过程有编译错误 |
| ANSWER: 把 number(5) 改成 number |
| LINK:https://ask.csdn.net/questions/7725962?answer=53800888 |
| SOURCE:CSDN_ASK |
| ASK_ID:7725965 |
| ANSWER_ID:53800882 |
| TITLE:oracle 11g版本 换成12C版本以后自定义function失效了 |
| ANSWER: 去你11g的库里,把这个type "type_split"的代码复制到12c里创建一下 |
| LINK:https://ask.csdn.net/questions/7725965?answer=53800882 |
| SOURCE:CSDN_ASK |
| ASK_ID:7725863 |
| ANSWER_ID:53800787 |
| TITLE:安装oracle database 19c的时候报错 |
ANSWER:
从oracle支持网站检索得到,19c版本支持在win10 64位系统上运行,不支持在32位系统上运行,另外,家庭版也不支持
|
| LINK:https://ask.csdn.net/questions/7725863?answer=53800787 |


| SOURCE:CSDN_ASK |
| ASK_ID:7725885 |
| ANSWER_ID:53800786 |
| TITLE:数据库表的创建之如何创建一个数据表 |
| ANSWER: 这张单据存到数据库里,常见的是用两张表,
厂商名称,从厂商基础信息表里面取; |
| LINK:https://ask.csdn.net/questions/7725885?answer=53800786 |
| SOURCE:CSDN_ASK |
| ASK_ID:7725522 |
| ANSWER_ID:53800720 |
| TITLE:sql-查询每日有效会员人数 |
| ANSWER: 我猜你这个数据是每个会员只有一行记录,后面的开始时间结束时间间隔时间很长,甚至可能达到几年,你想得到的结果是每天都有一行记录,然后对于每一个会员都要和每天来进行匹配,也就是说要将这个开始日期结束日期展开到每一天,然后再进行count。 |
| LINK:https://ask.csdn.net/questions/7725522?answer=53800720 |
| SOURCE:CSDN_ASK |
| ASK_ID:7725803 |
| ANSWER_ID:53800703 |
| TITLE:sql 查询后的字段怎么加求和字段 |
| ANSWER: 方法一,再union all一行求和的select |
| LINK:https://ask.csdn.net/questions/7725803?answer=53800703 |
| SOURCE:CSDN_ASK |
| ASK_ID:7725499 |
| ANSWER_ID:53800218 |
| TITLE:oracle查询数据,以符号分割,显示多条数据 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7725499?answer=53800218 |

| SOURCE:CSDN_ASK |
| ASK_ID:7723523 |
| ANSWER_ID:53799319 |
| TITLE:sqlserver的存储过程转oracle |
| ANSWER: 建议把里面用到的表的表结构也提供一下,这样答题人可以自行验证下是否正确。 下面这个语法基本已经调整得查不多了,但是没有你的表,就没有全部改完,尤其是有些字段类型不知道是什么,比如说日期处理什么的,像那个convert我就暂时没改,剩下的你自己应该能改了吧 已按对应的字段类型,修改了相关函数,编译无报错了,这个全局临时表是会话级的,多会话并发不会产生冲突,会话结束后表里就没数据了。
|
| LINK:https://ask.csdn.net/questions/7723523?answer=53799319 |

| SOURCE:CSDN_ASK |
| ASK_ID:7724744 |
| ANSWER_ID:53799299 |
| TITLE:在sql里查询平均中的最大值 |
| ANSWER: 只要一个值: 保留平均值: |
| LINK:https://ask.csdn.net/questions/7724744?answer=53799299 |
| SOURCE:CSDN_ASK |
| ASK_ID:7721598 |
| ANSWER_ID:53798242 |
| TITLE:docker部署oracle11g出问题了 |
| ANSWER: 1521不行就1522, |
| LINK:https://ask.csdn.net/questions/7721598?answer=53798242 |
| SOURCE:CSDN_ASK |
| ASK_ID:7722182 |
| ANSWER_ID:53798235 |
| TITLE:取opstaion的手机号码信息(符合11位长度的数字),若不符合手机号规则,则置空值 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7722182?answer=53798235 |

| SOURCE:CSDN_ASK |
| ASK_ID:7723093 |
| ANSWER_ID:53798229 |
| TITLE:oracle求上一季度的数据 |
ANSWER:
加个开窗函数字段就好了 |
| LINK:https://ask.csdn.net/questions/7723093?answer=53798229 |

| SOURCE:CSDN_ASK |
| ASK_ID:7723629 |
| ANSWER_ID:53798222 |
| TITLE:mysql初学者,想问一下为什么修改字符集不能加if not exists我加了就改不了。 |
| ANSWER: 因为没这种语法,而且逻辑上也说不过去。 |
| LINK:https://ask.csdn.net/questions/7723629?answer=53798222 |
| SOURCE:CSDN_ASK |
| ASK_ID:7723728 |
| ANSWER_ID:53798212 |
| TITLE:请问什么是标量子查询? |
| ANSWER: 你这样写sql,执行会报语法错误。 |
| LINK:https://ask.csdn.net/questions/7723728?answer=53798212 |
| SOURCE:CSDN_ASK |
| ASK_ID:7717561 |
| ANSWER_ID:53790348 |
| TITLE:SQL Server条件语句 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7717561?answer=53790348 |
| SOURCE:CSDN_ASK |
| ASK_ID:7716875 |
| ANSWER_ID:53790337 |
| TITLE:oracle hints 优化器 /+full(t)/在测试环境生效,使用了全表扫描;生产环境不生效,仍然走了索引 |
| ANSWER: 因为CBO觉得你加的这个hint太离谱了,消耗成本过高,因此它自行选择了成本更低的方式。 |
| LINK:https://ask.csdn.net/questions/7716875?answer=53790337 |
| SOURCE:CSDN_ASK |
| ASK_ID:7717015 |
| ANSWER_ID:53790333 |
| TITLE:SQL如何查询表格每一行数据,并返回第一个不为空的数据的列名 |
| ANSWER: 用coalesce函数 |
| LINK:https://ask.csdn.net/questions/7717015?answer=53790333 |
| SOURCE:CSDN_ASK |
| ASK_ID:7717382 |
| ANSWER_ID:53790330 |
| TITLE:sql查询结果作为条件循环 |
| ANSWER: 这个要看你的数据库是什么,以及版本号是多少。 mysql递归如何实现,p_uid对应的uid数量-大数据-CSDN问答 CSDN问答为您找到mysql递归如何实现,p_uid对应的uid数量相关问题答案,如果想了解更多关于mysql递归如何实现,p_uid对应的uid数量 sql 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7667773?answer=53725612 然后下面这个页面有大量的sql问答,就是数据量太大,加载有点慢,等加载完后可以按单个关键词在页面中搜索相关sql |
| LINK:https://ask.csdn.net/questions/7717382?answer=53790330 |
| SOURCE:CSDN_ASK |
| ASK_ID:7716104 |
| ANSWER_ID:53788980 |
| TITLE:oracle创建的存储过程有问题,本人第一写有点不会,需要看下问题 |
| ANSWER: 少了as,没有end loop |
| LINK:https://ask.csdn.net/questions/7716104?answer=53788980 |
| SOURCE:CSDN_ASK |
| ASK_ID:7716233 |
| ANSWER_ID:53788976 |
| TITLE:领导经常然后我们用varchar存数字,这样有什么好处吗? |
| ANSWER: 主要看你的“数字”是否存在算数计算,如果不存在计算,而且长度还较长,那么存成字符类型是合理的 |
| LINK:https://ask.csdn.net/questions/7716233?answer=53788976 |
| SOURCE:CSDN_ASK |
| ASK_ID:7716446 |
| ANSWER_ID:53788972 |
| TITLE:关于mysql中使用sql语句的group by语句后查询元组丢失的问题 |
| ANSWER: 因为你group by了cno,每个cno就只会取一条,然后其他字段随机取一行。 |
| LINK:https://ask.csdn.net/questions/7716446?answer=53788972 |
| SOURCE:CSDN_ASK |
| ASK_ID:7713404 |
| ANSWER_ID:53787965 |
| TITLE:PLS-00103: 出现符号 "IN"在需要下列之一时,创建过程时报错 |
| ANSWER: in和out的位置不对 另外,oracle不建议使用varchar,而应该使用varchar2 |
| LINK:https://ask.csdn.net/questions/7713404?answer=53787965 |
| SOURCE:CSDN_ASK |
| ASK_ID:7714350 |
| ANSWER_ID:53787751 |
| TITLE:启动Docker desktop时一直处于starting状态之后产生堆栈跟踪错误 |
| ANSWER: 把你操作系统环境变量path里的东西贴出来一下,看看是不是系统本来的一些环境变量被清掉了 把下面这些都加进去 |
| LINK:https://ask.csdn.net/questions/7714350?answer=53787751 |
| SOURCE:CSDN_ASK |
| ASK_ID:7715592 |
| ANSWER_ID:53787747 |
| TITLE:sqlserver cast和convert 类型nvarchar(11)转换后的数据,和手工制作的'test'的普通字符串区别。 |
| ANSWER: 数字没加引号,前面的0会被省略。其实你直接执行一下下面的这条sql就知道区别了 |
| LINK:https://ask.csdn.net/questions/7715592?answer=53787747 |
| SOURCE:CSDN_ASK |
| ASK_ID:7707327 |
| ANSWER_ID:53778592 |
| TITLE:oracle字符集问题 |
ANSWER:
翻译如下
也就是说,你linux那台机器连接的数据库的字符集是AL32UTF8;你用PLSQLDEV连接的数据库的字符集是ZHS16GBK,连接的是两个不同的数据库。 能通过环境变量保持一致的,只有前面的 语言和地区,而后面的字符集无论怎么改,只要连的是同一个数据库,那么都会保持一致。 【ORACLE】谈一谈Oracle数据库使用的字符集,不仅仅是乱码_DarkAthena的博客-CSDN博客_oracle数据库默认字符集 一、前言先看一个比较有意思的案例上面这个sql,查询了a和b两个字段,均为"张三"两个汉字,并且使用length函数检查,长度均为2。但是,当你看到下面这几个sql的输出结果时,很有可能第一反应是:"这特喵的怎么可能?"其实,你所看到的两个"张三",的确长得是一模一样,用显微镜去看也不可能看到区别。但为什么a和b不相等呢?这是因为组成他们的成分不一样,这个成分就是 字符集二、什么是字符集?百度百科简单来说,字符(Character)是各种文字和符号的总称,包括各国家文字、标 https://darkathena.blog.csdn.net/article/details/122659532 |
| LINK:https://ask.csdn.net/questions/7707327?answer=53778592 |
| SOURCE:CSDN_ASK |
| ASK_ID:7708665 |
| ANSWER_ID:53778575 |
| TITLE:请教一个SQL问题,画线这段语句是什么意思? |
| ANSWER: 拼个字符串作为一个字段,这个字段内的内容是 "select * from 用户名.表名" |
| LINK:https://ask.csdn.net/questions/7708665?answer=53778575 |
| SOURCE:CSDN_ASK |
| ASK_ID:7706145 |
| ANSWER_ID:53775919 |
| TITLE:mysql创建表ERROR 1064 (42000): You have an error in your SQL syntax |
| ANSWER: 放大了仔细看,这两玩意不一样的,一个是尖括号,一个是圆括号
|
| LINK:https://ask.csdn.net/questions/7706145?answer=53775919 |

| SOURCE:CSDN_ASK |
| ASK_ID:7704560 |
| ANSWER_ID:53775179 |
| TITLE:Oracle中文乱码问题 |
| ANSWER: 首先你要确认一下是数据乱码了还是你本地客户端和代码页字符集不匹配。 【ORACLE】谈一谈Oracle数据库使用的字符集,不仅仅是乱码_DarkAthena的博客-CSDN博客_oracle数据库默认字符集 一、前言先看一个比较有意思的案例上面这个sql,查询了a和b两个字段,均为"张三"两个汉字,并且使用length函数检查,长度均为2。但是,当你看到下面这几个sql的输出结果时,很有可能第一反应是:"这特喵的怎么可能?"其实,你所看到的两个"张三",的确长得是一模一样,用显微镜去看也不可能看到区别。但为什么a和b不相等呢?这是因为组成他们的成分不一样,这个成分就是 字符集二、什么是字符集?百度百科简单来说,字符(Character)是各种文字和符号的总称,包括各国家文字、标 https://darkathena.blog.csdn.net/article/details/122659532?spm=1001.2014.3001.5502 |
| LINK:https://ask.csdn.net/questions/7704560?answer=53775179 |
| SOURCE:CSDN_ASK |
| ASK_ID:7705214 |
| ANSWER_ID:53775169 |
| TITLE:通过一个字段的三个参数(三个参数绑定为一个条件)怎么取对应的字段的值 |
ANSWER:或者 |
| LINK:https://ask.csdn.net/questions/7705214?answer=53775169 |
| SOURCE:CSDN_ASK |
| ASK_ID:7705342 |
| ANSWER_ID:53775154 |
| TITLE:oracle通过表名查表内全部数据的sql是什么 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7705342?answer=53775154 |
| SOURCE:CSDN_ASK |
| ASK_ID:7704973 |
| ANSWER_ID:53774246 |
| TITLE:orcale中如何用cast将数据类型为Enum的字段转为文本类型啊? |
| ANSWER: ENUM类型常见于MYSQL数据库中, |
| LINK:https://ask.csdn.net/questions/7704973?answer=53774246 |
| SOURCE:CSDN_ASK |
| ASK_ID:7704914 |
| ANSWER_ID:53774239 |
| TITLE:Python有一句话的对错 |
| ANSWER: 要把计算机科学理解成一种工具,一种用来解决其他领域中遇到的问题的工具,而不是为了研究计算机科学而去研究计算机科学,不能本末倒置。 |
| LINK:https://ask.csdn.net/questions/7704914?answer=53774239 |
| SOURCE:CSDN_ASK |
| ASK_ID:7704501 |
| ANSWER_ID:53773654 |
| TITLE:利用union谓词查询 |
| ANSWER: 把下面的where条件改下
你写的那个存在条件,由于没有和其他表关联,所以只要有一条满足,返回就是true,就相当于没有where条件了,查的是全部记录 |
| LINK:https://ask.csdn.net/questions/7704501?answer=53773654 |

| SOURCE:CSDN_ASK |
| ASK_ID:7704091 |
| ANSWER_ID:53773173 |
| TITLE:Windows11 sqlplus中文乱码问题 |
| ANSWER: 在oracle数据库中,任何以select形式查到的字符集,都是客户端字符集,用select是查不到服务端字符集的(网上很多文章都是错的)。
然后打开cmd,输入chcp 65001回车,再连接数据库执行查询。 【ORACLE】谈一谈Oracle数据库使用的字符集,不仅仅是乱码_DarkAthena的博客-CSDN博客_oracle数据库默认字符集 一、前言先看一个比较有意思的案例上面这个sql,查询了a和b两个字段,均为"张三"两个汉字,并且使用length函数检查,长度均为2。但是,当你看到下面这几个sql的输出结果时,很有可能第一反应是:"这特喵的怎么可能?"其实,你所看到的两个"张三",的确长得是一模一样,用显微镜去看也不可能看到区别。但为什么a和b不相等呢?这是因为组成他们的成分不一样,这个成分就是 字符集二、什么是字符集?百度百科简单来说,字符(Character)是各种文字和符号的总称,包括各国家文字、标 https://darkathena.blog.csdn.net/article/details/122659532?spm=1001.2014.3001.5502 |
| LINK:https://ask.csdn.net/questions/7704091?answer=53773173 |
| SOURCE:CSDN_ASK |
| ASK_ID:7700849 |
| ANSWER_ID:53768369 |
| TITLE:MySQL分组求结果未全部输出 |
ANSWER:select的非聚合函数字段,都要放到group by 后面 |
| LINK:https://ask.csdn.net/questions/7700849?answer=53768369 |
| SOURCE:CSDN_ASK |
| ASK_ID:7700295 |
| ANSWER_ID:53767814 |
| TITLE:SQL如何获取月汇总数据和年汇总数据? |
| ANSWER: 请说明一下你用的是什么数据库,以及数据库版本,还有你这个日期字段的数据类型是什么。 把下面where条件中指定的这个日期替换成你的变量即可
用dateadd函数计算,减一年,就是去年当日 然后拿这个去年当日,套用上面的方法,可得去年当日的当月 同理,拿今年的年初 convert(char(4),year('2022-04-24'))+'0101' 减1年,就能得去年的年初 当然也可以用上面计算年初的方式,传入去年当日 dateAdd(year,-1,'2022-04-24') 日期计算这玩意就是层层套娃,只要知道几个基本的函数,转换加减就行了 |
| LINK:https://ask.csdn.net/questions/7700295?answer=53767814 |

| SOURCE:CSDN_ASK |
| ASK_ID:7700303 |
| ANSWER_ID:53767806 |
| TITLE:orcle中如何实现 excel countif(A:A,A1) |
| ANSWER: 如果是要得到去重后的结果并且显示每个值有多少条相同的记录,直接用count 如果是想保留原始记录行数,新增一列显示本行的这个值有多少个相同的值,用开窗函数count |
| LINK:https://ask.csdn.net/questions/7700303?answer=53767806 |
| SOURCE:CSDN_ASK |
| ASK_ID:7700356 |
| ANSWER_ID:53767800 |
| TITLE:ORACLE DEVELOPER 对标量参数赋多个值 |
| ANSWER: xmltype是一种类型,而不是值,要打开后才能看到里面的数据,或者转换类型来直接显示,比如用to_number转换成数字显示
另外再给你几种方式
|
| LINK:https://ask.csdn.net/questions/7700356?answer=53767800 |



| SOURCE:CSDN_ASK |
| ASK_ID:7700024 |
| ANSWER_ID:53767368 |
| TITLE:SQL创建表,出现参数或变量:不能对数据类型bit指定列宽 |
| ANSWER: bit表示 一个二进制数字,只能为0或者1,所以不能定义长度,也不能放除0或1或null以外的值。 |
| LINK:https://ask.csdn.net/questions/7700024?answer=53767368 |
| SOURCE:CSDN_ASK |
| ASK_ID:7699700 |
| ANSWER_ID:53767361 |
| TITLE:以下mysql查询语句如何建立索引? |
| ANSWER: 还需要了解一下A/B/C三个字段的值的分布,比如去重后只有两个值的,或者每个值都不一样的,还有一半的值一样另一半的值都不一样。。。等等不同情况,需要结合这些值的情况,包括你数据的增删改场景,才能综合判断该如何建索引。 |
| LINK:https://ask.csdn.net/questions/7699700?answer=53767361 |
| SOURCE:CSDN_ASK |
| ASK_ID:7699703 |
| ANSWER_ID:53767358 |
| TITLE:oracle把一行拆分成多行,数据是1-18或者9-18这种组合。 |
| ANSWER: 提sql题建议把表结构和模拟数据发出来,纯文字描述不一定描述得清楚,而且答题人还要自行去编写create table和insert语句,很浪费时间,这样就几乎没人会理你这种提问方式了。
下面是将字符串'1-18周'拆成1-18的这18行的方式
|
| LINK:https://ask.csdn.net/questions/7699703?answer=53767358 |


| SOURCE:CSDN_ASK |
| ASK_ID:7699705 |
| ANSWER_ID:53767349 |
| TITLE:【Mysql 多表关联优化】 |
| ANSWER: 建议把背景描述一下,看看是个什么需求,具体问题具体分析,不能一上来就好像必须要进行大表join。 你想一下,join之后,难道就把这几十万都输出到前端展现么?难道前端或者用户不会先指定查询条件?如果有指定查询条件的话,就不再需要对全部的数据去进行join了呀。当你第一个表把数据过滤掉了绝大部分,再去左关联其他表,也就只会去找剩下的这几行。 |
| LINK:https://ask.csdn.net/questions/7699705?answer=53767349 |
| SOURCE:CSDN_ASK |
| ASK_ID:7699823 |
| ANSWER_ID:53767344 |
| TITLE:mysql RLIKE和LIKE会使用索引吗 |
| ANSWER: 不能只看sql的,同一个sql,表的索引建的方式或者索引类型不一样,可能会出现不同的情况,实际还是要看执行计划。 |
| LINK:https://ask.csdn.net/questions/7699823?answer=53767344 |
| SOURCE:CSDN_ASK |
| ASK_ID:7699333 |
| ANSWER_ID:53766923 |
| TITLE:sql server储存过程:超多表按关键字段合并成新表 |
| ANSWER: 表不多的话,直接join就行了,但你这要200个表一起的话,join性能就抗不住了,需要分批join。 |
| LINK:https://ask.csdn.net/questions/7699333?answer=53766923 |
| SOURCE:CSDN_ASK |
| ASK_ID:7699430 |
| ANSWER_ID:53766921 |
| TITLE:前两个表怎样的SQL语句可以变成第三个表啊? |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7699430?answer=53766921 |
| SOURCE:CSDN_ASK |
| ASK_ID:7699293 |
| ANSWER_ID:53766676 |
| TITLE:Microsoft Access定义表为什么会显示语法错误 |
| ANSWER: 字段间要有逗号间隔 |
| LINK:https://ask.csdn.net/questions/7699293?answer=53766676 |
| SOURCE:CSDN_ASK |
| ASK_ID:7698719 |
| ANSWER_ID:53766675 |
| TITLE:SQL如何在表中插入聚合语句 |
| ANSWER: 能给个报错截图么? |
| LINK:https://ask.csdn.net/questions/7698719?answer=53766675 |
| SOURCE:CSDN_ASK |
| ASK_ID:7699198 |
| ANSWER_ID:53766674 |
| TITLE:数据库删除和保留问题 |
| ANSWER: 不确定你机器配置怎么样,如果性能不行,就写过程分批处理; |
| LINK:https://ask.csdn.net/questions/7699198?answer=53766674 |
| SOURCE:CSDN_ASK |
| ASK_ID:7698041 |
| ANSWER_ID:53766673 |
| TITLE:MySQL同样是WHERE关键字 为什么一个报错一个正确? |
| ANSWER: 因为你"NOT(employee_id"这个中间的括号是全角的,导致把这一串都当成一个字段了, |
| LINK:https://ask.csdn.net/questions/7698041?answer=53766673 |
| SOURCE:CSDN_ASK |
| ASK_ID:7698465 |
| ANSWER_ID:53766672 |
| TITLE:sql语句的问题,不知道能否达到这种效果 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7698465?answer=53766672 |
| SOURCE:CSDN_ASK |
| ASK_ID:7698502 |
| ANSWER_ID:53766670 |
| TITLE:oracle存储过程编写,请专家指导 |
| ANSWER: 题目里没写字段类型,自己改下 |
| LINK:https://ask.csdn.net/questions/7698502?answer=53766670 |
| SOURCE:CSDN_ASK |
| ASK_ID:7698717 |
| ANSWER_ID:53766668 |
| TITLE:mysql5.7 使用json_extract 没有数据,是什么情况? |
| ANSWER: 因为你这个json是个列表(以"["开头,以"]"结尾),所以你定位的路径不对,要先取这个列表中的第一个元素,然后再往下找imageUrl。
或者先把"[]"去掉,再用你写的这个来定位
|
| LINK:https://ask.csdn.net/questions/7698717?answer=53766668 |


| SOURCE:CSDN_ASK |
| ASK_ID:7699200 |
| ANSWER_ID:53766664 |
| TITLE:access 礼貌提问 |
| ANSWER: 在select 后面加上 top 3即可,比如 |
| LINK:https://ask.csdn.net/questions/7699200?answer=53766664 |
| SOURCE:CSDN_ASK |
| ASK_ID:7698006 |
| ANSWER_ID:53765514 |
| TITLE:如何动态的将mysql行转列 |
| ANSWER: 纯select的sql是不能实现动态列的,sql必须在查询发出前就已经确定好有哪些列,包括列名和数据类型,这与sql解析器本身的逻辑有关。 |
| LINK:https://ask.csdn.net/questions/7698006?answer=53765514 |
| SOURCE:CSDN_ASK |
| ASK_ID:7698132 |
| ANSWER_ID:53765427 |
| TITLE:LISTAGG行转列查询缓慢 |
| ANSWER: F5执行计划贴一下,然后如果把LISTAGG这个列改成简单的count,时间消耗差异有多大? |
| LINK:https://ask.csdn.net/questions/7698132?answer=53765427 |
| SOURCE:CSDN_ASK |
| ASK_ID:7698084 |
| ANSWER_ID:53765325 |
| TITLE:mysql select比limit先执行,那为什么加了limit的sql比查全部数据的sql执行更快? |
| ANSWER: 把数据读出来,通过网络传输到客户端内存,再由客户端把数据页面渲染出来,这些总得消耗时间吧 |
| LINK:https://ask.csdn.net/questions/7698084?answer=53765325 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697650 |
| ANSWER_ID:53765145 |
| TITLE:导入sql文件,sql报错1064 |
| ANSWER: 建议你用记事本打开一下这个sql文件看看,这玩意看上去不是纯sql文件,报错信息里还有sqlite的字样 |
| LINK:https://ask.csdn.net/questions/7697650?answer=53765145 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697662 |
| ANSWER_ID:53765140 |
| TITLE:sqlserver 如何查询的同时并删除这行 |
| ANSWER: 查询是为了输出数据,如果只是为了删除,那么你加where条件直接删除这条数据就行了,没必要再去查询它 |
| LINK:https://ask.csdn.net/questions/7697662?answer=53765140 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697709 |
| ANSWER_ID:53765139 |
| TITLE:感觉语法没有错误,怎么改 |
| ANSWER: 为啥子下面执行的显示是没加引号? |
| LINK:https://ask.csdn.net/questions/7697709?answer=53765139 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697879 |
| ANSWER_ID:53765125 |
| TITLE:请问一下这种表结构是啥意思? |
| ANSWER: 图能不能截全点?看不出你这是一个表的字段内容还是别的什么东西。 我见过不少数据库了,你这个真碰到我的盲区了,我竟然一时看不出这是啥子数据库。但是根据单词来分析,word应该是一种文本类型 类似于char;second应该是一种时间类型,而且很有可能是以秒为单位。至于asc,就可能要结合一下数据来看了,不确定是指的ascii还是指的排序中的asc,如果是排序中的asc,那么它就有可能是数字类型。 |
| LINK:https://ask.csdn.net/questions/7697879?answer=53765125 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697895 |
| ANSWER_ID:53765122 |
| TITLE:SQL 判断case when |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7697895?answer=53765122 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697917 |
| ANSWER_ID:53765115 |
| TITLE:从字符串转换日期和/或时间时,转换失败 |
| ANSWER: 贴一下你这个表的表结构,不确定你的日期是哪个字段; |
| LINK:https://ask.csdn.net/questions/7697917?answer=53765115 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697386 |
| ANSWER_ID:53764562 |
| TITLE:关于order by 和group by 的约束问题 |
| ANSWER: 在sql标准中,select后面的非聚合函数字段,必须都放到group by后面去。只有老版本的mysql没这个要求,因而会出现查询出来的数据出现随机性。其他数据库以及mysql8.0开始都是严格执行sql标准。 |
| LINK:https://ask.csdn.net/questions/7697386?answer=53764562 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697462 |
| ANSWER_ID:53764553 |
| TITLE:想要修改Windows主机里面hosts文件没有权限怎么办 |
| ANSWER: 鼠标右键此文件,点属性-安全,添加你的电脑用户名,勾上完全控制的权限,确定,之后就能自由修改了。 |
| LINK:https://ask.csdn.net/questions/7697462?answer=53764553 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697321 |
| ANSWER_ID:53764261 |
| TITLE:为什么over后面的半括号会有红线然后报错1064啊 |
| ANSWER: 请检查你的mysql版本号,开窗函数要8.0及之后才支持 |
| LINK:https://ask.csdn.net/questions/7697321?answer=53764261 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697268 |
| ANSWER_ID:53764260 |
| TITLE:求请教:ORACLE 按日期求最后一次销价,日期字段是VARCHAR |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7697268?answer=53764260 |
| SOURCE:CSDN_ASK |
| ASK_ID:7697242 |
| ANSWER_ID:53764249 |
| TITLE:打开data studio 报错怎么办 |
| ANSWER: 要安装个java 1.8,并配置好java_home的环境变量 |
| LINK:https://ask.csdn.net/questions/7697242?answer=53764249 |
| SOURCE:CSDN_ASK |
| ASK_ID:7696960 |
| ANSWER_ID:53763884 |
| TITLE:sql语句表的别名问题,第二个sql省略了 子select 的表名 |
| ANSWER: 表的别名不能接在from后面。 或者 如果数据都能匹配上的话,还可以这么写 如果要多次使用某个表,可以使用with,例如 |
| LINK:https://ask.csdn.net/questions/7696960?answer=53763884 |
| SOURCE:CSDN_ASK |
| ASK_ID:7696361 |
| ANSWER_ID:53763043 |
| TITLE:请问做网页开发mongodb能完全代替mysql吗? |
| ANSWER: 不能,两者根本不是一个类型的数据库。 |
| LINK:https://ask.csdn.net/questions/7696361?answer=53763043 |
| SOURCE:CSDN_ASK |
| ASK_ID:7694774 |
| ANSWER_ID:53763001 |
| TITLE:问一个sql中的group by问题 |
| ANSWER: group by后面不要带别名,select了啥就group by啥(除了聚合函数字段) |
| LINK:https://ask.csdn.net/questions/7694774?answer=53763001 |
| SOURCE:CSDN_ASK |
| ASK_ID:7694945 |
| ANSWER_ID:53762993 |
| TITLE:mysql查询数据的时候,怎么把缺少的日期补齐 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7694945?answer=53762993 |


| SOURCE:CSDN_ASK |
| ASK_ID:7695713 |
| ANSWER_ID:53762952 |
| TITLE:SQL怎样统计一段日期范围内每天晚上20:00到次日早上8:00所有的数据? |
| ANSWER: 不同的数据库,时间处理函数不一样,但是思路是一样的,即让时间进行偏移,让两个时间点都落在一天内,就可以进行group by 了。 |
| LINK:https://ask.csdn.net/questions/7695713?answer=53762952 |
| SOURCE:CSDN_ASK |
| ASK_ID:7695891 |
| ANSWER_ID:53762904 |
| TITLE:MYSQL 的分页语句怎样转换成SQLserver的? |
| ANSWER: TOP (Transact-SQL) - SQL Server | Microsoft Docs TOP (Transact-SQL) https://docs.microsoft.com/zh-cn/sql/t-sql/queries/top-transact-sql?view=sql-server-ver15 在sqlserver2012后支持 OFFSET 和 FETCH ORDER BY 子句 (Transact-SQL) - SQL Server | Microsoft Docs SELECT - ORDER BY 子句 (Transact-SQL) https://docs.microsoft.com/zh-cn/sql/t-sql/queries/select-order-by-clause-transact-sql?view=sql-server-ver15 |
| LINK:https://ask.csdn.net/questions/7695891?answer=53762904 |
| SOURCE:CSDN_ASK |
| ASK_ID:7695998 |
| ANSWER_ID:53762896 |
| TITLE:动态sql语句中的表没有被dba_dependencies查询到 |
| ANSWER: 动态sql肯定是在dba_dependencies查不到的,因为动态sql就是个字符串文本而已,oracle在编译阶段不会对这些字符串进行任何校验,你想怎么拼接就可以怎么拼接,只有在执行到对应的execute immediate 的时候才会对动态sql的合法性进行校验,因此oracle无法提前知晓依赖关系。 比如这个例子,整个代码里不包含"dba_views",但实际上查的又是“dba_views”这个视图,如果把参数c的值换成别的,同样的代码查询的又是不同的视图了 |
| LINK:https://ask.csdn.net/questions/7695998?answer=53762896 |
| SOURCE:CSDN_ASK |
| ASK_ID:7696134 |
| ANSWER_ID:53762881 |
| TITLE:sql语句获取数据库最大时间,求范围 |
| ANSWER: 你这个sql逻辑不对,语法也不对。 |
| LINK:https://ask.csdn.net/questions/7696134?answer=53762881 |
| SOURCE:CSDN_ASK |
| ASK_ID:7696145 |
| ANSWER_ID:53762875 |
| TITLE:好奇set语句的底层原理实现 |
| ANSWER: 底层处理是没有"年龄"概念的,你这个操作就是简单的把一个数字加1,然后更新(update)到这个字段上而已。再底层一点,就得扯到二进制上去了。 |
| LINK:https://ask.csdn.net/questions/7696145?answer=53762875 |
| SOURCE:CSDN_ASK |
| ASK_ID:7696190 |
| ANSWER_ID:53762862 |
| TITLE:MySQL 数据库疑问 查询学生平均分大于60的结果 |
| ANSWER: 第一条sql中的子查询,查出来的是12个不同的值,而不是行记录,然后再从sc表里去找满足这12个值的行记录,可以找到有37行(等同于 in ('11111','2222','3333','4444','5555',.....))。 |
| LINK:https://ask.csdn.net/questions/7696190?answer=53762862 |
| SOURCE:CSDN_ASK |
| ASK_ID:7696065 |
| ANSWER_ID:53762766 |
| TITLE:sqlserver 今天收到一个奇怪的需求 想大家提供我点思路 |
| ANSWER: 使用开窗函数的滑动窗口即可 【ORACLE】谈一谈分析函数(窗口函数)的前世今生-那些可能不为人知的事_DarkAthena的博客-CSDN博客 一、前言经常写报表sql的小伙伴,应该都知道"分析函数"这一强大的功能,常见用法比如 取分组TOP-N、滚动求和、取当前行的上(下)N行等等。不过本篇不会再对这些常见基础用法进行介绍,只会说说那些关于"分析函数"可能不被人注意的事。二、最早使用分析函数的数据库有文章里说过,分析函数最早是在ORACLE8.1.6中出现的,我翻了下8.1.6和8.0的文档,发现的确如此(8.1.5版本文档已被移除,暂无法确认)而ORACLE8.1.6是在1999年11月发布的,因此早在二十多年前(此文创作日期为2022 https://darkathena.blog.csdn.net/article/details/123701128?spm=1001.2014.3001.5502 sqlserver2008还不支持开窗函数中用order by,至少要到sqlserver2012. |
| LINK:https://ask.csdn.net/questions/7696065?answer=53762766 |
| SOURCE:CSDN_ASK |
| ASK_ID:7694551 |
| ANSWER_ID:53761686 |
| TITLE:Oracle 存储过程 无法执行 |
| ANSWER: 只有在命令行里才能用exec命令来执行存储过程,在sql窗口中一般都是用下面这种方式来执行的 |
| LINK:https://ask.csdn.net/questions/7694551?answer=53761686 |
| SOURCE:CSDN_ASK |
| ASK_ID:7694843 |
| ANSWER_ID:53761680 |
| TITLE:clickhouse中查询某值每次变化的时间 |
| ANSWER: clickehouse支持窗口函数,可以使用lag配合sum来获取变化的位置 大概像下面这样,我这里没数据环境不好测试。 原理就是上一行和当前行相等时计为0,不等时计为1,然后使用滑动窗口求和,就能在每次数据变化的时候加1,这样就能把数据按顺序切分开了,再按这个字段group by,就可以取每组最大和最小的时间 |
| LINK:https://ask.csdn.net/questions/7694843?answer=53761680 |
| SOURCE:CSDN_ASK |
| ASK_ID:7695347 |
| ANSWER_ID:53761672 |
| TITLE:Mysql用source导入sql文件老是显示,unknown command '\b'.,用了帖子里大家说的解决办法还是不行,我是不是命令没输正确,刚开始自学,确实没办法了,鞠躬解答 |
| ANSWER: 你的sql文件里有"\b"这个东西,不符合sql语法,无法识别 |
| LINK:https://ask.csdn.net/questions/7695347?answer=53761672 |
| SOURCE:CSDN_ASK |
| ASK_ID:7695090 |
| ANSWER_ID:53761667 |
| TITLE:这是个MYSQL里的条件函数,我想用Oracle的写法,但是都没有成功!不知道哪里有问题? |
| ANSWER: group by 后面把select的非聚合函数的字段或表达式放进去就行了,你这里是select的case when,那么group by后面也要有同样的case when |
| LINK:https://ask.csdn.net/questions/7695090?answer=53761667 |
| SOURCE:CSDN_ASK |
| ASK_ID:7691782 |
| ANSWER_ID:53760580 |
| TITLE:Oracle 在视图对象中看不见视图,但用select语句可查询到视图数据 |
| ANSWER: 有以下几种可能
|
| LINK:https://ask.csdn.net/questions/7691782?answer=53760580 |
| SOURCE:CSDN_ASK |
| ASK_ID:7691864 |
| ANSWER_ID:53760575 |
| TITLE:Oracle表关联发散 |
| ANSWER: 因为你没写几个表之间的关联条件,导致产生了笛卡尔积,一个表的每一行都可以和另一个表的每一行匹配。正常的表关联应该类似下面这样 |
| LINK:https://ask.csdn.net/questions/7691864?answer=53760575 |
| SOURCE:CSDN_ASK |
| ASK_ID:7692090 |
| ANSWER_ID:53760560 |
| TITLE:下面这段SQL能否用索引优化查询性能 |
| ANSWER: 建议用having替代where条件,减少一层嵌套。然后建议用join替代这个exists条件。因为很明显里面的这个sql才应该是主驱动表,条件都是基于b表的,应该先确定要查哪些cst_id后,再用这些cst_id查a表。而不是针对a表的每一行去查哪些cst_id满足条件 |
| LINK:https://ask.csdn.net/questions/7692090?answer=53760560 |
| SOURCE:CSDN_ASK |
| ASK_ID:7693402 |
| ANSWER_ID:53760513 |
| TITLE:如何完成多表的字段统一 |
| ANSWER: 题主没说明是想改表结构还是说在sql语法代码上进行兼容。如果是改表结构,这对之前的程序逻辑会有影响可能会需要大量调整程序逻辑。如果是改sql,只要用函数to_number转换一下这个字段就行了 |
| LINK:https://ask.csdn.net/questions/7693402?answer=53760513 |
| SOURCE:CSDN_ASK |
| ASK_ID:7693668 |
| ANSWER_ID:53760507 |
| TITLE:mysql创建的视图查询却是空的怎么办? |
| ANSWER: 先单独查xs表,并写条件 xs.专业名='计算机',看能不能查到记录。如果能查到,再随便取一个学号,单独查xs_kc表,看找不找得到记录。 |
| LINK:https://ask.csdn.net/questions/7693668?answer=53760507 |
| SOURCE:CSDN_ASK |
| ASK_ID:7693703 |
| ANSWER_ID:53760501 |
| TITLE:MySQL数据case when查询怎么将0的数据显示出来 |
| ANSWER: 如果你表里面本就没有对应的数据,是count不出一条新的记录的。此时可以多次查询然后再union all或者分成不同的字段查询再进行行列转换 |
| LINK:https://ask.csdn.net/questions/7693703?answer=53760501 |
| SOURCE:CSDN_ASK |
| ASK_ID:7694127 |
| ANSWER_ID:53760480 |
| TITLE:请问,为什么sql里面的least() 函数用不了? |
| ANSWER: 不同数据库支持的函数是有区别的,least函数在mysql和oracle中是支持的,在sqlserver中不支持 |
| LINK:https://ask.csdn.net/questions/7694127?answer=53760480 |
| SOURCE:CSDN_ASK |
| ASK_ID:7694200 |
| ANSWER_ID:53760472 |
| TITLE:视图中会使用基表的索引吗 |
| ANSWER: 这个建议查看一下执行计划,可能会使用也可能不会使用,这个要看数据库本身的优化。会使用时,说明数据库自动进行了谓词内推 |
| LINK:https://ask.csdn.net/questions/7694200?answer=53760472 |
| SOURCE:CSDN_ASK |
| ASK_ID:7694362 |
| ANSWER_ID:53760462 |
| TITLE:SQL数据库查询order by排序问题DATE类型和TIME类型字段排序 |
| ANSWER: sqlserver不支持limit语法,请使用top语法或者开窗函数row_number FIREBIRD常用SQL - 走看看 一、分页写法小例: select first 10 templateid,code,name from template ; select first 10 skip 10 templateid,co http://t.zoukankan.com/top5-p-1433010.html |
| LINK:https://ask.csdn.net/questions/7694362?answer=53760462 |
| SOURCE:CSDN_ASK |
| ASK_ID:7694427 |
| ANSWER_ID:53760459 |
| TITLE:想要实现一个批量提交作(zuo)业题(mu)目,应该怎么在数据库中识别这次提交的ti’mu有哪些方便我下次渲染?怎么给该次提交一个唯一标识 |
| ANSWER: 数据库里建两个表,一个记录批次,每行为一个批次,有主键id作为批次id,然后第二个表记录题目明细,并记录对应的批次id。然后页面上可以显示批次id列表或者可以指定批次id查询题目明细 |
| LINK:https://ask.csdn.net/questions/7694427?answer=53760459 |
| SOURCE:CSDN_ASK |
| ASK_ID:7688676 |
| ANSWER_ID:53753845 |
| TITLE:子查询作为表时,表外加条件查询效率特别慢。 |
| ANSWER: 你这sql和下面这个貌似是等价的 其实效率点应该先考虑一下这个TIME_TO_MARKET自定义函数,毕竟这玩意要作为条件使用,看能不能把逻辑拆开,放到sql里 |
| LINK:https://ask.csdn.net/questions/7688676?answer=53753845 |
| SOURCE:CSDN_ASK |
| ASK_ID:7688169 |
| ANSWER_ID:53753293 |
| TITLE:SQL 查找用户的疑似小号 |
| ANSWER: 直接把所有帖子按顺序拼成一个字符串,再判断和wang的是否相等即可 |
| LINK:https://ask.csdn.net/questions/7688169?answer=53753293 |
| SOURCE:CSDN_ASK |
| ASK_ID:7688216 |
| ANSWER_ID:53753279 |
| TITLE:mysql Navicat软件[Err]1055错误 |
ANSWER:改完后重启数据库。 |
| LINK:https://ask.csdn.net/questions/7688216?answer=53753279 |
| SOURCE:CSDN_ASK |
| ASK_ID:7688262 |
| ANSWER_ID:53753252 |
| TITLE:出现这种错误是怎么回事啊 |
| ANSWER: 你这是sql里的变量没替换掉吧,数据库抛出的语法错误提示你执行的sql长这样
这当然不能执行呀,你得把具体的表名字段名还有where条件放进去 |
| LINK:https://ask.csdn.net/questions/7688262?answer=53753252 |

| SOURCE:CSDN_ASK |
| ASK_ID:7688317 |
| ANSWER_ID:53753251 |
| TITLE:用oracle数据库,查询起始月到当前月的销售环比,求环比=(本月-上月)/上月 |
| ANSWER: 最容易的写法就一个自关联了,注意除数为0的特殊处理 如果不用自关联,只对这个表查一次,可以使用开窗函数,这里先假设数据中间不会存在月份缺失 如果好巧不巧,刚好关门了一个月而且没插入对应月份的数据,那么也还是可以使用开窗函数,不过要换成range滑动窗口了 在数据完整的情况下,上述3个sql输出结果都是一样的 |
| LINK:https://ask.csdn.net/questions/7688317?answer=53753251 |
| SOURCE:CSDN_ASK |
| ASK_ID:7688367 |
| ANSWER_ID:53753227 |
| TITLE:SQL serve 2008建表往表填数据为什么会出现这种情况 |
| ANSWER: 你这个表上建了个外键,要求在这个表里的cpno必须来自于这个表里的cno, 我觉得很奇怪了,搜你这个错能发现一大堆一模一样的,连表名和字段名都一样,甚至连插入的数据都一模一样,你们是不是看了同一本教程 INSERT 语句与 FOREIGN KEY SAME TABLE 约束"FK__Course__Cpno__060DEAE8"冲突。_百度知道 https://zhidao.baidu.com/question/521154474.html 这时间跨度都已经有十年了。。。 |
| LINK:https://ask.csdn.net/questions/7688367?answer=53753227 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687909 |
| ANSWER_ID:53752782 |
| TITLE:在Oracle中数据转换问题,如何批量将字符串中的字母转化为特定数字 |
| ANSWER: 可以用translate函数
第1个参数为原字符串,第2个参数和第3个参数,按字符位置匹配对应的转换关系,比如a转换成1,b转换成2。
select 的函数只能返回一个字段 ,比如 select Replaceletter('jk') from dual, 建议你还是把原始需求描述一下,可能有其他解决方式,你要求的这种转换目前看上去很不合常理。 |
| LINK:https://ask.csdn.net/questions/7687909?answer=53752782 |


| SOURCE:CSDN_ASK |
| ASK_ID:7687627 |
| ANSWER_ID:53752755 |
| TITLE:oracle使用left join的查询 |
| ANSWER: 本来就是要获取两个字段,而且是提取不同行的数据,当然要关联两次,要么join,要么标量子查询 标量子查询的上面那位已经给了。 |
| LINK:https://ask.csdn.net/questions/7687627?answer=53752755 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687629 |
| ANSWER_ID:53752706 |
| TITLE:oracle的一个sql问题 |
| ANSWER: 这题要求的是取对应的记录,简单的聚合函数会导致丢失一些列,比如上面的回答就丢了id和type。 |
| LINK:https://ask.csdn.net/questions/7687629?answer=53752706 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687653 |
| ANSWER_ID:53752699 |
| TITLE:MySQL 字段内容按条件提取数据 |
| ANSWER: 不确定你的空时null还是空字符串,先假设是null
如果,实测如果空值是null的话,group_concat并不会造成数据里有多余分隔符,所以如果你的数据是空字符串,那么可以在最内层select的时候,用case when转换成null |
| LINK:https://ask.csdn.net/questions/7687653?answer=53752699 |

| SOURCE:CSDN_ASK |
| ASK_ID:7687746 |
| ANSWER_ID:53752634 |
| TITLE:sql进行周期数据查询 |
| ANSWER: 这用上一题的答案稍微改一下不就出来了?
Introduction | ClickHouse Documentation Functions There are at least* two types of functions - regular functions (they are just called “functions”) and aggregat https://clickhouse.com/docs/en/sql-reference/functions/ |
| LINK:https://ask.csdn.net/questions/7687746?answer=53752634 |

| SOURCE:CSDN_ASK |
| ASK_ID:7687761 |
| ANSWER_ID:53752598 |
| TITLE:sql 中exists的作用,他的优点和好处 |
| ANSWER: exists常见于两处语法位置,
|
| LINK:https://ask.csdn.net/questions/7687761?answer=53752598 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687841 |
| ANSWER_ID:53752578 |
| TITLE:mysql5.7,sql语句查询太慢,用EXISTS代替in报错 |
| ANSWER: 你那条exists的sql应该像下面这样,语法才是正确的 |
| LINK:https://ask.csdn.net/questions/7687841?answer=53752578 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687341 |
| ANSWER_ID:53751829 |
| TITLE:sql数据库怎么直接用代码创建啊,看我列子 |
ANSWER:
这一句表示创建一个schema(或者叫一个模式、架构、有时也叫一个库),这个schema的名称定为test,然后授权 zhang 这个用户 如果你要建表,在连接到对应的schema后,直接执行你下面的create table 命令就行了。 你想给哪个用户就可以给哪个用户,前提是该用户在数据库中存在 |
| LINK:https://ask.csdn.net/questions/7687341?answer=53751829 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687332 |
| ANSWER_ID:53751821 |
| TITLE:substring , |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7687332?answer=53751821 |

| SOURCE:CSDN_ASK |
| ASK_ID:7687247 |
| ANSWER_ID:53751814 |
| TITLE:Windows查看CUDA版本的时候出错 |
| ANSWER: 先确认是否已正确安装CUDA,然后检查path环境变量是否包含对应的路径, nvcc --version: nvcc不是内部或外部命令 - it610.com 首先,有两种可能:首先确定自己是否安装了CUDA,CUDA本身是一个工具包,需要自己下载;如果确定已经安装过CUDA,那可能是没有配置环境变量(安装后发现安装CUDA本身就会更新环境变量,在安装路径中cmd打开nvcc不会报错,但是在其它路径下会报错,这就要考虑是否是环境变量path没有更新)解决方法:在系统变量path中,双击,点击新建:添加两个路径:C:\ProgramFiles\NVIDIA https://www.it610.com/article/1296857012767891456.htm |
| LINK:https://ask.csdn.net/questions/7687247?answer=53751814 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687190 |
| ANSWER_ID:53751770 |
| TITLE:使用BAT怎么实现把txt的文件内容更新到另一个文件的特定字段中? |
| ANSWER: 你这两个文件是都只有一行记录?还是说文件1只有一行,但文件2有多行?
如果一行有2个参数,只替换其中一个参数,用下面这个 执行效果
|
| LINK:https://ask.csdn.net/questions/7687190?answer=53751770 |


| SOURCE:CSDN_ASK |
| ASK_ID:7687191 |
| ANSWER_ID:53751767 |
| TITLE:java代码执行sql脚本问题 |
| ANSWER: 把你怎么在java里执行的,以及报错信息发出来 报错提示是存在语法错误就肯定是有语法错误, |
| LINK:https://ask.csdn.net/questions/7687191?answer=53751767 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687106 |
| ANSWER_ID:53751627 |
| TITLE:数据库SQL和组态王连接成功,但是往数据库传不进数据 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7687106?answer=53751627 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687009 |
| ANSWER_ID:53751579 |
| TITLE:提问:SQL数据库:查询没有选课的学生信息 |
| ANSWER: 因为你班级表和学生表没有关联起来,造成了笛卡尔积,每个学生都分配到了所有班级。加上关联条件就没问题了 |
| LINK:https://ask.csdn.net/questions/7687009?answer=53751579 |
| SOURCE:CSDN_ASK |
| ASK_ID:7687002 |
| ANSWER_ID:53751576 |
| TITLE:已知时间序列的特征,可以利用这些特征还原数据或者生成新的数据吗? |
| ANSWER: 给你一个简单的例子吧
上面这个就是输入一组x和y的数据,拟合了一个函数模型,然后就能输入x返回对应的y值了 你说说什么叫做规律?什么叫做原样本的特征?特征不就是规律么?你能把这些特征都量化下来么?如果特征无法量化,那如何判断是符合原样本特征呢?如果特征都量化了,那不就是一个函数模型么? 这个例子可不只是一个缺失值,按照这种方式,你可以选择对应的2次函数或更多次函数(即函数图像为曲线),让机器学习自动帮你把各次项系数算出来. |
| LINK:https://ask.csdn.net/questions/7687002?answer=53751576 |

| SOURCE:CSDN_ASK |
| ASK_ID:7686970 |
| ANSWER_ID:53751562 |
| TITLE:mac下navicat 导入00000001数据列时提示Error Message: Out of range value for column |
| ANSWER: 你图上提示已处理28,错误1,也就是说明你这个表有29行数据,其中有28行长度是没问题的,有一行的长度是有问题的,这个时候你就应该去看一下是哪一行超长 |
| LINK:https://ask.csdn.net/questions/7686970?answer=53751562 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686930 |
| ANSWER_ID:53751478 |
| TITLE:SQLSTATE[HY000] [1045] Access denied for user 'root'@'localhost' (using password: NO) |
ANSWER:
可以尝试带密码登录 |
| LINK:https://ask.csdn.net/questions/7686930?answer=53751478 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686693 |
| ANSWER_ID:53751474 |
| TITLE:如何禁止双系统文件互通 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7686693?answer=53751474 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686694 |
| ANSWER_ID:53751463 |
| TITLE:mysql中出现这个问题是因为什么 |
| ANSWER: 你表里面当前是否存在不满足这个约束的数据? 如果是让这个字段至少要有1个数字,可以使用正则函数
|
| LINK:https://ask.csdn.net/questions/7686694?answer=53751463 |

| SOURCE:CSDN_ASK |
| ASK_ID:7686737 |
| ANSWER_ID:53751461 |
| TITLE:sql语句的问题,不同出版社的平均评分怎么写 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7686737?answer=53751461 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686740 |
| ANSWER_ID:53751460 |
| TITLE:关于sql语句的问题,mysql5.7.我想要找到不同的价格区间的平均评分! |
| ANSWER: 这个要看你的区间是等距区间还是自定义灵活区间
你要评分的平均值,把avg函数后面的字段换成评分就行了 |
| LINK:https://ask.csdn.net/questions/7686740?answer=53751460 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686611 |
| ANSWER_ID:53751111 |
| TITLE:MYSQL查询主从表时,主表的数量字段怎么只显示一次,明细表可以有多行 |
| ANSWER: 咨询sql题,请说明数据库类型、版本,提供对应的原始数据建表sql及insert数据sql,以及用表格形式说明一下最终需要的数据的格式。 如果是支持开窗函数的数据库,那么可以把 改成 然后sql的最后还要加上order by |
| LINK:https://ask.csdn.net/questions/7686611?answer=53751111 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686375 |
| ANSWER_ID:53751101 |
| TITLE:Windows任务计划怎么同时运行多个定时计划 |
| ANSWER: 新建一个bat文件,把你要运行的bat文件名都写进去,每个文件前面加start,比如 然后就只用执行这一个bat文件了。 |
| LINK:https://ask.csdn.net/questions/7686375?answer=53751101 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686533 |
| ANSWER_ID:53751094 |
| TITLE:exists关键字是干什么用的?怎么用 |
| ANSWER: exists ,直接翻译成中文就是"存在",你这个例子里面就是查询如果"存在"数据就执行查询,否则打印一段文字 |
| LINK:https://ask.csdn.net/questions/7686533?answer=53751094 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686253 |
| ANSWER_ID:53750804 |
| TITLE:md格式文件用什么软件打开 |
| ANSWER: md文件其实就是一个纯文本文件,用任意文本编辑工具都可以打开。 |
| LINK:https://ask.csdn.net/questions/7686253?answer=53750804 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686240 |
| ANSWER_ID:53750751 |
| TITLE:mysql8日期不能设置CURRENT_TIMESTAMP,怎么解决 |
| ANSWER: datetime后面不要加长度
|
| LINK:https://ask.csdn.net/questions/7686240?answer=53750751 |

| SOURCE:CSDN_ASK |
| ASK_ID:7686149 |
| ANSWER_ID:53750732 |
| TITLE:中国植被类型分布有哪些 |
| ANSWER: 中国植被区划数据-植被数据-自然地理数据-数据目录-北京大学城市与环境学院 [v1.0.0] 中国植被区划数据来源于1:100万植被图 https://geodata.pku.edu.cn/index.php?c=content&a=show&id=868 |
| LINK:https://ask.csdn.net/questions/7686149?answer=53750732 |
| SOURCE:CSDN_ASK |
| ASK_ID:7686165 |
| ANSWER_ID:53750717 |
| TITLE:创建数据库表使用CONSTRAINT关键字时出错 |
| ANSWER: 目前官网已经查不到5.5的文档了,最早的5.7版本文档中对check是这么描述的
大概意思就是check语法可以被解析,但是会被忽略。这和你描述的现象一致。 |
| LINK:https://ask.csdn.net/questions/7686165?answer=53750717 |
| SOURCE:CSDN_ASK |
| ASK_ID:7685954 |
| ANSWER_ID:53750545 |
| TITLE:这个SQL语句结果怎么得出来的,朋友们能帮讲解一下吗 |
| ANSWER:
|
| LINK:https://ask.csdn.net/questions/7685954?answer=53750545 |

| SOURCE:CSDN_ASK |
| ASK_ID:7685803 |
| ANSWER_ID:53750233 |
| TITLE:请问字符串中的字典怎么整出来? |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7685803?answer=53750233 |

| SOURCE:CSDN_ASK |
| ASK_ID:7685787 |
| ANSWER_ID:53750210 |
| TITLE:sql组装成json字符串将+号之间识别为了字符串 |
| ANSWER: S.ENUM_CUTLEVEL 这个字段cast一下,转成varchar,估计你这个字段是个int类型,它就把这个加号当成了真正的加法,然后又发现前面这个参数无法转换成int,就报错了。建议把每个字段都cast一下,毕竟你这是在拼字符串 |
| LINK:https://ask.csdn.net/questions/7685787?answer=53750210 |
| SOURCE:CSDN_ASK |
| ASK_ID:7685688 |
| ANSWER_ID:53750183 |
| TITLE:服务项里面的sql代理无法启动导致数据库连接不到服务器 |
| ANSWER: 双击这个服务,看下它执行文件的路径。 |
| LINK:https://ask.csdn.net/questions/7685688?answer=53750183 |
| SOURCE:CSDN_ASK |
| ASK_ID:7685469 |
| ANSWER_ID:53749870 |
| TITLE:sql数据周期自动更新 |
| ANSWER: 先说下你用的什么数据库吧,这个是可以实现的,但不同数据库关于日期的计算方式不一样
原理就是先把要计算的日期加3天,然后toStartOfWeek获取这个日期对应星期的第一天(星期天),最后再减3天得星期四 |
| LINK:https://ask.csdn.net/questions/7685469?answer=53749870 |

| SOURCE:CSDN_ASK |
| ASK_ID:7685457 |
| ANSWER_ID:53749868 |
| TITLE:如题今天遇到奇怪的事情,劳驾帮看看吧 |
| ANSWER: 只能怀疑serial2里存在空格、回车或者不可见字符了,因为既不是NULL也不是空字符串,而且长度还大于0。 |
| LINK:https://ask.csdn.net/questions/7685457?answer=53749868 |
| SOURCE:CSDN_ASK |
| ASK_ID:7685440 |
| ANSWER_ID:53749857 |
| TITLE:MySQL初学者创建表的问题 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7685440?answer=53749857 |

| SOURCE:CSDN_ASK |
| ASK_ID:7685399 |
| ANSWER_ID:53749774 |
| TITLE:select语句怎么把两个相加的值赋值给一个字段 |
| ANSWER: 你的想法应该是tk_money+overdue_money 的结果的字段名为co_money,但却写成了一个函数用法,正确的写法应该是下面这样 当然这个括号可以不要 |
| LINK:https://ask.csdn.net/questions/7685399?answer=53749774 |
| SOURCE:CSDN_ASK |
| ASK_ID:7685400 |
| ANSWER_ID:53749773 |
| TITLE:用SQLSERVER写的要改成MYSQL代码复制后出现1146 - Table 'mysql.cte' doesn't exist |
| ANSWER: with 后面要加一个RECURSIVE,比如 注意,别的地方不要加这个东西,只要with后面加一个就行了 |
| LINK:https://ask.csdn.net/questions/7685400?answer=53749773 |
| SOURCE:CSDN_ASK |
| ASK_ID:7685329 |
| ANSWER_ID:53749662 |
| TITLE:关于按照机构、岗位、职位、用户组等维度灵活指定允许用户参与范围的设计 |
| ANSWER: 这个设计中,有一个很重要的场景,就是在发布问卷后,有新员工入职该公司,是否可以看到此份调查问卷。 问卷平均有效期多长? 两个极致,
|
| LINK:https://ask.csdn.net/questions/7685329?answer=53749662 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684892 |
| ANSWER_ID:53748970 |
| TITLE:MySQL,oracle:求客户月均市值=当月每天市值累加之和/当月天数 |
| ANSWER: 你是想问oracle里怎么写还是mysql里怎么写?这两个数据库支持的语法不一样。另外请给出数据库版本。 oracle里可以使用开窗函数lag获取上一行,并且支持通过加关键词的方法来实现获取上一行不为空的值,在这篇帖子里有类似的场景 以日历为主表,外关联持仓表,当本行市值为空时,获取上一个不为空的市值到本行,最后按月份求和除以天数就好了 |
| LINK:https://ask.csdn.net/questions/7684892?answer=53748970 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684827 |
| ANSWER_ID:53748968 |
| TITLE:sql中跑出账户1到账户6的所有路径 |
| ANSWER: 你题目里写错一行数据,坑了我一把。。。
应该为
你那个汇总转账金额不知道是不是指的每2个节点之间的转账都要先汇总,就是tt表里面那个sum |
| LINK:https://ask.csdn.net/questions/7684827?answer=53748968 |

| SOURCE:CSDN_ASK |
| ASK_ID:7684863 |
| ANSWER_ID:53748952 |
| TITLE:mysql8.0.28 用的是datagrip,用intersect求交集一直报错,提示语法错误,但是,实在没找到 |
| ANSWER: mysql 不支持intersect的语法,建议使用其他方式来实现,比如你这个sql完全可以写成 |
| LINK:https://ask.csdn.net/questions/7684863?answer=53748952 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684821 |
| ANSWER_ID:53748948 |
| TITLE:LeetCode:197. 上升的温度,这样写为什么不行 |
| ANSWER: mysql里不能直接用加减法来计算日期,如下
想象一下,4月30号加1天,理论上应该是5月1日,但是sql中如果直接加1,会得出4月31号,而且结果还不是日期类型了。 |
| LINK:https://ask.csdn.net/questions/7684821?answer=53748948 |

| SOURCE:CSDN_ASK |
| ASK_ID:7684815 |
| ANSWER_ID:53748944 |
| TITLE:SQL中datesdd的问题 |
| ANSWER: 你这个sql是个缝合怪了。。。
综合起来,表示从table1中查询AA等于"某个年月"的数据,"某个年月"为当前日期减2个"aa"的跨度 DATEADD (Transact-SQL) - SQL Server | Microsoft Docs Transact-SQL reference for the DATEADD function. This function returns a date that has been modified by the specified date part. https://docs.microsoft.com/en-us/sql/t-sql/functions/dateadd-transact-sql?view=sql-server-ver15 |
| LINK:https://ask.csdn.net/questions/7684815?answer=53748944 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684638 |
| ANSWER_ID:53748782 |
| TITLE:leetcode:182. 查找重复的电子邮箱,哪个mysql语句更准确 |
| ANSWER: 不论你count哪个字段,只要count的字段里没空值,都是对的,甚至count(1) 或者 count(*) 都是对的 |
| LINK:https://ask.csdn.net/questions/7684638?answer=53748782 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684491 |
| ANSWER_ID:53748756 |
| TITLE:无法在 System.DateTime 和 System.String 上执行“>=”操作。 |
| ANSWER: birth_date是个datetime类型么?如果是,要么把birth_date转换成string再比较,要么把 dateTimePicker1.Value 这玩意的前后拼上string转换成datetime的函数 |
| LINK:https://ask.csdn.net/questions/7684491?answer=53748756 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684347 |
| ANSWER_ID:53748473 |
| TITLE:制作报表时要统计制单人在每个单据的制单数sql怎么写? |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7684347?answer=53748473 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684329 |
| ANSWER_ID:53748468 |
| TITLE:对同一列数据进行百分比计算 |
| ANSWER: 查非本行数据时,使用开窗函数
|
| LINK:https://ask.csdn.net/questions/7684329?answer=53748468 |

| SOURCE:CSDN_ASK |
| ASK_ID:7684306 |
| ANSWER_ID:53748459 |
| TITLE:数据库原理与应用,使用的SQLserver,第一次创建数据库,按步骤操作的,这是哪里出问题了,要怎么解决呢, |
| ANSWER: 根据颜色来看,是单引号不对,第二个和第三个单引号输成全角的了,要改成半角的 |
| LINK:https://ask.csdn.net/questions/7684306?answer=53748459 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684262 |
| ANSWER_ID:53748417 |
| TITLE:请教下,像这个发生日期匹配最近的交易日的话语句逻辑怎么写啊 |
| ANSWER: 这个表看上去是个日历表,所以假定发生日期中间没有日期缺失
|
| LINK:https://ask.csdn.net/questions/7684262?answer=53748417 |

| SOURCE:CSDN_ASK |
| ASK_ID:7684299 |
| ANSWER_ID:53748350 |
| TITLE:oracle 条件查询不为空 不生效 |
ANSWER:保险起见,update set子查询中的where条件,应该和 where exists中的条件保持完全一致 |
| LINK:https://ask.csdn.net/questions/7684299?answer=53748350 |
| SOURCE:CSDN_ASK |
| ASK_ID:7684180 |
| ANSWER_ID:53748271 |
| TITLE:SQL数据库如何提取指定的金额数字 |
| ANSWER: 完全用自带函数来截取也可以,下列示例中拆解了截取的各个组成部分,方便理解
原数据格式不统一,用case when写4个不同的,反正原理都一样
注意先后顺序就好了,比如必须先判断带冒号的再判断不带冒号的。另外,如果冒号还分了全角半角,就再加两个case when |
| LINK:https://ask.csdn.net/questions/7684180?answer=53748271 |


| SOURCE:CSDN_ASK |
| ASK_ID:7684039 |
| ANSWER_ID:53748190 |
| TITLE:oracle查询11100011获取000左边第一个1 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7684039?answer=53748190 |

| SOURCE:CSDN_ASK |
| ASK_ID:7684142 |
| ANSWER_ID:53748099 |
| TITLE:sql语句中in prior是什么意思 |
| ANSWER: 能不能把你完整的sql拿出来? 你这里的prior是一个函数,从用法上来看,是传入一列查询结果,输出一列转换结果,类似于一个表函数, |
| LINK:https://ask.csdn.net/questions/7684142?answer=53748099 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683937 |
| ANSWER_ID:53748094 |
| TITLE:SqlServer 删除表的命令不大明白 |
| ANSWER: dbo.sysobjects是个系统对象表,object_id()是个函数,可以将表名转换成对应的对象id, OBJECTPROPERTY(id, N'IsUserTable') = 1 这个条件表示判断这个id的表必须是用户表,而不是系统表 |
| LINK:https://ask.csdn.net/questions/7683937?answer=53748094 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683969 |
| ANSWER_ID:53748088 |
| TITLE:按照某一特定条件在查询符合的where子句 |
| ANSWER: 建议再把问题描述详细点,如果不会描述,可以结合图示来进行说明 |
| LINK:https://ask.csdn.net/questions/7683969?answer=53748088 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683701 |
| ANSWER_ID:53747369 |
| TITLE:SQL Server 开机无法自动启动 MSSQLSERVER服务,可以手动启动,如何解决? |
| ANSWER: 把服务设置成 “自动(延迟启动)”试试
|
| LINK:https://ask.csdn.net/questions/7683701?answer=53747369 |

| SOURCE:CSDN_ASK |
| ASK_ID:7683626 |
| ANSWER_ID:53747352 |
| TITLE:MySQL具体是怎么回事 |
| ANSWER: 建议先了解一下关系型数据库,下面给出一个简单的例子。
这个例子中,很明显用户表和聊天记录表通过QQ号建立了关系,这就是关系型数据库最基本的应用。 |
| LINK:https://ask.csdn.net/questions/7683626?answer=53747352 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683658 |
| ANSWER_ID:53747337 |
| TITLE:aswAMSI.dll没有被指定在Windows 上运行 |
| ANSWER: 这个路径是AVG杀毒软件,要修复的话可以下载一个安装包重新安装 |
| LINK:https://ask.csdn.net/questions/7683658?answer=53747337 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683458 |
| ANSWER_ID:53747249 |
| TITLE:oracle里 查*快还是单查一个字段快 有没有文字性的理论依据 |
ANSWER:
这很明显了吧,读取的字节数相差这么大 |
| LINK:https://ask.csdn.net/questions/7683458?answer=53747249 |


| SOURCE:CSDN_ASK |
| ASK_ID:7683541 |
| ANSWER_ID:53747247 |
| TITLE:第16关: order by与limit |
| ANSWER: 楼上这个回答有问题,假设前3笔单都是同一个用户购买,这个sql输出的就是同一个用户了。 |
| LINK:https://ask.csdn.net/questions/7683541?answer=53747247 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683519 |
| ANSWER_ID:53747240 |
| TITLE:第17关 having |
ANSWER:
select ??? from lineitem
sum(quantity)
having sum(quantity)>6
select orderid,itemid,sum(quantity) as total
order by total desc 最后把这些玩意组装起来就是了。 sql是最接近自然语言的开发语言之一,记熟一些关键词,简单的场景直接翻译一下就差不多了 |
| LINK:https://ask.csdn.net/questions/7683519?answer=53747240 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683501 |
| ANSWER_ID:53747170 |
| TITLE:关于数据库的数据列多少是否会影响查询速度 |
| ANSWER: 我做个类比吧,假设这两种情况,数据的载体是你的纸质笔记本,每一页写满,第一种情况写的页数多,第二种情况写的页数少,然后你在最前面写了一页目录,目录里写了哪个id在哪一页的哪一行,所以两者的目录大小是一样的,所以在找数据在哪里这个环节,两者是一样的。接着就是去对应的页码和行数提取数据,你根据id去查同一个id的时候,明显第二种情况翻页次数不会比第一种多,因此大多数情况下第二种的开销会比较少。 |
| LINK:https://ask.csdn.net/questions/7683501?answer=53747170 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683487 |
| ANSWER_ID:53747158 |
| TITLE:hive的sql计算 |
| ANSWER: 一天之内,同一个用户访问同一个绘本的同一页,是有可能出现多条记录的,而单行的退出时间减进入时间只表示单次的记录,考虑到你最终结果里存在"观看次数"这个字段,这个字段肯定是要count的,因此多行的观看时长需要进行sum。此sql中,除了count和sum以外的查询字段,都需要进行group by |
| LINK:https://ask.csdn.net/questions/7683487?answer=53747158 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683477 |
| ANSWER_ID:53747146 |
| TITLE:PGSQL月份分组查询问题 |
| ANSWER: 给你两种方式,一个是递归,一个是数组转成一列
|
| LINK:https://ask.csdn.net/questions/7683477?answer=53747146 |

| SOURCE:CSDN_ASK |
| ASK_ID:7683409 |
| ANSWER_ID:53747113 |
| TITLE:Merge into的使用问题 |
| ANSWER: 建议看下执行计划,我写了一条简单的merge into 语句,执行计划长这样
可以看出这里是做了hash join ,而不是nested loop 或者fiter,所以应该是先进行匹配 当然不同数据库或者不同版本,原理可能会有区别 |
| LINK:https://ask.csdn.net/questions/7683409?answer=53747113 |

| SOURCE:CSDN_ASK |
| ASK_ID:7683306 |
| ANSWER_ID:53747081 |
| TITLE:数据库表的一个查询问题 |
| ANSWER: 你这表里哪个字段是选修?还是说选修标识在其他表里?或者说所有课程都是选修? |
| LINK:https://ask.csdn.net/questions/7683306?answer=53747081 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683352 |
| ANSWER_ID:53747064 |
| TITLE:getdate()相关问题 |
| ANSWER: getdate()函数返回是带时分秒的,你表里的数据不带时分秒,相当于时分秒为'00:00:00',当然会比getdate()要小,所以你要么getdate()减一天,要么格式化成年月日
|
| LINK:https://ask.csdn.net/questions/7683352?answer=53747064 |

| SOURCE:CSDN_ASK |
| ASK_ID:7683356 |
| ANSWER_ID:53747052 |
| TITLE:MySQL ORDER BY 语句失效 |
| ANSWER: 符号用错了,你标成了单引号,单引号表示字符串 |
| LINK:https://ask.csdn.net/questions/7683356?answer=53747052 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683401 |
| ANSWER_ID:53747038 |
| TITLE:oracle 计算本周为本年第几周 |
| ANSWER: 去日期是本年第几周用to_char,格式化参数为ww 或iw 字符串转日期用to_date函数 但是为了避免意外,建议将年份拼接完整,即 结合起来就是 |
| LINK:https://ask.csdn.net/questions/7683401?answer=53747038 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683373 |
| ANSWER_ID:53747005 |
| TITLE:请问为什么不能插入图片呢?正确操作应该是什么呀? |
| ANSWER: 用这种方式插入图片的话,首先这个文件应该先放到数据库所在服务器的某个文件夹下,然后插入时,要使用全路径,注意这个路径必须是数据库用户有权限的路径
|
| LINK:https://ask.csdn.net/questions/7683373?answer=53747005 |

| SOURCE:CSDN_ASK |
| ASK_ID:7682980 |
| ANSWER_ID:53746551 |
| TITLE:一对多left join(子查询group by)快还是left join副表,主表group by |
| ANSWER: 这题是不是有点问题?
b表是小表,因此去重后数据会更少(比如只剩下了10行),而且去重后,数据就变成了1对1,此时A表来关联这个小量的数据,行数不会变大,因此内存消耗也不会变大。但反观第一种,在join的时候,A表的部分数据翻倍了,而且恐怖的是,翻倍是根据B表的重复记录数来的,这个消耗肯定比第2种方式大,所以此时应该第二个sql更快。 |
| LINK:https://ask.csdn.net/questions/7682980?answer=53746551 |
| SOURCE:CSDN_ASK |
| ASK_ID:7683012 |
| ANSWER_ID:53746520 |
| TITLE:oracle 单查一个字段和查*有什么区别 |
| ANSWER: 查询数据时,先检索到对应的行,然后将行中指定的字段信息通过网络传输到客户端。很明显单查一个字段时,通过网络传输的数据要比多个字段更少,所以单查一个字段速度会更快 |
| LINK:https://ask.csdn.net/questions/7683012?answer=53746520 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682821 |
| ANSWER_ID:53746175 |
| TITLE:请问pgsql图片文件要放在哪里呢?这里导入的时候为什么找不到图片呢? |
| ANSWER: 可以使用数据库服务用户有权限的目录的绝对路径,参考下面这篇文章中的例子 |
| LINK:https://ask.csdn.net/questions/7682821?answer=53746175 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682837 |
| ANSWER_ID:53746157 |
| TITLE:mysql 输入文件目录报错Unknown command '\C'. |
| ANSWER: 斜杠的方向错了,要改成"/" |
| LINK:https://ask.csdn.net/questions/7682837?answer=53746157 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682749 |
| ANSWER_ID:53746081 |
| TITLE:MySQL8.0导入csv不成功怎么回事 |
| ANSWER: 这里有个坑,路径里的斜杠方向要设置成和linux的方向一样,和windows的默认斜杠是相反的,可以参考下面这个问答 https://stackoverflow.com/questions/31951468/error-code-1290-the-mysql-server-is-running-with-the-secure-file-priv-option 注意改完后要重启服务 |
| LINK:https://ask.csdn.net/questions/7682749?answer=53746081 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682696 |
| ANSWER_ID:53746036 |
| TITLE:mysql改变字段类型报错 |
| ANSWER: 你之前的字段类型是什么? 我模拟出来了,你原表中存在有空字符串'',而不是null,因此修改会报错
下面这个方式可以把你的这个字段成功改掉,但是由于你设置了不允许为null,因此只能默认设置个0上去了
|
| LINK:https://ask.csdn.net/questions/7682696?answer=53746036 |


| SOURCE:CSDN_ASK |
| ASK_ID:7682657 |
| ANSWER_ID:53746004 |
| TITLE:Mysql数据库操作语言的affect(0.02 sec) |
| ANSWER: 这是执行语句后,返回的信息,直接翻译成中文就行
|
| LINK:https://ask.csdn.net/questions/7682657?answer=53746004 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682423 |
| ANSWER_ID:53745891 |
| TITLE:oracle关系除法怎么做啊 |
| ANSWER: 请给出你原题的描述及表结构,是哪个集合除以哪个集合,你目前问题里完全没有描述题目内容和你的代码是怎样的。 mysql查询集合查询之数据库除法、关系代数除法(优化嵌套查询)_jester_jim的博客-CSDN博客_mysql 集合除法 1.除法(1)概述 除法操作一直是关系代数里面比较难理解的一个知识点,下面我将用一个简单的例子先阐述一下他的原理,让大家对他有个初步的认识。(2)引例S 属性 lesson属性 name 语文 sam 语文 peter 语文 lucy... https://blog.csdn.net/weixin_42217030/article/details/83317634 |
| LINK:https://ask.csdn.net/questions/7682423?answer=53745891 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682440 |
| ANSWER_ID:53745875 |
| TITLE:ludadhi删不掉怎么办,求帮助😱 |
| ANSWER: 正常卸载然后重启就好了,只是注意卸载的时候不要勾选保留温控模块 |
| LINK:https://ask.csdn.net/questions/7682440?answer=53745875 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682512 |
| ANSWER_ID:53745870 |
| TITLE:怎么样修改文件归属?试了好多都不行 |
| ANSWER: 你把你运行的代码及报错信息截个图出来看看 |
| LINK:https://ask.csdn.net/questions/7682512?answer=53745870 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682529 |
| ANSWER_ID:53745866 |
| TITLE:mysql同表多字段查询 |
| ANSWER: 先把sql里的password改成小写试试,因为你表里的字段名是小写的 |
| LINK:https://ask.csdn.net/questions/7682529?answer=53745866 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682375 |
| ANSWER_ID:53745733 |
| TITLE:sql server 两个表数据如何同步 |
| ANSWER: 需要定义一个更新来源,是来自于触发器或不是来自于触发器,否则你这个就是死循环了。 |
| LINK:https://ask.csdn.net/questions/7682375?answer=53745733 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682191 |
| ANSWER_ID:53745612 |
| TITLE:关于mysql数据库无事务前提下并发修改的问题 |
| ANSWER: 加锁只是为了防并发修改,不是为了防查,因此建议在查询之前先去查下有没有锁,没锁就加锁,然后再进行后续的查询和处理。 |
| LINK:https://ask.csdn.net/questions/7682191?answer=53745612 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682276 |
| ANSWER_ID:53745601 |
| TITLE:Python并行计算写入文件问题 |
| ANSWER: 不同的线程写入到不同文件里,最后再合并 |
| LINK:https://ask.csdn.net/questions/7682276?answer=53745601 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682231 |
| ANSWER_ID:53745594 |
| TITLE:mysql 数据裤 没有全关联,但是要补全数据 |
| ANSWER: 你这题与全外关联没关系,主要是少了col1加col2的完整清单,需要先自行构造。 |
| LINK:https://ask.csdn.net/questions/7682231?answer=53745594 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682283 |
| ANSWER_ID:53745582 |
| TITLE:无法安装oracle database 19c |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7682283?answer=53745582 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682115 |
| ANSWER_ID:53745382 |
| TITLE:mysql 下出现Unknown column 'saldesc' in 'order clause' |
| ANSWER: sal后面少了一个空格,应该拼出来的sql应该是 "order by sal desc",但你这个变成了"order by saldesc" |
| LINK:https://ask.csdn.net/questions/7682115?answer=53745382 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682064 |
| ANSWER_ID:53745325 |
| TITLE:Rstudio中创建Rmarkdown时报错 |
| ANSWER: 这个软件会写一些文件到你操作系统用户的应用文件夹中,从图上来看,你这个电脑的用户名包含有中文,因此被识别成乱码,报错了 |
| LINK:https://ask.csdn.net/questions/7682064?answer=53745325 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681952 |
| ANSWER_ID:53745303 |
| TITLE:用Navicat操作MYSQL,审计功能怎么打开 |
| ANSWER: mysql免费版(社区版)没有审计功能,如果要实现类似的审计功能,建议安装插件,可以参考下面这篇文章 干货 | MySQL数据库安全之审计 - 知乎 每家公司都希望业务高速增长,最好能出几个爆款产品或者爆款业务,从而带动公司营收高速攀升。但站在数据库管理员的角度,这却是实实在在的压力,业务高速增长必然带来数据量的暴增。数据库系统的选型和设计是支撑… https://zhuanlan.zhihu.com/p/67608184 |
| LINK:https://ask.csdn.net/questions/7681952?answer=53745303 |
| SOURCE:CSDN_ASK |
| ASK_ID:7682028 |
| ANSWER_ID:53745283 |
| TITLE:大数据量关联分析相关技术 |
| ANSWER: 可以去了解一下 "图数据库" |
| LINK:https://ask.csdn.net/questions/7682028?answer=53745283 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681697 |
| ANSWER_ID:53745237 |
| TITLE:请问一下pgsql怎么存储图片、文字和视频呀? |
| ANSWER: 一般来说,这种二进制文件,不太适合存储在关系型数据库中,但是关系型数据库的确大多都提供了这种类型的数据存储,在pgsql中是以bytea类型来存储二进制数据,可以通过pg_read_binary_file来获取指定文件的 bytea数据,再插入到表里即可,比如 postgresql存储二进制大数据文件 - XIAO的博客 - 博客园 如果想把整个文件或图片存储在数据表的一个字段内,该字段可以选择二进制类型,然后将文件按二进制存储起来,文本文件也可以存在text字段内。 示例如下: 二进制类型bytea的操作(在最大值内,有内存限制  https://www.cnblogs.com/xiaodf/p/5027195.html 当然也可以使用其他开发语言读取二进制数据,然后转换成对应的格式存入bytea字段。 关于二进制数据类型的相关转换,可以参考官方文档 |
| LINK:https://ask.csdn.net/questions/7681697?answer=53745237 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681791 |
| ANSWER_ID:53745144 |
| TITLE:多条件流程控制语句更新某一个字段值 |
| ANSWER: mysql里没有你这样的 REGEXP的用法,你要么把第二段的when都改成和第一段when的like那样,要么就使用regexp_like函数 |
| LINK:https://ask.csdn.net/questions/7681791?answer=53745144 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681827 |
| ANSWER_ID:53745132 |
| TITLE:10-30 查询平均成绩最高的同学(MSSQL) (10 分) |
| ANSWER: 这个题里有个暗坑,sc表里存在有学生的部分科目分数为空,此时如果直接使用avg函数,会只对有分数的科目来进行平均计算,导致平均分偏高,因此需要把空的转化成0,或者使用sum(grade)/count(1)的方式。然后用top取排序后的第一行即可 或者使用开窗函数取排名 |
| LINK:https://ask.csdn.net/questions/7681827?answer=53745132 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681839 |
| ANSWER_ID:53745115 |
| TITLE:ClickHouse数据库位图函数如何实现一列数组的交集 |
| ANSWER: bitmapAnd(bitmap1,bitmap2) 一列数据的话,应该是用聚合函数了,看看下面这几个函数
https://clickhouse.com/docs/en/sql-reference/aggregate-functions/reference/groupbitmapor |
| LINK:https://ask.csdn.net/questions/7681839?answer=53745115 |

| SOURCE:CSDN_ASK |
| ASK_ID:7681880 |
| ANSWER_ID:53745112 |
| TITLE:为什么代码换台机就不能运行了? |
| ANSWER: 先在侧边栏里的schema列表里选择一个数据库,然后再运行代码 |
| LINK:https://ask.csdn.net/questions/7681880?answer=53745112 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680945 |
| ANSWER_ID:53745109 |
| TITLE:Sql server2000迁移问题 |
| ANSWER: 将 SQL Server 升级到 SQL Server 2019 - SQL Server | Microsoft Docs 关于对数据资产进行改造的分步指导 https://docs.microsoft.com/zh-cn/sql/sql-server/migrate/guides/sql-server-to-sql-server-upgrade-guide?view=sql-server-ver15 |
| LINK:https://ask.csdn.net/questions/7680945?answer=53745109 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681705 |
| ANSWER_ID:53745049 |
| TITLE:python 执行oracle sql 报错 ORA-00900: invalid SQL statement |
| ANSWER: 你这运行的是一个文件路径的字符串,当然不行了。至少得先把文件内容读出来吧,当然读出来你也会发现运行不了,因为它一次只能执行一条sql。但一旦你打算分隔语句逐条去执行,又会发现需要sql语法解析器... 定期数据不建议使用sql格式文件,sql格式一般是用于部署或者初始化一次性执行。你这个sql格式的目前只能调用操作系统命令通过sqlplus执行了。这不是复杂sql的问题,而是你一个文件里是有多条语句的,而在客户端一次只能执行一个sql语句或者一个plsql块,所以只能在sqlplus里来执行sql文件,sqlplus会按语法解析器自动把语句拆分并逐条执行 |
| LINK:https://ask.csdn.net/questions/7681705?answer=53745049 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681806 |
| ANSWER_ID:53745022 |
| TITLE:有没有免费好用的MySQL数据库管理软件啊? |
| ANSWER: mysql原厂的workbench是免费的, |
| LINK:https://ask.csdn.net/questions/7681806?answer=53745022 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681810 |
| ANSWER_ID:53745016 |
| TITLE:SQL命令把pur纯度的数值后面都加上% |
| ANSWER: 这其实就是一个简单的字符串拼接而已,但要看你是用的什么数据库,还有你这个字段的类型是什么。 |
| LINK:https://ask.csdn.net/questions/7681810?answer=53745016 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681729 |
| ANSWER_ID:53744956 |
| TITLE:MySQL中创建表1为男,0为女怎么弄,还有默认为女怎么弄 |
ANSWER:好像还要加个check 枚举值也可以用enum('0','1') |
| LINK:https://ask.csdn.net/questions/7681729?answer=53744956 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681388 |
| ANSWER_ID:53744782 |
| TITLE:关于#mysql#的问题:求 每个名字的所有科目总分(所有科目分数加起来),要用一条sql语句查询,分多条语句查询我会,但是在科目多了会影响效率名字 分数小明 155小红 77小利 55 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7681388?answer=53744782 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681429 |
| ANSWER_ID:53744776 |
| TITLE:关于使用VMware使用openGauss时遇到无法连接默认数据库postgres的问题 |
| ANSWER: VirtualBox的报错是因为你电脑的用户名里包含中文。 给你个更简单的方法吧,反正你这已经安装了虚拟机了,可以在虚拟机里把docker装了,然后在docker拉取opengauss的镜像,启动容器,数据库就有了,完全不用管数据库的相关配置 |
| LINK:https://ask.csdn.net/questions/7681429?answer=53744776 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681497 |
| ANSWER_ID:53744761 |
| TITLE:SQL server安装失败 |
| ANSWER: 尝试一下鼠标右键使用管理员身份运行 |
| LINK:https://ask.csdn.net/questions/7681497?answer=53744761 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681517 |
| ANSWER_ID:53744758 |
| TITLE:mysql中如何计算销售额 |
| ANSWER: 你题目里不是已经把公式列出来了么? |
| LINK:https://ask.csdn.net/questions/7681517?answer=53744758 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681570 |
| ANSWER_ID:53744754 |
| TITLE:oracle date类型字段直接to_char年月日 显示00000000 加个trunc再to_Char显示就正常了 这是为什么 |
| ANSWER: 请把你的数据及代码贴出来,不知道你所说的正常是个什么意思
|
| LINK:https://ask.csdn.net/questions/7681570?answer=53744754 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681322 |
| ANSWER_ID:53744747 |
| TITLE:每个班级前5%的学生名单前5%学生成绩,计算5%时若非整数向上取整怎么写? |
| ANSWER: 分析:
如果是指每班输出人数大于5的话,用下面这个 能不能把你的create table 和数据的insert发出一下? |
| LINK:https://ask.csdn.net/questions/7681322?answer=53744747 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681191 |
| ANSWER_ID:53744300 |
| TITLE:相同的存储过程语句在SQLyog执行报错,但在cmd中执行成功,这是为什么 |
| ANSWER: 很明显,两边的语句结束符不一致,上面的结束符已经改成了"",下面的还是默认的";"<br />你cmd里是不是执行过下面这个东西?</p><br/><pre><code class="language-sql">DELIMITER <span class="hljs-symbol"> |
| LINK:https://ask.csdn.net/questions/7681191?answer=53744300 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681036 |
| ANSWER_ID:53744275 |
| TITLE:【MySQL】在一个trigger下实现insert or update 执行某语句块时失败 |
| ANSWER: mysql不像oracle那样可以支持定义多个触发事件,不同触发事件就得建不同的触发器,下面是mysql触发器的创建语法 MySQL :: MySQL 8.0 Reference Manual :: 25.3.1 Trigger Syntax and Examples https://dev.mysql.com/doc/refman/8.0/en/trigger-syntax.html |
| LINK:https://ask.csdn.net/questions/7681036?answer=53744275 |
| SOURCE:CSDN_ASK |
| ASK_ID:7681070 |
| ANSWER_ID:53744258 |
| TITLE:通过yum安装mariadb默认存放路径在哪里 |
| ANSWER: linux里安装的很多程序,其实文件会分散到不同的地方,比如bin下放可执行文件、lib下放动态库文件,所以你找到的很多文件存放位置其实都的确是它的存放位置,实际上并不存在一个完整的文件夹存放了它所有的文件。
你如果要找它的配置文件,一般是在etc目录下,根据madiadb版本的不同,有的直接在etc下,有的在etc/mysql下。 |
| LINK:https://ask.csdn.net/questions/7681070?answer=53744258 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680796 |
| ANSWER_ID:53743960 |
| TITLE:为什么下面这段代码,用升序和降序会输出不一样的值? |
| ANSWER: 建议截图证明。 |
| LINK:https://ask.csdn.net/questions/7680796?answer=53743960 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680386 |
| ANSWER_ID:53743492 |
| TITLE:一直报错,又不知道错在哪 |
| ANSWER: 字符集不对,导致中文无法识别,要么修改这个窗口的字符集,要么不使用中文 |
| LINK:https://ask.csdn.net/questions/7680386?answer=53743492 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680442 |
| ANSWER_ID:53743491 |
| TITLE:A表和B表 两张表 B表ID作为条件,过滤数据不显示 |
| ANSWER: ACCESS想查找一下customer里cust_id有但sales_detail表里cust_id无的数据,SQL写完运行无结果-大数据-CSDN问答 CSDN问答为您找到ACCESS想查找一下customer里cust_id有但sales_detail表里cust_id无的数据,SQL写完运行无结果相关问题答案,如果想了解更多关于ACCESS想查找一下customer里cust_id有但sales_detail表里cust_id无的数据,SQL写完运行无结果 sql、数据库 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7678276?answer=53740524 上面这个题,把表名和字段名换一下就和你这个问题一模一样了,比如 |
| LINK:https://ask.csdn.net/questions/7680442?answer=53743491 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680452 |
| ANSWER_ID:53743489 |
| TITLE:关于mysql自增id删除后继续添加新的数据后,id不连续的问题 |
| ANSWER: 不连续是正常的,这个东西只要保证自增且唯一就行了。 |
| LINK:https://ask.csdn.net/questions/7680452?answer=53743489 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680202 |
| ANSWER_ID:53743380 |
| TITLE:mysql数据库问题 |
| ANSWER: 鼠标右键,使用管理员身份运行。 |
| LINK:https://ask.csdn.net/questions/7680202?answer=53743380 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680316 |
| ANSWER_ID:53743373 |
| TITLE:我定义的v7视图是成功的,但是在v6视图的where中调用v7视图时却报错,这是怎么回事 |
| ANSWER: 等于号后面不能接视图名称,只能接函数或者值 然后v6视图里后面的等于号改成一个查询 这样语法就对了,视图返回的是一个查询表格,而不是一个值,所以只能select它, |
| LINK:https://ask.csdn.net/questions/7680316?answer=53743373 |
| SOURCE:CSDN_ASK |
| ASK_ID:7679680 |
| ANSWER_ID:53743205 |
| TITLE:如何在windows环境下用软件检测hdmi输出 |
| ANSWER: windows有提供很多关于硬件的api的,可以参考这个vbs脚本中的例子 VBS Script – Get Monitor Serial Number Remotely https://www.itsupportguides.com/knowledge-base/vbs-scripts/vbs-script-get-monitor-serial-number-remotely/ 这个脚本可以输出有多少个显示器及显示器的相关信息
|
| LINK:https://ask.csdn.net/questions/7679680?answer=53743205 |

| SOURCE:CSDN_ASK |
| ASK_ID:7679679 |
| ANSWER_ID:53743189 |
| TITLE:.net npgsql的插入操作是不是底层报错有问题啊,总抛出主键重复 |
| ANSWER: 从这个现象上来看,是插入代码被重复执行了,你可以尝试把插入的主键字段改成一个随机数,再执行一次,看看是不是插入了多条数据 |
| LINK:https://ask.csdn.net/questions/7679679?answer=53743189 |
| SOURCE:CSDN_ASK |
| ASK_ID:7679117 |
| ANSWER_ID:53743176 |
| TITLE:SQLserver 2019可否跨平台 |
| ANSWER: Linux 上的 SQL Server 的安装指南 - SQL Server | Microsoft Docs 安装、更新和卸载 Linux 上的 SQL Server。 本文介绍了联机、脱机和无人参与的方案。 https://docs.microsoft.com/zh-cn/sql/linux/sql-server-linux-setup?view=sql-server-ver15 把它构建docker镜像的代码弄出来稍微改改,其实也就是在linux上的安装步骤了 |
| LINK:https://ask.csdn.net/questions/7679117?answer=53743176 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680143 |
| ANSWER_ID:53743150 |
| TITLE:sqlite 模糊查询数据存在查询为空 |
| ANSWER: 你数据里的确是不存在 '查询错误sql' 这个值,在'查询错误'和'sql'中间还存在其他字符,用下面这个就能查到了 |
| LINK:https://ask.csdn.net/questions/7680143?answer=53743150 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680061 |
| ANSWER_ID:53743133 |
| TITLE:怎么保证组内多条数据百分比之和始终为100,类似于秒杀问题 |
| ANSWER: 你这是用户直接更新rate字段?比如一个组有两条记录,更新其中一条为80的时候,另一条要自动变成20? |
| LINK:https://ask.csdn.net/questions/7680061?answer=53743133 |
| SOURCE:CSDN_ASK |
| ASK_ID:7680117 |
| ANSWER_ID:53743097 |
| TITLE:PGSQL sql语句提交出现schema " " already exists |
| ANSWER: 你想创建的schema已经存在了,不能重复创建 |
| LINK:https://ask.csdn.net/questions/7680117?answer=53743097 |
| SOURCE:CSDN_ASK |
| ASK_ID:7679854 |
| ANSWER_ID:53742790 |
| TITLE:mysql怎么实现分组更新呢? |
| ANSWER: 分组排序查询 更新 开窗函数要8.0以上才支持,而且开窗函数早就纳入了sql标准,mysql落后其他数据库太多了
对于不支持开窗函数的老版本数据库,这种操作建议写存储过程或者用其他开发语言来处理, |
| LINK:https://ask.csdn.net/questions/7679854?answer=53742790 |

| SOURCE:CSDN_ASK |
| ASK_ID:7679557 |
| ANSWER_ID:53742274 |
| TITLE:mysql如何将一个表格中的id在一定条件下同步更新到另一个表格的某个列中? |
ANSWER:需要确保A表中 ud+cname 是唯一的 |
| LINK:https://ask.csdn.net/questions/7679557?answer=53742274 |
| SOURCE:CSDN_ASK |
| ASK_ID:7679324 |
| ANSWER_ID:53742180 |
| TITLE:关于PLSQL题,实在是不会了 |
| ANSWER: 最简单的方法的确是像楼上这样自关联两次 用开窗函数的range滑动窗口可以找前1天或者前n天,但是要找前一年会稍微有点麻烦,还不如像上面这样多查一次这个表 |
| LINK:https://ask.csdn.net/questions/7679324?answer=53742180 |
| SOURCE:CSDN_ASK |
| ASK_ID:7679363 |
| ANSWER_ID:53742163 |
| TITLE:数据库查询多列中重复出现的数据次数,不是重复的行 |
| ANSWER: 通用写法就是单独查每一列,union all起来,再count。 |
| LINK:https://ask.csdn.net/questions/7679363?answer=53742163 |
| SOURCE:CSDN_ASK |
| ASK_ID:7679410 |
| ANSWER_ID:53742155 |
| TITLE:Mysql关联查询,无数据的字段显示错误的数据 |
| ANSWER: 漏了两个关联条件
另外,你这sql没必要一层一层的套, 下面这种写法也是可以的 下面两种写法都可以 |
| LINK:https://ask.csdn.net/questions/7679410?answer=53742155 |

| SOURCE:CSDN_ASK |
| ASK_ID:7679454 |
| ANSWER_ID:53742147 |
| TITLE:python 文件读写操作 怎么写才能尽量少用循环语句同时完成 读取 筛选 写入 并输出? |
| ANSWER: 用pandas包,可以快速过滤或聚合数据, |
| LINK:https://ask.csdn.net/questions/7679454?answer=53742147 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678169 |
| ANSWER_ID:53741947 |
| TITLE:SQL:2个人一起去看电影,准备预定电影票横向坐在一起,从1-15编号中从这么多排座位中,找出连续2个空位的全部组合,结果输出座位组合情况例(1、2 4、5) |
| ANSWER: 先说下数据库类型及版本 下面是连续两个的
下面是4个及以上连续座位的
|
| LINK:https://ask.csdn.net/questions/7678169?answer=53741947 |


| SOURCE:CSDN_ASK |
| ASK_ID:7679153 |
| ANSWER_ID:53741932 |
| TITLE:sql server 语句问题请教下 |
| ANSWER: 查非本行数据用开窗函数 |
| LINK:https://ask.csdn.net/questions/7679153?answer=53741932 |
| SOURCE:CSDN_ASK |
| ASK_ID:7679168 |
| ANSWER_ID:53741919 |
| TITLE:where条件可能有多种,如何在一个表中拿到所有的结果 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7679168?answer=53741919 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678770 |
| ANSWER_ID:53741862 |
| TITLE:检索出每个班级中分数最低的同学id,姓名,分数,班级名称 |
| ANSWER: 用开窗函数,每个表都只用查一次 |
| LINK:https://ask.csdn.net/questions/7678770?answer=53741862 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678777 |
| ANSWER_ID:53741838 |
| TITLE:oracle 判断字符串是否含逗号,如果有取第一个值 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7678777?answer=53741838 |

| SOURCE:CSDN_ASK |
| ASK_ID:7678808 |
| ANSWER_ID:53741818 |
| TITLE:sql server每月数据求和 |
| ANSWER: sql判断某一列,加载列的和-微软技术-CSDN问答 CSDN问答为您找到sql判断某一列,加载列的和相关问题答案,如果想了解更多关于sql判断某一列,加载列的和 c#、后端、数据库架构 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7678158?spm=1001.2014.3001.5505 下面是这个sql就是按照我上个题里的思路写的应该符合你的要求 sqlserver里实测效果
不知道你要不要按jh分组,如果不分组,把jh相关的去掉就行了 没想到是这么老的版本,用下面这个吧
|
| LINK:https://ask.csdn.net/questions/7678808?answer=53741818 |


| SOURCE:CSDN_ASK |
| ASK_ID:7678823 |
| ANSWER_ID:53741796 |
| TITLE:两台linux主机如何远程执行oracle数据泵导入操作? |
| ANSWER: 分下情况
|
| LINK:https://ask.csdn.net/questions/7678823?answer=53741796 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678834 |
| ANSWER_ID:53741544 |
| TITLE:关于#mysql#的问题:创建这个表格时控制台总会报错,看不出问题是什么原因 |
| ANSWER: 你mysql的版本多少?实测你这个sql在5.5及以下版本会报错,但是在5.6及以上不会报错
|
| LINK:https://ask.csdn.net/questions/7678834?answer=53741544 |


| SOURCE:CSDN_ASK |
| ASK_ID:7678840 |
| ANSWER_ID:53741537 |
| TITLE:mysql大数据量查询 count groupby 查询无结果 |
| ANSWER: 把order by去掉再试试,估计你这个数据量太大,src不同的值过多,临时表空间已经没法支撑排序了,建议得到group by 的结果后再排序,不要放在一起处理 |
| LINK:https://ask.csdn.net/questions/7678840?answer=53741537 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678845 |
| ANSWER_ID:53741532 |
| TITLE:sq语句在线检测的网址或者工具 |
| ANSWER: 这个应该可以满足你的要求,目前有9大数据库类型,共29个不同版本数据库可用 |
| LINK:https://ask.csdn.net/questions/7678845?answer=53741532 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678871 |
| ANSWER_ID:53741530 |
| TITLE:oracle存储过程转换为MySQL存储过程 |
| ANSWER: 看上去这是生成一组随机测试数据集。 |
| LINK:https://ask.csdn.net/questions/7678871?answer=53741530 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678547 |
| ANSWER_ID:53740893 |
| TITLE:sql server数据库中的两个ID之间是否存在联系 |
| ANSWER: 可以用with递归,注意环的处理,比如
上面这个sql就是用'3'来找是否和'6'有关系,只看10层,不设限的话可能会有无限循环。 下面这个就是从张3到马6的10层以内最短路径
|
| LINK:https://ask.csdn.net/questions/7678547?answer=53740893 |


| SOURCE:CSDN_ASK |
| ASK_ID:7678318 |
| ANSWER_ID:53740852 |
| TITLE:SQL A表有 a1 a2字段,大概1000条数据。 |
| ANSWER: 关联的条件不唯一,多对多关联,导致产生笛卡尔积,比如下面这个例子
|
| LINK:https://ask.csdn.net/questions/7678318?answer=53740852 |

| SOURCE:CSDN_ASK |
| ASK_ID:7678376 |
| ANSWER_ID:53740837 |
| TITLE:数据库这个是怎么回事呢? |
| ANSWER: 绝对是冲突了,不要只看当前界面,你当前数据处于编辑状态,不是表当前的实际数据。 |
| LINK:https://ask.csdn.net/questions/7678376?answer=53740837 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678455 |
| ANSWER_ID:53740830 |
| TITLE:mysql connector安装失败问题 |
| ANSWER: 可能是网络原因导致下载失败,如果需要使用这两个连接驱动,可以去官网单独下载这两个包进行安装
|
| LINK:https://ask.csdn.net/questions/7678455?answer=53740830 |

| SOURCE:CSDN_ASK |
| ASK_ID:7678476 |
| ANSWER_ID:53740825 |
| TITLE:关于#mysql#的问题:mysql |
| ANSWER: 你学生不增加了是吧?确定是想用这种方法随机找一个学生? rand()是个伪列函数,返回的不是一个值,而是一列值,因此你表里有多少行数据,它就会返回多少个值,然后有概率刚好可以匹配上多行记录 |
| LINK:https://ask.csdn.net/questions/7678476?answer=53740825 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678158 |
| ANSWER_ID:53740808 |
| TITLE:sql判断某一列,加载列的和 |
| ANSWER: 说说看用的是什么数据库,不同数据库的写法不一样。 |
| LINK:https://ask.csdn.net/questions/7678158?answer=53740808 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678276 |
| ANSWER_ID:53740524 |
| TITLE:ACCESS想查找一下customer里cust_id有但sales_detail表里cust_id无的数据,SQL写完运行无结果 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7678276?answer=53740524 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678295 |
| ANSWER_ID:53740520 |
| TITLE:在sql中多大的数据才算是大数据? |
| ANSWER: "大数据量"和"大数据"不一样。 |
| LINK:https://ask.csdn.net/questions/7678295?answer=53740520 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678198 |
| ANSWER_ID:53740515 |
| TITLE:Oracle12 database安装时Activeperl与数据库建立联系时老是错误 |
| ANSWER:
肉眼观察,此处空格宽度不对 |
| LINK:https://ask.csdn.net/questions/7678198?answer=53740515 |

| SOURCE:CSDN_ASK |
| ASK_ID:7678114 |
| ANSWER_ID:53740426 |
| TITLE:oracle中merge into怎么转换成postgresql?如图 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7678114?answer=53740426 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678031 |
| ANSWER_ID:53740149 |
| TITLE:oracle存储过程重复执行,用于表1更新表2数据,怎么做到表2被更新过的数据不再拿来更新呢 |
| ANSWER: 在表1上新增一个状态字段,默认为"未处理",每次更新都只找"未处理"状态的数据,更新完一次后,标记这个字段为"处理完成",注意在游标中处理,防止在更新数据时正好有数据写入 |
| LINK:https://ask.csdn.net/questions/7678031?answer=53740149 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677834 |
| ANSWER_ID:53740143 |
| TITLE:sql的索引影响速度很大么? |
| ANSWER: 索引建得越复杂,插入速度就会越慢。 |
| LINK:https://ask.csdn.net/questions/7677834?answer=53740143 |
| SOURCE:CSDN_ASK |
| ASK_ID:7678009 |
| ANSWER_ID:53740124 |
| TITLE:sql语句添加发生冲突 |
| ANSWER: 你看下CSJING_JBXXB这个表的表结构,是不是有主键、唯一索引、约束、检查之类的东西。 |
| LINK:https://ask.csdn.net/questions/7678009?answer=53740124 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677670 |
| ANSWER_ID:53739474 |
| TITLE:刚在学数据库,大家看看该怎么码。 |
| ANSWER: 弄个check判断一下就好了 |
| LINK:https://ask.csdn.net/questions/7677670?answer=53739474 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677505 |
| ANSWER_ID:53739473 |
| TITLE:如何从K1到K16这16个组里 任意取10个组,保证这10个组的分数相加的和为33,请专家答疑解惑 |
ANSWER:
思路: |
| LINK:https://ask.csdn.net/questions/7677505?answer=53739473 |

| SOURCE:CSDN_ASK |
| ASK_ID:7677188 |
| ANSWER_ID:53739264 |
| TITLE:Mysql 更新表时Incorrect Datetime Value |
| ANSWER: 把你目标表的表结构发出来一下看看 |
| LINK:https://ask.csdn.net/questions/7677188?answer=53739264 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677213 |
| ANSWER_ID:53739260 |
| TITLE:请问怎么把jieba库的结果导入进mysql,还是只能jieba分词结果手动输入进mysql |
| ANSWER: 在python 里可以连接mysql数据库,可以拼接sql语句,将jieba的结果insert到数据库里指定的一张表里去 |
| LINK:https://ask.csdn.net/questions/7677213?answer=53739260 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677237 |
| ANSWER_ID:53739255 |
| TITLE:sql语句的问题,有什么好办法 |
| ANSWER: 一个简单的关联后再count而已 |
| LINK:https://ask.csdn.net/questions/7677237?answer=53739255 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677315 |
| ANSWER_ID:53739248 |
| TITLE:oracle 12c 插拔式数据库,密码无效。 |
| ANSWER: 这个要用PDB的名称作为service_name来新建一个tnsname,然后连接的时候指定连接到pdb环境, 不指定环境的话,它默认就连到cdb上去了,而cdb里面没这个用户,它当然报错了 |
| LINK:https://ask.csdn.net/questions/7677315?answer=53739248 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677327 |
| ANSWER_ID:53739236 |
| TITLE:Oracle19草Scott登录被拒绝求解答 |
| ANSWER: 因为oracle19c版本里压根就没有scott这个用户,那些用scott用户的教程都是十几年前的过时教程了。 |
| LINK:https://ask.csdn.net/questions/7677327?answer=53739236 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677343 |
| ANSWER_ID:53739228 |
| TITLE:无法绑定由多个部分组成的标识符,如何解决? |
| ANSWER:
同一层的表连接要么都用逗号,要么都用join,别两种混用 |
| LINK:https://ask.csdn.net/questions/7677343?answer=53739228 |

| SOURCE:CSDN_ASK |
| ASK_ID:7677391 |
| ANSWER_ID:53739226 |
| TITLE:Oracle更新多行某字段数据 |
| ANSWER: 请用数据举例 |
| LINK:https://ask.csdn.net/questions/7677391?answer=53739226 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677122 |
| ANSWER_ID:53738904 |
| TITLE:dbeaver连接click house有问题,提示不能创建实例 |
ANSWER:
还是少了驱动文件 |
| LINK:https://ask.csdn.net/questions/7677122?answer=53738904 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677098 |
| ANSWER_ID:53738898 |
| TITLE:tracer for oracle 跟踪oracle中文字段是乱码 |
| ANSWER: 你访问数据库的客户端字符集与这个软件显示的字符集不一致,但这个软件貌似没有地方可以调整字符集, |
| LINK:https://ask.csdn.net/questions/7677098?answer=53738898 |
| SOURCE:CSDN_ASK |
| ASK_ID:7677065 |
| ANSWER_ID:53738862 |
| TITLE:请问oracle存储过程更新员工请假数据问题 |
| ANSWER: 不应该采取这种更新加的方式,而是应该直接根据当前数据把这些值统计出来,因为光根据时间是无法判断数据是否为新增 这样你就可以直接拿这个数据更新,甚至可以直接用这个数据出报表了 |
| LINK:https://ask.csdn.net/questions/7677065?answer=53738862 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676767 |
| ANSWER_ID:53738827 |
| TITLE:sql 求各班级平均分及个人平均分 |
| ANSWER: 用开窗函数呗 本行数据要出现非本行数据中的字段或用到了非本行数据的统计值,要么另外写个子查询来关联,要么就用开窗函数 |
| LINK:https://ask.csdn.net/questions/7676767?answer=53738827 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676769 |
| ANSWER_ID:53738812 |
| TITLE:case when 结合 sum函数失效 |
| ANSWER: 最直接的思路,先查一次合计的,然后再union all 一次没有合计的 另外一种思路,将合计和非合计的统计成两个字段分别统计,再判断原有的合计是否为0,为0则取非合计的统计值,不为0则取合计的统计值 其实上面两种方式,要么是按行拆开,要么是按列拆开,当然也有其他写法,但方向应该都是怎么把数据拆开,才方便进行统计 |
| LINK:https://ask.csdn.net/questions/7676769?answer=53738812 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676805 |
| ANSWER_ID:53738785 |
| TITLE:修改oracle的系统时间,使sysdate为之后指定的时间 |
| ANSWER: oracle的sysdate是从数据库所在的服务器操作系统上取的,通俗点说就是电脑时间,随便修改可能会导致各种异常问题。
|
| LINK:https://ask.csdn.net/questions/7676805?answer=53738785 |

| SOURCE:CSDN_ASK |
| ASK_ID:7676846 |
| ANSWER_ID:53738580 |
| TITLE:Oracle查询出column1一致column2不一致的数据 |
| ANSWER: 不一致不就是不相等么?没明白你为什么会想着写个这么复杂的sql 如果有空值 column1一致column2不一致,查询结果只需要对应的column1有哪些值的话 如果需要同时展示原表所有字段数据,要么用上面这个数据作为匹配条件,要么用开窗函数来实现只对原表进行一次查询 |
| LINK:https://ask.csdn.net/questions/7676846?answer=53738580 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676928 |
| ANSWER_ID:53738572 |
| TITLE:如何Excel Power Query分组依据分组后,提取每一个分组的前10行数据 |
| ANSWER: Power BI Power Query 排名2-分组排名 - alexywt - 博客园 前一篇关于排名的博文Power BI Power Query 排名1-非连续排名和连续排名中,我们是基于整个表对分数进行排名,假若有如下形式的数据,我们需要最终的名次是按照分组来归类排名的,这种排名应 https://www.cnblogs.com/alexywt/p/11394226.html 另外,也可以使用TABLE.GROUP |
| LINK:https://ask.csdn.net/questions/7676928?answer=53738572 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676146 |
| ANSWER_ID:53737830 |
| TITLE:sql Server过程(如下图)这种是什么原因昂 |
| ANSWER: 这个报错是说这个东西是个表,不能当成过程来执行,查询表只能用select |
| LINK:https://ask.csdn.net/questions/7676146?answer=53737830 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676514 |
| ANSWER_ID:53737821 |
| TITLE:MySQL里 求在A表中的SFZH和name两列,和B表中的sfzh和name两列没有的数据,如何解决? |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7676514?answer=53737821 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676314 |
| ANSWER_ID:53737776 |
| TITLE:NBA预测应用数据统计 |
| ANSWER: 你预测是想说预测胜负?重点是看你用什么数据,以及各数据所占的权重、整体的计算模型设计。 影响胜负的因子可不仅仅只有这一点点球员数据哦,比如这个球员吃了什么,赛前做了什么事,教练心情怎么样,观众有哪些,球场地板状态,裁判等等...还要结合历史每一场的这些因子,综合判断所有因子对这个胜负模型的影响,考虑得越多预测得就越准 |
| LINK:https://ask.csdn.net/questions/7676314?answer=53737776 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676354 |
| ANSWER_ID:53737764 |
| TITLE:sql问题,目前卡住了 |
| ANSWER: 说下你用的数据库是什么,版本是多少。
mysql的话,用下面这个写法
|
| LINK:https://ask.csdn.net/questions/7676354?answer=53737764 |


| SOURCE:CSDN_ASK |
| ASK_ID:7676357 |
| ANSWER_ID:53737739 |
| TITLE:如何解决查询20部门奖金为空的员工信息的问题 |
| ANSWER: 请给出你的表结构、数据,以及你想要得到的查询结果样例 |
| LINK:https://ask.csdn.net/questions/7676357?answer=53737739 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676423 |
| ANSWER_ID:53737736 |
| TITLE:PYMYSQL 总说语法错误 |
| ANSWER:
这两个逗号好像长得不一样 |
| LINK:https://ask.csdn.net/questions/7676423?answer=53737736 |

| SOURCE:CSDN_ASK |
| ASK_ID:7676401 |
| ANSWER_ID:53737729 |
| TITLE:Navicat15怎么设置默认小写?? |
| ANSWER: 能不能说一下你的操作步骤,再截几个图说明一下?你指的大写是什么时候在哪里出现大写? 你说的是关键词自动完成的功能? |
| LINK:https://ask.csdn.net/questions/7676401?answer=53737729 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676177 |
| ANSWER_ID:53737719 |
| TITLE:为啥有人说谈恋爱不要找程序员? |
| ANSWER: 开启debug1,然后手动运行job,看看具体报什么错 |
| LINK:https://ask.csdn.net/questions/7676177?answer=53737719 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676080 |
| ANSWER_ID:53737565 |
| TITLE:HIVESQL数据排序问题 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7676080?answer=53737565 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676164 |
| ANSWER_ID:53737545 |
| TITLE:如何将冗杂SQL进行简易传达 |
| ANSWER: 首先,必须要了解这个sql中的用到的所有语法, |
| LINK:https://ask.csdn.net/questions/7676164?answer=53737545 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675591 |
| ANSWER_ID:53737533 |
| TITLE:oracle 如何实现树结构合并查询 |
| ANSWER: with递归比connect by 递归更容易理解
|
| LINK:https://ask.csdn.net/questions/7675591?answer=53737533 |

| SOURCE:CSDN_ASK |
| ASK_ID:7675601 |
| ANSWER_ID:53737510 |
| TITLE:SQL中的数字转换事宜 |
| ANSWER: 不知道你用的是什么数据库,不同的数据库这几个函数有一点点区别,下面以oracle为例
|
| LINK:https://ask.csdn.net/questions/7675601?answer=53737510 |

| SOURCE:CSDN_ASK |
| ASK_ID:7675603 |
| ANSWER_ID:53737494 |
| TITLE:SQL中SET函数的问题 |
| ANSWER: 把"new"的值,赋给dips.sql.hgt.getjsonobj这个对象中的new值 |
| LINK:https://ask.csdn.net/questions/7675603?answer=53737494 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675608 |
| ANSWER_ID:53737491 |
| TITLE:mysql中函数的问题! |
| ANSWER: GET_JSON_OBJECT是一个函数,第一个参数是一个json字段,第二个参数是json的路径, |
| LINK:https://ask.csdn.net/questions/7675608?answer=53737491 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675649 |
| ANSWER_ID:53737483 |
| TITLE:MySQL一直出现这个问题 |
| ANSWER: 这语法错误很明显啊,随便找个现有的表对比一下就知道了,下面这个语法才是正确的
|
| LINK:https://ask.csdn.net/questions/7675649?answer=53737483 |

| SOURCE:CSDN_ASK |
| ASK_ID:7675674 |
| ANSWER_ID:53737474 |
| TITLE:mysql的更新、删除执行慢,为什么? |
| ANSWER: 要删除表里面的全部数据时,请使用truncate delete 执行的并非单纯的删除,建议去了解一下undo、redo的相关机制,update也是同理。 |
| LINK:https://ask.csdn.net/questions/7675674?answer=53737474 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675727 |
| ANSWER_ID:53737448 |
| TITLE:如何创建一个小吃的数据库 |
| ANSWER: 如何创建不重要,重要的是你想做成什么样子,如果想不出,你可以先拿个excel表格填一填,第一列为小吃id,第二列为小吃名称,第一行为小吃的各个属性名称,想得差不多了,数据库里的表就可以照着这个样子建了 |
| LINK:https://ask.csdn.net/questions/7675727?answer=53737448 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675766 |
| ANSWER_ID:53737410 |
| TITLE:Oracle12,用PLSQL Developer可以正常连接,用ado或DB Tools Open Connection VI 访问都是都出错 |
| ANSWER: 有两种方式,使用oracle官方提供的新版ODAC或ODBC驱动,这需要到oracle官网下载 MFC ADO连接Oracle12c数据库 客户端环境搭建 - 偶不是大叔 - 博客园 ADO连接方式一:Provider=MSDAORA.1; 环境配置如下: 去官网下载ODAC121024Xcopy_32bit.zip安装 安装方式如下: (1)解压文件 (2)用命令行CD到该文件的 https://www.cnblogs.com/fuge/p/5341968.html |
| LINK:https://ask.csdn.net/questions/7675766?answer=53737410 |
| SOURCE:CSDN_ASK | ||||||
| ASK_ID:7675857 | ||||||
| ANSWER_ID:53737388 | ||||||
| TITLE:python读取mysql生成excel然后以html形式在邮件正文发送邮件 | ||||||
| ANSWER: 你是不是用了啥EXCEL转换成HTML的组件?这完全没必要啊,HTML的表格语法很简单的,你直接读出数据然后循环去拼标签就行了,你想让表格长啥样就能长啥样 比如下面这段html代码 下面是展示效果
| ||||||
| LINK:https://ask.csdn.net/questions/7675857?answer=53737388 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675936 |
| ANSWER_ID:53737362 |
| TITLE:就是怎么去吧11239这五位数字的排列组合一一的显示出来 |
| ANSWER: 有没有要求用什么语言代码实现?
结果不重复的有60个,如果那两个1要当成不一样的,把distinct去掉,就是120个 |
| LINK:https://ask.csdn.net/questions/7675936?answer=53737362 |

| SOURCE:CSDN_ASK |
| ASK_ID:7676028 |
| ANSWER_ID:53737284 |
| TITLE:怎么设置数据表的bit数据类型? |
| ANSWER: 数据库里面存的是什么值就是什么值,没有所谓的存是一个值显式又是另一个值了,因为数据库本身并不提供"显示"功能,"显示"都是由数据库外的其他工具来负责的. 一般来说,如果一个字段要存"真假" 类型的数据,大多数情况下是直接设置成整形,用1和0来表示,有些数据库支持BOOLEAN类型字段,当然也可以直接使用,但这在其他语言开发时可能会要进行一些特殊处理。另外,如果要求不严格,也是可以直接存成'Y/N'或者'及格/不及格'的字符串,但这样就增大了需要的存储空间,而且查询效率也会变低,因此还是建议用1和0来表示 另外,可以在sql里对值进行转换处理 |
| LINK:https://ask.csdn.net/questions/7676028?answer=53737284 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676054 |
| ANSWER_ID:53737263 |
| TITLE:为什么总提示我的派生表不存在,我的括号什么的都检查没错了,求经验丰富的同志解答 |
| ANSWER: 子查询只能在包住它的上一层select里使用,不能再其他地方使用,更加不能再select这个子查询的别名。
如果不使用开窗函数的话,就用下面这个
|
| LINK:https://ask.csdn.net/questions/7676054?answer=53737263 |


| SOURCE:CSDN_ASK |
| ASK_ID:7675942 |
| ANSWER_ID:53737214 |
| TITLE:postgre数据库sql查询中,如何使一个id字段等于一个id的列表 |
| ANSWER: 你贴的这个sql对解答这个问题貌似没有任何帮助, 问题改了后清晰多了,这就一个简单的开窗函数运用问题,把一个表里下一行的数据放到本行。 开窗函数lead,是可以使用partition by 关键词来进行分组的,也就是说可以按照路程号分组,每组之间的数据并不会出现交叉, |
| LINK:https://ask.csdn.net/questions/7675942?answer=53737214 |
| SOURCE:CSDN_ASK |
| ASK_ID:7676030 |
| ANSWER_ID:53737192 |
| TITLE:手机可以在不使用浏览器的情况下实现浏览网站吗? |
| ANSWER: 你在"我的电脑"的地址栏输入网址后回车,其实也是打开的网页浏览器,相当于你把网址保存成了一个快捷方式,然后双击打开这个快捷方式一个效果,它并不能在资源管理器中直接浏览网页。 |
| LINK:https://ask.csdn.net/questions/7676030?answer=53737192 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675363 |
| ANSWER_ID:53736266 |
| TITLE:怎么用jupyter notebook 绘制词云图 |
| ANSWER: pip安装wordcloud和jieba这两个包 然后再找个例子稍微改改就行了 Python之wordcloud库使用_jinsefm的博客-CSDN博客_python wordcloud 概述 wordcloud是优秀的词云展示第三方库,以词语为基本单位,通过图形可视化的方式,更加直观和艺术的展示文本。 库安装 网络正常情况下命令行输入pip install wordcloud,如果提示报错按以下步骤进行安装pip安装wordcloud过程中提示pip工具版本低,需pip-10.0.1版本,需先更新pip包管理工具python -m pip ... https://blog.csdn.net/jinsefm/article/details/80645588
这个是我用上面这篇文章的代码在本机测试的 至于在python里怎么读取文本文件内容作为字符串,这个就是基础知识了,与wordcloud怎么用没啥关系 |
| LINK:https://ask.csdn.net/questions/7675363?answer=53736266 |

| SOURCE:CSDN_ASK |
| ASK_ID:7675275 |
| ANSWER_ID:53736148 |
| TITLE:请问这个sql还能怎么优化 |
| ANSWER: 把这3个表的表结构贴出来看看, 此时再要提升查询效率就应该从索引上着手了 |
| LINK:https://ask.csdn.net/questions/7675275?answer=53736148 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675353 |
| ANSWER_ID:53736139 |
| TITLE:sql 查询 省略毫秒 通过分查询显示结果 |
| ANSWER: 一般有两种方式,使用范围条件 ,或者对字段进行格式化 一般推荐使用范围查询的方式,因为对字段进行格式化会影响查询效率。 |
| LINK:https://ask.csdn.net/questions/7675353?answer=53736139 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675214 |
| ANSWER_ID:53735993 |
| TITLE:oracle把一个字段按逗号拆开 |
| ANSWER: 用正则截取加递归
另外一种截取方式和另外一种递归方式
|
| LINK:https://ask.csdn.net/questions/7675214?answer=53735993 |


| SOURCE:CSDN_ASK |
| ASK_ID:7675112 |
| ANSWER_ID:53735879 |
| TITLE:pgsql正则表达式匹配数字问题 |
| ANSWER: 你原始数据长什么样?能不能举个例子?
|
| LINK:https://ask.csdn.net/questions/7675112?answer=53735879 |

| SOURCE:CSDN_ASK |
| ASK_ID:7675149 |
| ANSWER_ID:53735874 |
| TITLE:如何实现SQL语句查询表字段'相同的值'给展示出来,注意,在头部的查询功能依然可以查出该字段'其他的值'。 |
| ANSWER: 你所谓的头部查询功能,是不是出现一个值列表让用户选择?但这个值列表本身不就应该也是个单独的查询么? 当然如果有单独的用户表更好。 下拉框中的值和查询数据本体应该设计成两个不同的sql,所有的报表都应如此。页面打开后直接发起下拉框中sql的查询,获得下拉框的值,然后用户选择一个值,再点击查询,此时发起报表本体的查询sql。 |
| LINK:https://ask.csdn.net/questions/7675149?answer=53735874 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675161 |
| ANSWER_ID:53735861 |
| TITLE:我又来问问题了,这次是这个错误 |
| ANSWER: 在insert 语句中,如果不在表后面指定字段顺序,那么就会按照默认字段顺序将你的values值插进去, |
| LINK:https://ask.csdn.net/questions/7675161?answer=53735861 |
| SOURCE:CSDN_ASK |
| ASK_ID:7675169 |
| ANSWER_ID:53735854 |
| TITLE:DATAGRIP的备注问题 |
| ANSWER: 数据库版本不一致,你看的视频应该是8.0的,但你数据库是低于8.0的
|
| LINK:https://ask.csdn.net/questions/7675169?answer=53735854 |


| SOURCE:CSDN_ASK |
| ASK_ID:7675060 |
| ANSWER_ID:53735672 |
| TITLE:oracle查询一直执行中 |
| ANSWER: 查看后台是否存在该会话,会话当前的等待事件是什么 |
| LINK:https://ask.csdn.net/questions/7675060?answer=53735672 |
| SOURCE:CSDN_ASK |
| ASK_ID:7674683 |
| ANSWER_ID:53735549 |
| TITLE:help .openGauss |
| ANSWER: 这个报错只能说明你这个ip和端口上并没有在运行的数据库 |
| LINK:https://ask.csdn.net/questions/7674683?answer=53735549 |
| SOURCE:CSDN_ASK |
| ASK_ID:7674725 |
| ANSWER_ID:53735545 |
| TITLE:asp怎么用OpenDataSource插入数据到sql数据库中? |
| ANSWER: 把你这个数据库里的wycy002这个表的表结构贴出来看看,肯定是列名不匹配,比如有大小写区分 你的sql是 INSERT INTO wycy002 (jh,rq,scsj,rzsl,rpzsl) 你先登录到数据库里,单独执行一下insert语句后面的那个查询看看,另外,那个文件地址你自己确认一下准确性 |
| LINK:https://ask.csdn.net/questions/7674725?answer=53735545 |
| SOURCE:CSDN_ASK |
| ASK_ID:7674825 |
| ANSWER_ID:53735534 |
| TITLE:为什么安装虚拟机和iso文件后,仍然打不开虚拟机? |
| ANSWER: 因为你设置了这个
要支持硬件加速的话,需要进主板BIOS,开启VT-X虚拟化 |
| LINK:https://ask.csdn.net/questions/7674825?answer=53735534 |

| SOURCE:CSDN_ASK |
| ASK_ID:7674853 |
| ANSWER_ID:53735528 |
| TITLE:ORACLE:为何经过计算或判断的数值全部变为字符串类型? |
| ANSWER: 建议你把你的完整使用场景说明一下,你可能对这个东西有所误解
|
| LINK:https://ask.csdn.net/questions/7674853?answer=53735528 |

| SOURCE:CSDN_ASK |
| ASK_ID:7674862 |
| ANSWER_ID:53735511 |
| TITLE:请问这个SQL查出来的结果是什么 |
| ANSWER: 这个sql一看上去就一股违和感,它的常规写法应该是这样的 这个sql和你的sql查出来的结果应该是一样的,但是这个sql可能会比你的sql查询效率要高一点,因为我这个是先过滤数据再聚合,而你的是先聚合再过滤数据 |
| LINK:https://ask.csdn.net/questions/7674862?answer=53735511 |
| SOURCE:CSDN_ASK |
| ASK_ID:7674882 |
| ANSWER_ID:53735473 |
| TITLE:mysql 获取每个时间段之间的某条数据 |
| ANSWER: 题目没有说要不要根据线路分组,下面这个sql是取每条线路每个小时的第一条
如果不要按线路分组,把开窗函数里的linenumber干掉就是了 |
| LINK:https://ask.csdn.net/questions/7674882?answer=53735473 |

| SOURCE:CSDN_ASK |
| ASK_ID:7674887 |
| ANSWER_ID:53735460 |
| TITLE:ORACLE 中如何取到自己想要的数据 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7674887?answer=53735460 |

| SOURCE:CSDN_ASK |
| ASK_ID:7674527 |
| ANSWER_ID:53734843 |
| TITLE:【MySQL】如何在多表查询语句中加入字段,并让该字段的值根据其他字段的值显示不同的内容 |
| ANSWER: 这个具体要看你这个新字段和原来某字段之间的转换规则, |
| LINK:https://ask.csdn.net/questions/7674527?answer=53734843 |
| SOURCE:CSDN_ASK |
| ASK_ID:7674424 |
| ANSWER_ID:53734788 |
| TITLE:关于Oracle数据库的问题 |
| ANSWER: CREATE TABLE  https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/CREATE-TABLE.html#GUID-F9CE0CC3-13AE-4744-A43C-EAC7A71AAAB6
简单来说,在create table的语法中,字段的默认值可以为很多东西,但是不能为另一个列(序列伪列除外)。
|
| LINK:https://ask.csdn.net/questions/7674424?answer=53734788 |

| SOURCE:CSDN_ASK |
| ASK_ID:7674279 |
| ANSWER_ID:53734611 |
| TITLE:sql 语句查询计算 等问题 |
ANSWER:
如果只使用一个变量日期,那么可以根据这个变量来计算出对应的月初和月末是哪一天,把对应的计算表达式放到上面的sql中即可 SQLSERVER有坑,除数为0时不会直接报错,而是输出不完整的数据,因此需要使用case when先判断一下除数是否为0 |
| LINK:https://ask.csdn.net/questions/7674279?answer=53734611 |

| SOURCE:CSDN_ASK |
| ASK_ID:7674229 |
| ANSWER_ID:53734532 |
| TITLE:sql 查询语句 查询部门路径的问题 |
| ANSWER: 从题目上来看, 当前的部门名称为"1级.2级.3级",想查询出"1级》2级》3级"。 |
| LINK:https://ask.csdn.net/questions/7674229?answer=53734532 |
| SOURCE:CSDN_ASK |
| ASK_ID:7673199 |
| ANSWER_ID:53734503 |
| TITLE:使用CDN加速无法访问wordpress后台 |
| ANSWER: 有很多种方法,比如下面三种
|
| LINK:https://ask.csdn.net/questions/7673199?answer=53734503 |
| SOURCE:CSDN_ASK |
| ASK_ID:7673998 |
| ANSWER_ID:53734481 |
| TITLE:想要内录电脑音频竟然没有立体声混音 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7673998?answer=53734481 |


| SOURCE:CSDN_ASK |
| ASK_ID:7674134 |
| ANSWER_ID:53734472 |
| TITLE:朋友们,救帮助!这路由器设置该怎样调才能使网速最快最好?(操作系统-ubuntu) |
| ANSWER: 你图上这几个数值的话,最好是保持出厂自带的参数设置,最多改个穿墙。 |
| LINK:https://ask.csdn.net/questions/7674134?answer=53734472 |
| SOURCE:CSDN_ASK |
| ASK_ID:7674192 |
| ANSWER_ID:53734467 |
| TITLE:虚拟机无法使用,该怎么操作 ,为什么会报错啊 |
| ANSWER: 先把这玩意解压看看,看看文件类型是什么,如果是iso就没问题
你图上选择的那个文件后缀是个"downloading",这个是下载器下载还未完成的文件,不能直接使用的 |
| LINK:https://ask.csdn.net/questions/7674192?answer=53734467 |

| SOURCE:CSDN_ASK |
| ASK_ID:7674175 |
| ANSWER_ID:53734458 |
| TITLE:MySQL,为啥老是报错,我不知道哪里出错了 |
| ANSWER: 尝试将字段名使用重音符号包起来,比如 注意这个不是引号,是键盘左上角的,数字1旁边的那个点 |
| LINK:https://ask.csdn.net/questions/7674175?answer=53734458 |
| SOURCE:CSDN_ASK |
| ASK_ID:7674139 |
| ANSWER_ID:53734403 |
| TITLE:为什么SparkSQL,dbeaver,hive命令行使用相同的语句操作hive表的结果不一样 |
ANSWER:
以上主要是考虑重音符号及sql保留关键词在各sql语法解析中的兼容性问题 |
| LINK:https://ask.csdn.net/questions/7674139?answer=53734403 |
| SOURCE:CSDN_ASK |
| ASK_ID:7674111 |
| ANSWER_ID:53734394 |
| TITLE:SQL查询语句的问题统计 |
| ANSWER: 问sql题请提供一下数据库类型及版本。 |
| LINK:https://ask.csdn.net/questions/7674111?answer=53734394 |
| SOURCE:CSDN_ASK |
| ASK_ID:7673944 |
| ANSWER_ID:53734385 |
| TITLE:导入别人的.sql文件十几个表只成功了四个表,其余都显示1146和1064错误,如何解决? |
| ANSWER: 楼上说得对,你sql文件语法有问题,建议把sql文件内容发出来看看,尤其是建表的sql。 |
| LINK:https://ask.csdn.net/questions/7673944?answer=53734385 |
| SOURCE:CSDN_ASK |
| ASK_ID:7673916 |
| ANSWER_ID:53734382 |
| TITLE:数据库mysql worbench用eer图生成代码报错 |
| ANSWER: 你看看你的mysql版本是多少,创建索引时的VISIBLE关键词是mysql 8.0才增加的,具体可参考官方文档 MySQL :: MySQL 8.0 Reference Manual :: 8.3.12 Invisible Indexes https://dev.mysql.com/doc/refman/8.0/en/invisible-indexes.html 一般默认就是VISIBLE,所以如果是老版本,把这玩意去掉就行了 |
| LINK:https://ask.csdn.net/questions/7673916?answer=53734382 |
| SOURCE:CSDN_ASK |
| ASK_ID:7673794 |
| ANSWER_ID:53734374 |
| TITLE:SQL top3 语句查询前三个数据,出来的数据却是倒数三个数据 |
| ANSWER: "top 3" 指的是排序取前3,并不是最大的3个值。 |
| LINK:https://ask.csdn.net/questions/7673794?answer=53734374 |
| SOURCE:CSDN_ASK |
| ASK_ID:7673828 |
| ANSWER_ID:53734367 |
| TITLE:不同过滤维度(筛选条件)下的日活跃度的数据模型是怎么样的? |
| ANSWER: 原始数据肯定是有明细,然后可以根据不同维度建立单一维度或者多个维度的汇总表; 这里在效率以及数据准确性上要做个取舍,用下面这个sql做汇总表,肯定比你原表效率要高,但是并非绝对准确,不过既然一天之内跨城市或多设备使用的用户很少,那么这种用户对这个数据的影响也就不会很大。 另外一种方式,以 日期、uid 两个字段作为唯一键,将城市、设备、运营商三者的所有值全部展开成列,值为1时表示是,空表示否,查询时根据不同的条件来指定不同的字段进行查询,这样表的行数也可以大大减少,但是由于城市数过多,很有可能超过列数上限。考虑到一天内一个用户很少跨城市,那么也可以把这个方案修改成日期、uid、城市三个字段作为唯一键,把设备和运营商的所有值展开成列 |
| LINK:https://ask.csdn.net/questions/7673828?answer=53734367 |
| SOURCE:CSDN_ASK |
| ASK_ID:7673584 |
| ANSWER_ID:53733821 |
| TITLE:为什么我的table表格不居中? |
| ANSWER: text-align 这个是针对文本的,设置成center表示文本居中,从图上来看,你文本的确都在每个单元格中间 |
| LINK:https://ask.csdn.net/questions/7673584?answer=53733821 |
| SOURCE:CSDN_ASK |
| ASK_ID:7673455 |
| ANSWER_ID:53733681 |
| TITLE:第一次配置mysql,已经启动后输入mysql -u root -p,出现enter password 是什么意思 |
| ANSWER: 这是让你输入密码,你截图的教程里也有这个enter password |
| LINK:https://ask.csdn.net/questions/7673455?answer=53733681 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672879 |
| ANSWER_ID:53733038 |
| TITLE:SQL 递回 写法(OLD 及 NEW) |
| ANSWER: 下面是sqlserver版本
|
| LINK:https://ask.csdn.net/questions/7672879?answer=53733038 |

| SOURCE:CSDN_ASK |
| ASK_ID:7672849 |
| ANSWER_ID:53732983 |
| TITLE:写了个批处理脚本,但不知道问题出在哪里 |
| ANSWER: 子程序里面加一行代码,切换执行目录到本文件所在目录 |
| LINK:https://ask.csdn.net/questions/7672849?answer=53732983 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672843 |
| ANSWER_ID:53732975 |
| TITLE:sql怎么把这个两个放到同一语句里啊? |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7672843?answer=53732975 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672704 |
| ANSWER_ID:53732898 |
| TITLE:有没有人知道怎么查看b站上某一标签下的视频总数 |
| ANSWER: B站视频下面的标签有两种,一种是话题,一种是搜索关键词
上面的前两个就是话题,点进去可以直接看到视频总数;
|
| LINK:https://ask.csdn.net/questions/7672704?answer=53732898 |

| SOURCE:CSDN_ASK |
| ASK_ID:7672550 |
| ANSWER_ID:53732687 |
| TITLE:求,ora-18008 无法找到outln方案 |
| ANSWER: Oracle-11g 数据库启动时,报错"ORA-01092"及"ORA-18008: cannot find OUTLN schema" - autopenguin - 博客园 适用情形: Oracle-11g 数据库启动时,出现类似如下错误。 ORA-01092: ORACLE instance terminated. Disconnection forced ORA-18 https://www.cnblogs.com/autopenguin/p/6149304.html |
| LINK:https://ask.csdn.net/questions/7672550?answer=53732687 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672513 |
| ANSWER_ID:53732676 |
| TITLE:这个表,能你们有思路做吗 |
| ANSWER: 不知道这么直白的东西还需要什么思路。。。这压根就不算题目啊
|
| LINK:https://ask.csdn.net/questions/7672513?answer=53732676 |

| SOURCE:CSDN_ASK |
| ASK_ID:7672354 |
| ANSWER_ID:53732467 |
| TITLE:数据库存在该数据但查询时不显示数据 |
| ANSWER: 你把你select 后面的字段的单引号去掉就行了。 |
| LINK:https://ask.csdn.net/questions/7672354?answer=53732467 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672316 |
| ANSWER_ID:53732459 |
| TITLE:php8.1怎么连接oracle10g |
| ANSWER: oracle高版本客户端是兼容低版本数据库的,不需要特意去用低版本客户端。而且高版本客户端还解决了不少低版本客户端中的bug |
| LINK:https://ask.csdn.net/questions/7672316?answer=53732459 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671923 |
| ANSWER_ID:53732454 |
| TITLE:JDBC update时通过?指定要修改的列名? |
| ANSWER: 你的问号是个sql绑定变量,变量是不能作为关键词、对象名、字段名等信息的。 |
| LINK:https://ask.csdn.net/questions/7671923?answer=53732454 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671969 |
| ANSWER_ID:53732443 |
| TITLE:关于#大数据#的问题,如何解决? |
| ANSWER: 先要了解你需要监控的设备是否提供数据采集接口,一般不同的设备接口都不一样,这里就可能需要做不少开发了, |
| LINK:https://ask.csdn.net/questions/7671969?answer=53732443 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672102 |
| ANSWER_ID:53732405 |
| TITLE:最近分析一个文件,应该是一个数据库,但不清楚是什么数据库,能看看是什么类型的吗? |
| ANSWER: 这应该是某款空间设计软件保存的图纸信息,因为从这个文件内容上来看,很像是室内装修设计的信息. |
| LINK:https://ask.csdn.net/questions/7672102?answer=53732405 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672121 |
| ANSWER_ID:53732321 |
| TITLE:如何避免小数点带来的误差 |
| ANSWER: 这个东西,在进销存系统中及财务系统中是有专门的科目来进行处理的,一般叫做库存进价调整或者成本调整。 【零售知识】商品库存成本计算的几种方式_DarkAthena的博客-CSDN博客 首先,我们要对库存帐有个概念假设初始库存数量为5,然后进了一批货,数量为10,那么进货后,库存数量就变成15了;假设初始库存成本总金额为50,然后进了一批货,进货总成本为100,那么进货后,库存成本总金额就是150了;也就是说,不论是库存数量,还是库存成本总额,都会满足期初±发生=期末所以无论是以下那种计算方式,最终都必须满足这个原则I.计算方式概述... https://darkathena.blog.csdn.net/article/details/120670484
|
| LINK:https://ask.csdn.net/questions/7672121?answer=53732321 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672126 |
| ANSWER_ID:53732309 |
| TITLE:为什么以开窗函数倒序排序了,在前端没有排序 |
| ANSWER: 首先,你这个写法的意思是,针对每一组t.shop和t.spu来进行排序,也就是说原始数据中 ,一个t.shop和一个t.spu 有多行记录,如果只有一行记录,那这个排序就没意义了。 |
| LINK:https://ask.csdn.net/questions/7672126?answer=53732309 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672211 |
| ANSWER_ID:53732291 |
| TITLE:MySQL use库的问题 |
| ANSWER: 你第一行已经使用 DELIMITER 把结束符号定义成了 "//",导致它无法识别分号作为结束符了。 |
| LINK:https://ask.csdn.net/questions/7672211?answer=53732291 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672243 |
| ANSWER_ID:53732286 |
| TITLE:sql表设计时使某字段值等于另外一个字段的值怎么写? |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7672243?answer=53732286 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672256 |
| ANSWER_ID:53732282 |
| TITLE:关于刚学数据建立数据库的问题不知道咋办了! |
| ANSWER: 请把你运行的代码贴出来 |
| LINK:https://ask.csdn.net/questions/7672256?answer=53732282 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672267 |
| ANSWER_ID:53732279 |
| TITLE:Oracle存储过程在添加的时候判断表里有没有相同的id怎么写 |
| ANSWER: 报错的原因是因为你的 num 参数 是个 "in" 的,只能由外部传入,不能赋值,除非设置成 "in out" |
| LINK:https://ask.csdn.net/questions/7672267?answer=53732279 |
| SOURCE:CSDN_ASK |
| ASK_ID:7672273 |
| ANSWER_ID:53732258 |
| TITLE:SQL语句怎么给smalldatetime添加check约束 |
| ANSWER: 你是不是日期没打引号,导致它把中间的横杠当成减号了
|
| LINK:https://ask.csdn.net/questions/7672273?answer=53732258 |

| SOURCE:CSDN_ASK |
| ASK_ID:7671846 |
| ANSWER_ID:53731529 |
| TITLE:请教,一个每天更新的全量表,求按照DS分区时间来统计每天更新的表内一共多少条数据 |
| ANSWER: 你的sql只有20220323的数据是因为有这个条件 今天是 20220324,减1天自然就是20220323了。 你想要的查询条件到底是静态的 "0320~0323" ?还是会跟着日期一起变的动态时间范围?如果是动态的,那么这个动态范围的规则是什么?
|
| LINK:https://ask.csdn.net/questions/7671846?answer=53731529 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671845 |
| ANSWER_ID:53731515 |
| TITLE:mysql到最后一步安装不上 |
| ANSWER: 安装前,建议先关掉所有杀毒软件 |
| LINK:https://ask.csdn.net/questions/7671845?answer=53731515 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671840 |
| ANSWER_ID:53731512 |
| TITLE:字符串格式化的时候报错ValueError: NaTType does not support strftime,如何解决? |
| ANSWER: to_datetime是指将字符串按照指定的格式转换成日期时间,这个格式必须和原字符串匹配,
|
| LINK:https://ask.csdn.net/questions/7671840?answer=53731512 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671808 |
| ANSWER_ID:53731498 |
| TITLE:配置MySQL时出现问题 |
| ANSWER: 建议把你my.ini文件的内容贴出来看看 |
| LINK:https://ask.csdn.net/questions/7671808?answer=53731498 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671782 |
| ANSWER_ID:53731491 |
| TITLE:Linux是32位,安装了64位的hadoopmvn clean package -Pdist,native -DskipTests -Dta |
| ANSWER: 把你的maven源改一下,建议换成国内源,你这从国外下载速度太慢了,而且网络不稳定,你目前这个现象应该就是网络卡住了,再等个一段时间应该就会提示网络连接失败之类的了 Maven镜像配置后仍然从(http://repo.maven.apache.org/maven2)下载的问题_吃客567的博客-CSDN博客 Maven镜像配置后仍然从(http://repo.maven.apache.org/maven2)下载的问题摘抄自《配置了maven的国内镜像后,问题:(https://repo.maven.apache.org/maven2): Not authorized , ReasonPhrase:Authorizatio》一.问题:最近学习springboot,从网上导入工程后,都出现maven无法下载相关资源的问题。二.解决思路如下:1.怀疑是网络限制的原因,故在网上找了相关的解决方案, https://blog.csdn.net/qq_34988196/article/details/109044912 |
| LINK:https://ask.csdn.net/questions/7671782?answer=53731491 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671780 |
| ANSWER_ID:53731486 |
| TITLE:数据集A已知一批坐标的经纬度,数据集B已知全国三级市县的经纬度,如何通过SQL语句筛选出属于A中属于重庆的数据 |
| ANSWER: 问sql题请提供原表的create table 命令及模拟的insert 数据,以及最终需要的输出格式。否则没人知道该怎么对着空气写sql |
| LINK:https://ask.csdn.net/questions/7671780?answer=53731486 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671701 |
| ANSWER_ID:53731405 |
| TITLE:HiveServer2Error('Invalid OperationHandle: OperationHandle [opType=EXECUTE_STATEMENT |
| ANSWER: 加一行代码,把 arraysize 设置成 1 |
| LINK:https://ask.csdn.net/questions/7671701?answer=53731405 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671646 |
| ANSWER_ID:53731398 |
| TITLE:初始化hive报错 dbType myaql |
| ANSWER: 你看看你的 dbType 参数是不是写错了,没有myaql这种数据库类型的 ,最接近的应该是 mysql |
| LINK:https://ask.csdn.net/questions/7671646?answer=53731398 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671638 |
| ANSWER_ID:53731395 |
| TITLE:hbase的查询是不是只能查询出值不为空的字段 |
| ANSWER: hbase可以查询空值 ,使用 NullComparator ,具体可参考这篇文章 HBase Filter 过滤器之 Comparator 原理及源码学习_禅克的博客-CSDN博客_hbase regexstringcomparator 前言:上篇文章HBase Filter 过滤器概述对HBase过滤器的组成及其家谱进行简单介绍,本篇文章主要对HBase过滤器之比较器作一个补充介绍,也算是HBase Filter学习的必备低阶魂技吧。本篇文中源码基于HBase 1.1.2.2.6.5.0-292 HDP版本。HBase所有的比较器实现类都继承于父类ByteArrayComparable,而ByteArrayComparab... https://blog.csdn.net/weixin_42047967/article/details/105757146 |
| LINK:https://ask.csdn.net/questions/7671638?answer=53731395 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671628 |
| ANSWER_ID:53731389 |
| TITLE:请大家看一眼是哪有错误,字段名和表名是没错的。 |
| ANSWER: 最近有好多人在问类似的问题,你们是不是遇到了同一个老师哦,版本都没做要求 关于使用开窗函数报错的问题(求解决方案,提问帖)-大数据-CSDN问答 CSDN问答为您找到关于使用开窗函数报错的问题(求解决方案,提问帖)相关问题答案,如果想了解更多关于关于使用开窗函数报错的问题(求解决方案,提问帖) mysql、数据库 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7670460?answer=53729650&spm=1001.2014.3001.5504 关于MySQL中RANK()函数报错-大数据-CSDN问答 CSDN问答为您找到关于MySQL中RANK()函数报错相关问题答案,如果想了解更多关于关于MySQL中RANK()函数报错 mysql、sql、数据库、 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7670376?answer=53729520&spm=1001.2014.3001.5504 |
| LINK:https://ask.csdn.net/questions/7671628?answer=53731389 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671543 |
| ANSWER_ID:53731137 |
| TITLE:sql更新数据内容过长自动截取问题 |
| ANSWER: 问题不够详细,既没说明是什么数据库,也没说明是个什么场景
|
| LINK:https://ask.csdn.net/questions/7671543?answer=53731137 |

| SOURCE:CSDN_ASK |
| ASK_ID:7671473 |
| ANSWER_ID:53731119 |
| TITLE:hive hql 数据库近 7天 30天的 点击,展示 点击率 这个广告方面的 |
| ANSWER: 将每天的分子和分母分别求和,最后再除,这个是没问题的。 能不能弄个表格示意一下你最终需要的数据格式是什么样的么? |
| LINK:https://ask.csdn.net/questions/7671473?answer=53731119 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671430 |
| ANSWER_ID:53731089 |
| TITLE:mysql如何为视图添加备注等等一些注释信息,他生成出来那个默认的View我想改成别的 |
| ANSWER: 根据mysql官方文档的语法来看,不支持在创建视图的同时添加注释 并且在视图创建好后,也无法进行修改,因为视图上根本就没有"注释"这个属性 mysql诞生至今这几十年,有很多人向官方反馈过,但MYSQL都没打算支持给视图添加注释 |
| LINK:https://ask.csdn.net/questions/7671430?answer=53731089 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671425 |
| ANSWER_ID:53731061 |
| TITLE:Oracle创建定时器报错 |
| ANSWER: 你存储过程要求传入两个参数,但是job的what里面又没传,当然会报错了,要改成下面这样 这个与时间类型加减没关系,oracle的date类型本就可以加减,sysdate+1表示当前时间加1天 提示对象无效
你回复的这个一眼就能看出错误呀,你没有声明ResultStr这个变量,怎么能给它赋值呢?而且你这个赋值本身没有任何意义呀,既不打印又不输出,为什么不删掉这一行呢? 上面这个语法就没错了,就是不知道你表名和字段名是不是对的, |
| LINK:https://ask.csdn.net/questions/7671425?answer=53731061 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671208 |
| ANSWER_ID:53730838 |
| TITLE:Sql根据条件判断,分别执行不同的查询并返回结果集 |
| ANSWER: 首先,你这问题标签写了两个数据库,到底是想在哪个数据库里实现这样的功能呢?不同数据库支持的功能不一样,语法也有很多区别。 查同一个表的话,用or来处理条件就好了 |
| LINK:https://ask.csdn.net/questions/7671208?answer=53730838 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671291 |
| ANSWER_ID:53730820 |
| TITLE:树形结构数据有其中一个节点怎么找他的整个分支 |
| ANSWER: 请先说明一下你的数据库类型以及版本,不同数据库甚至同一数据库的不同版本的递归sql都可能有区别 |
| LINK:https://ask.csdn.net/questions/7671291?answer=53730820 |
| SOURCE:CSDN_ASK |
| ASK_ID:7671292 |
| ANSWER_ID:53730817 |
| TITLE:sql server 2008R2怎么取一段时间每个月的最后一天 |
| ANSWER: 其实上个题就已经给你答案了,
|
| LINK:https://ask.csdn.net/questions/7671292?answer=53730817 |

| SOURCE:CSDN_ASK |
| ASK_ID:7670964 |
| ANSWER_ID:53730264 |
| TITLE:SQL中 cast的使用方法 |
| ANSWER: 其实你把它当英语的自然语言直接翻译就懂了 |
| LINK:https://ask.csdn.net/questions/7670964?answer=53730264 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670963 |
| ANSWER_ID:53730263 |
| TITLE:请同仁解释下关于数据库选择的这句话 |
| ANSWER: 它这里其实是针对两个指标的极端场景,即读写速度和稳定性,哪个优先级更高
如果有上面这两种数据库让他选择的话,他会选第一个 |
| LINK:https://ask.csdn.net/questions/7670963?answer=53730263 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670779 |
| ANSWER_ID:53730070 |
| TITLE:SQL查询同时选修了操作系统和数据库两门课的学生 |
| ANSWER:
你这个写法不是画蛇添足么? cname本来就是课程名称,你这段sql就等同于 cname='操作系统' ,同理,下面那段 等同于 cname='数据库' ,第三个sql就变成了 等价于 这个条件怎么可能查出数据嘛 要找出同时参与了指定两个课程的人,初学者的思路一般是先分别取得两个课程对应的姓名清单,然后再同时去in这两个姓名清单,但你这又变成了in课程,当然不对。 |
| LINK:https://ask.csdn.net/questions/7670779?answer=53730070 |

| SOURCE:CSDN_ASK |
| ASK_ID:7670725 |
| ANSWER_ID:53729956 |
| TITLE:SQL学习如何从网站下载 |
| ANSWER: 使用客户端工具连接数据库后,把这些代码全部复制到客户端里执行就是 |
| LINK:https://ask.csdn.net/questions/7670725?answer=53729956 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670577 |
| ANSWER_ID:53729836 |
| TITLE:analys安装报错 |
| ANSWER: 很明显文件名乱码了,导致程序没有找到这个文件。 |
| LINK:https://ask.csdn.net/questions/7670577?answer=53729836 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670572 |
| ANSWER_ID:53729834 |
| TITLE:这个怎么办啊!有人会吗 |
| ANSWER: 你有没有想过,"外键"为什么叫"外"键呢?它为什么不直接叫"键",而且也不叫"内键"? |
| LINK:https://ask.csdn.net/questions/7670572?answer=53729834 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670551 |
| ANSWER_ID:53729826 |
| TITLE:oracle没有正常启动,这两个毛病找了半天没解决,求帮助! |
| ANSWER: 参数设置有问题,"内存目标"比"内存最大目标"还大,建议先看一下这两个参数的值,然后使用alter命令进行适当调整 |
| LINK:https://ask.csdn.net/questions/7670551?answer=53729826 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670532 |
| ANSWER_ID:53729822 |
| TITLE:SqlServer跨库查询Oracle表数据中文乱码 |
| ANSWER: 把环境变量NLS_LANG修改成 SIMPLIFIED CHINESE_CHINA.ZHS16GBK 或者 SIMPLIFIED CHINESE_CHINA.AL32UTF8试试, 【ORACLE】谈一谈Oracle数据库使用的字符集,不仅仅是乱码_DarkAthena的博客-CSDN博客 一、前言先看一个比较有意思的案例上面这个sql,查询了a和b两个字段,均为"张三"两个汉字,并且使用length函数检查,长度均为2。但是,当你看到下面这几个sql的输出结果时,很有可能第一反应是:"这特喵的怎么可能?"其实,你所看到的两个"张三",的确长得是一模一样,用显微镜去看也不可能看到区别。但为什么a和b不相等呢?这是因为组成他们的成分不一样,这个成分就是 字符集二、什么是字符集?百度百科简单来说,字符(Character)是各种文字和符号的总称,包括各国家文字、标 https://darkathena.blog.csdn.net/article/details/122659532 --
我觉得你可能得先判断一下原始数据本身是不是已经出现字符集错误的情况了,plsqldev能正常显示,并不代表此时数据的字符集就是正确的,在我上面那篇文章中也有举例 |
| LINK:https://ask.csdn.net/questions/7670532?answer=53729822 |

| SOURCE:CSDN_ASK |
| ASK_ID:7670512 |
| ANSWER_ID:53729801 |
| TITLE:sql 语句怎么取一段时间每个月最后一天 |
| ANSWER: 这个要看一下sqlserver的版本,EOMONTH只能在 SQL Server 2012 (11.x)及以上版本执行,否则就要使用多个函数组合来实现取月底最后一天的效果了。
|
| LINK:https://ask.csdn.net/questions/7670512?answer=53729801 |

| SOURCE:CSDN_ASK |
| ASK_ID:7670405 |
| ANSWER_ID:53729656 |
| TITLE:怎样手动删除LocalDB里的数据 |
| ANSWER: 执行sql命令 这样就能删除这个表里面的全部数据了 |
| LINK:https://ask.csdn.net/questions/7670405?answer=53729656 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670460 |
| ANSWER_ID:53729650 |
| TITLE:关于使用开窗函数报错的问题(求解决方案,提问帖) |
| ANSWER:
MYSQL 8.0 版本,执行没有报错,不确定你说的”系统报错“是指数据库返回错误还是答题系统判断你的答案不对? |
| LINK:https://ask.csdn.net/questions/7670460?answer=53729650 |

| SOURCE:CSDN_ASK |
| ASK_ID:7670450 |
| ANSWER_ID:53729638 |
| TITLE:MySQL 查询某月一整月的数据 |
| ANSWER: 你前台传给后台的值是什么?"202204"还是 "2022-04" 还是"2022-04-01".....? |
| LINK:https://ask.csdn.net/questions/7670450?answer=53729638 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670449 |
| ANSWER_ID:53729626 |
| TITLE:关于sql 的连表查询 |
| ANSWER: 表关联并不需要表字段名称一样,重点是看表之间的逻辑关系,以及各字段的定义。 |
| LINK:https://ask.csdn.net/questions/7670449?answer=53729626 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670448 |
| ANSWER_ID:53729615 |
| TITLE:请问一下Pgsql连接时出现这个问题怎么解决? |
| ANSWER: 这个报错在问你,数据库服务目前是否正在运行?是不是在运行在你localhost的5432端口上? |
| LINK:https://ask.csdn.net/questions/7670448?answer=53729615 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670121 |
| ANSWER_ID:53729607 |
| TITLE:SqlServer通过Openquery调用Oracle中的存储过程得到一个select结果集 |
| ANSWER: 如果你把它改造成一个函数,return这个V_RESULT 是不是就能用select解决了? [sql server] 通过SQL Linked Server 执行Oracle 存储过程小结_永生天地的博客-CSDN博客 通过SQL Linked Server 执行Oracle 存储过程小结 1 举例 我们可以通过下面的方法在SQL Server中通过Linked Server 来执行Oracle 存储过程。 (1) Oracle Package PACKAGE Test_PACKAGE AS TYPE t_t is TABLE of VARCHAR2(30) INDEX BY BINARY_INTEGER; https://blog.csdn.net/xys_777/article/details/5711052 但是,你这么做应该达不到想要的目的,因为"REF CURSOR"这种类型并不是实实在在的数据,这种类型本身其实只相当于一个对象id,其数据还是在原数据库里,只能被原数据库使用。如果你想要得到数据,可以尝试使用表函数返回一个table类型,这样就能当成普通的select语句使用了,直接查询出来也是一个表格 |
| LINK:https://ask.csdn.net/questions/7670121?answer=53729607 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670174 |
| ANSWER_ID:53729552 |
| TITLE:mysql数据库创建表报错,不理解 |
| ANSWER:
建表要有表名,上图是在5.5版本的mysql中进行的测试,加上表名后就没有报错了 |
| LINK:https://ask.csdn.net/questions/7670174?answer=53729552 |

| SOURCE:CSDN_ASK |
| ASK_ID:7670375 |
| ANSWER_ID:53729542 |
| TITLE:hql语句的优化,广告方面的计算 hive hql 数据库 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7670375?answer=53729542 |
| SOURCE:CSDN_ASK |
| ASK_ID:7670376 |
| ANSWER_ID:53729520 |
| TITLE:关于MySQL中RANK()函数报错 |
| ANSWER: 在mysql 8.0版本,直接用你的脚本测试,没有报错
因此你mysql的版本可能是8以前的老版本,老版本不支持开窗函数的 |
| LINK:https://ask.csdn.net/questions/7670376?answer=53729520 |

| SOURCE:CSDN_ASK |
| ASK_ID:7670233 |
| ANSWER_ID:53729511 |
| TITLE:sqlserver 把这一句sql 从默认的周日到周6为一周的改成周三到下周2为一周的有人会改吗?求解决 |
| ANSWER: 这题你都问了4个版本了。。。 sql server中时间归不到这个时间段里,求解决-大数据-CSDN问答 CSDN问答为您找到sql server中时间归不到这个时间段里,求解决相关问题答案,如果想了解更多关于sql server中时间归不到这个时间段里,求解决 sql、sqlserver、数据库 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7670120?spm=1001.2014.3001.5505 sqlserver 周报 问题求解决,-大数据-CSDN问答 CSDN问答为您找到sqlserver 周报 问题求解决,相关问题答案,如果想了解更多关于sqlserver 周报 问题求解决, sql、sqlserver 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7669302?spm=1001.2014.3001.5505 这个问题不管小时,那么直接加3天就好了
|
| LINK:https://ask.csdn.net/questions/7670233?answer=53729511 |

| SOURCE:CSDN_ASK |
| ASK_ID:7670120 |
| ANSWER_ID:53729439 |
| TITLE:sql server中时间归不到这个时间段里,求解决 |
| ANSWER: 你这段代码写错了,dateadd函数输出的是日期,你在后面加个整数7是什么意思? 只要计算好偏差量,这玩意不是想怎么划区间都可以么?
|
| LINK:https://ask.csdn.net/questions/7670120?answer=53729439 |

| SOURCE:CSDN_ASK |
| ASK_ID:7665505 |
| ANSWER_ID:53728767 |
| TITLE:如何把网站和某些关键字进行绑定? |
| ANSWER: 上面有不少回答都已经说得很完整了,不知道为什么会有那么多人点无用。
bing无论是国际版还是国内版,我的网站都是关键词排行第一 于是我去百度站长客服中心提交了投诉,在等了一个月后,客服说之前技术那边出了问题,已经处理好了,然后我百度一搜,果然在百度排第一了。但是,一周后,在百度上又搜不到了!连翻十几页都没看到!就算是热度下降了,也不至于在短短一周内从第一名跌到看不到名次! |
| LINK:https://ask.csdn.net/questions/7665505?answer=53728767 |

| SOURCE:CSDN_ASK |
| ASK_ID:7669910 |
| ANSWER_ID:53728711 |
| TITLE:MySQL-flume -hdfs SLF4J: Defaulting to no-operation (NOP) logger implementation |
| ANSWER: 打开你这个报错中提到的链接,里面有说解决方案
意思就是slf4j-nop.jar slf4j-simple.jar, slf4j-log4j12.jar, slf4j-jdk14.jar or logback-classic.jar 这几个文件,只要放其中任意一个(只能有一个)到类的路径里就行了 |
| LINK:https://ask.csdn.net/questions/7669910?answer=53728711 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669842 |
| ANSWER_ID:53728643 |
| TITLE:hivesql 查询语句 字段+字段和 +分组条件 |
| ANSWER: 这题问得太有歧义了,楼上两位专家都出现截然不同的理解。
|
| LINK:https://ask.csdn.net/questions/7669842?answer=53728643 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669837 |
| ANSWER_ID:53728634 |
| TITLE:#怎么判断手机号和身份证是 一个人(关键词-验证手机号) |
| ANSWER: 你当前有什么数据?麻烦说明一下问题背景 |
| LINK:https://ask.csdn.net/questions/7669837?answer=53728634 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669600 |
| ANSWER_ID:53728605 |
| TITLE:数据库设计一定要用id做为主键吗?看到阿里规范上是这么说的 |
| ANSWER: 这种流水记录,不要使用时间作为主键, |
| LINK:https://ask.csdn.net/questions/7669600?answer=53728605 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669612 |
| ANSWER_ID:53728588 |
| TITLE:关于使用WITH语句创建临时表进行查询问题 |
| ANSWER: 这玩意判断下空值就好了,你这个sql "@折扣为NULL" 的时候,并不是折扣为0 ,出现的其实是全部的数据,因为满足你的查询条件 "@折扣 is null" |
| LINK:https://ask.csdn.net/questions/7669612?answer=53728588 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669666 |
| ANSWER_ID:53728582 |
| TITLE:sql group by分组去重问题 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7669666?answer=53728582 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669759 |
| ANSWER_ID:53728560 |
| TITLE:SQL server的datetime指定列宽 |
| ANSWER: 这个报错都已经用中文告诉你了,就是不能指定, |
| LINK:https://ask.csdn.net/questions/7669759?answer=53728560 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669753 |
| ANSWER_ID:53728553 |
| TITLE:【pgsql】select * into tab_b from tab_a 和Navicat里面的复制表有什么不同,内部具体执行是怎么样的? |
| ANSWER: pg是postgresql这个数据库的简称, Products | Navicat Read the full list of Navicat's products included Navicat, the best database administration tool, Navicat Monitor, Navicat Charts Creator, Navicat Collaboration and Navicat Data Modeler.  https://navicat.com/en/products 只要你连接的是同一个数据库的同一个版本,不管你用什么软件去连接管理它,语法都是一样的。 使用navicat一样可以连接pg数据库,使用菜单里的复制表功能,当然也可以用sql命令来执行
这个复制表功能不过就是个create table new_table as select * from old_table 命令罢了,如果是仅复制结构,只需要加一个条件 where 1=2
|
| LINK:https://ask.csdn.net/questions/7669753?answer=53728553 |

| SOURCE:CSDN_ASK |
| ASK_ID:7669515 |
| ANSWER_ID:53728299 |
| TITLE:问下各位sql server咋么在一张数据表中统计3个月数据 |
| ANSWER: 用开窗函数的滑动窗口,前2两行到当前行
需要注意的是,统计前两行数据所需要的数据由于已经被where过滤掉了,没统计到, |
| LINK:https://ask.csdn.net/questions/7669515?answer=53728299 |

| SOURCE:CSDN_ASK |
| ASK_ID:7669154 |
| ANSWER_ID:53728275 |
| TITLE:sql多对多数据横向合并 |
| ANSWER: 用开窗函数,给主修和选修分组排个序号,然后再根据序号和学号来关联,比如
用full join 的原因是,怕有人选修的科目比主修的还多 |
| LINK:https://ask.csdn.net/questions/7669154?answer=53728275 |

| SOURCE:CSDN_ASK |
| ASK_ID:7669494 |
| ANSWER_ID:53728240 |
| TITLE:请教mysql一个字段同时满足多个条件 |
| ANSWER: 用count来计数,判断是否等于3,类似下面这样 不是不可行,因为你并没有给全前提条件,建议你先把表结构和模拟数据放出来,上面这个sql里,count里还可以写条件的,只对满足要求的数据进行计数,甚至还可以去重,比如 |
| LINK:https://ask.csdn.net/questions/7669494?answer=53728240 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669302 |
| ANSWER_ID:53728231 |
| TITLE:sqlserver 周报 问题求解决, |
| ANSWER: sqlserver 周报问题 ,想获取这个月内所有的周报,求解决-大数据-CSDN问答 CSDN问答为您找到sqlserver 周报问题 ,想获取这个月内所有的周报,求解决相关问题答案,如果想了解更多关于sqlserver 周报问题 ,想获取这个月内所有的周报,求解决 mysql、后端 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7668215?spm=1001.2014.3001.5505 这次不分月了?
|
| LINK:https://ask.csdn.net/questions/7669302?answer=53728231 |

| SOURCE:CSDN_ASK |
| ASK_ID:7669471 |
| ANSWER_ID:53728170 |
| TITLE:无法连接上MySql |
| ANSWER: 已经连上了,这个报错提示的是sql语法错误
你的表里面没有id这个字段,因此不能在where条件中使用 |
| LINK:https://ask.csdn.net/questions/7669471?answer=53728170 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669447 |
| ANSWER_ID:53728131 |
| TITLE:pgsql查询出分组后的起始单号和截止单号 |
| ANSWER: 给个create table 和几行insert模拟数据出来,并用表格说明一下想要的数据结果格式 最容易想到的就是用开窗函数了,但你这没给结构,不确定是否还有未知因素 |
| LINK:https://ask.csdn.net/questions/7669447?answer=53728131 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669441 |
| ANSWER_ID:53728123 |
| TITLE:Mysql的安装问题 |
| ANSWER: 这是提醒你有依赖没有安装,就是你这个框框挡住的后面那两个玩意,应该是vs和python,建议先把那两个东西装了,反正可以用得上 |
| LINK:https://ask.csdn.net/questions/7669441?answer=53728123 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668959 |
| ANSWER_ID:53728112 |
| TITLE:group by加了一个字段“激活年月”,为什么加字段前的count(1)和加字段后的不一致 |
| ANSWER: 理论上,你两个sql中的count(1)字段,所有行求和后,结果是一样的, |
| LINK:https://ask.csdn.net/questions/7668959?answer=53728112 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669114 |
| ANSWER_ID:53728089 |
| TITLE:用一条sql查询平均工资,最高工资,最低工资,10号部门最高工资,20号部门最高工资 |
| ANSWER: 问sql题请提供create table 语句以及模拟数据,还有最终想要输出的数据格式及例子,
|
| LINK:https://ask.csdn.net/questions/7669114?answer=53728089 |

| SOURCE:CSDN_ASK |
| ASK_ID:7669358 |
| ANSWER_ID:53728067 |
| TITLE:sql语句查询一个字段后面有几个值,可以实现吗? |
| ANSWER: 建议使用case when 或者ifnull/isnull之类的方式判断后再相加, |
| LINK:https://ask.csdn.net/questions/7669358?answer=53728067 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669343 |
| ANSWER_ID:53728046 |
| TITLE:sql窗口运行,打开某个表时,中文字段显示不出汉字 |
| ANSWER: 打开cmd ,输入 回车,然后再连接mysql进行查询 |
| LINK:https://ask.csdn.net/questions/7669343?answer=53728046 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669263 |
| ANSWER_ID:53728037 |
| TITLE:建立非聚集索引后sql还是照常写吗? |
| ANSWER: 楼上回答有问题, |
| LINK:https://ask.csdn.net/questions/7669263?answer=53728037 |
| SOURCE:CSDN_ASK |
| ASK_ID:7669199 |
| ANSWER_ID:53728015 |
| TITLE:sqlldr执行脚本报错 错误信息如下 各位看看 |
| ANSWER: 你命令是咋执行的?你贴的这个不是可以直接执行的sql语句,这只是一个控制文件 sqlldr常见用法如下,你写的那个load data应该要放在control参数指定的文件内,而不是直接去执行它 |
| LINK:https://ask.csdn.net/questions/7669199?answer=53728015 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668816 |
| ANSWER_ID:53727033 |
| TITLE:请教!使用spyder连接MySQL数据库,提取一个字段显示不完整是什么情况T_T |
| ANSWER: 因为你这个工具的控制台只会显示最近的300条记录,超过300条就把前面的顶掉了。 |
| LINK:https://ask.csdn.net/questions/7668816?answer=53727033 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668686 |
| ANSWER_ID:53726926 |
| TITLE:win10系统,想连接的wifi在“管理已知网络”里怎么办? |
| ANSWER: 你看下你这个wifi信号是5Ghz的还是2.4Ghz的?然后你电脑是不是只能搜索到2.4Ghz的信号? |
| LINK:https://ask.csdn.net/questions/7668686?answer=53726926 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668505 |
| ANSWER_ID:53726656 |
| TITLE:统计用户产生换绑行为的数据 |
| ANSWER: 首先这个肯定是用lag开窗函数分组取上一行,
如果是这样,那为何在图二中,会出现两个用户名称?如果用户名称会被修改,此时如何确定它改之前是谁?此时图一中仅根据应用版本和平台是无法确认唯一用户的。如果用户名称不改,那么图一里变化的仅仅只有一个绑定时间了 另外,"换绑"到底是种什么操作?有哪几种场景?每种场景可能会修改什么信息? 题目改了后,这就是个最简单的lag开窗函数的应用场景了 |
| LINK:https://ask.csdn.net/questions/7668505?answer=53726656 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668215 |
| ANSWER_ID:53726629 |
| TITLE:sqlserver 周报问题 ,想获取这个月内所有的周报,求解决 |
| ANSWER: 其实你这个就是想按周来切分一个月份,可以使用datepart函数, 如果要写成查询条件的话
|
| LINK:https://ask.csdn.net/questions/7668215?answer=53726629 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668453 |
| ANSWER_ID:53726602 |
| TITLE:关于mysql的安装问题 |
| ANSWER: 上面那个勾勾上只是可能会让你当前这个列表里多显示几个数据库而已,实际不会影响你的操作结果,因为它只是在问你"要不要显示可能正在运行的只读数据库?" |
| LINK:https://ask.csdn.net/questions/7668453?answer=53726602 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668451 |
| ANSWER_ID:53726595 |
| TITLE:关于oracle数据库SQL语句问题 |
| ANSWER: 你写的存储过程代码有bug呗,没有考虑到所有场景 |
| LINK:https://ask.csdn.net/questions/7668451?answer=53726595 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668427 |
| ANSWER_ID:53726589 |
| TITLE:sql请教,谢谢你们的回答 |
| ANSWER: 看看是不是这个意思: 如果只是要查出不一样的数据,用下面这个 要找少了的数据的话,原表not exists 接口表就好了 |
| LINK:https://ask.csdn.net/questions/7668427?answer=53726589 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668370 |
| ANSWER_ID:53726523 |
| TITLE:Mysql where多条件 可能缺省如何写语句 |
| ANSWER: 判断每个条件其实不蠢,这样往数据库发送的sql更精简。写在sql里反而是偷懒的做法,比如下面这样 当传空值时,这个sql就会等价为 相当于没有a条件了,当然前提是你的a列的数据没有null值,如果有null值的话就还要再加点处理,比如 |
| LINK:https://ask.csdn.net/questions/7668370?answer=53726523 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668347 |
| ANSWER_ID:53726497 |
| TITLE:sql语句如何查询编码等于四位数字 |
| ANSWER: 看是什么数据库,一般用于判断长度的函数是 "length",但有的数据库是"len", |
| LINK:https://ask.csdn.net/questions/7668347?answer=53726497 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668337 |
| ANSWER_ID:53726494 |
| TITLE:请教oracle在同一SQL中多次跨库查询 |
| ANSWER: 要先在B库用dblink创建相关对象,比如同义词或者视图,然后再在A库来访问B库里创建的这个对象。 |
| LINK:https://ask.csdn.net/questions/7668337?answer=53726494 |
| SOURCE:CSDN_ASK |
| ASK_ID:7668218 |
| ANSWER_ID:53726486 |
| TITLE:sql语句创建表失败 |
| ANSWER: 没有这种语法
|
| LINK:https://ask.csdn.net/questions/7668218?answer=53726486 |

| SOURCE:CSDN_ASK | ||||||||||||
| ASK_ID:7668122 | ||||||||||||
| ANSWER_ID:53726472 | ||||||||||||
| TITLE:sql server 获取相邻日期范围问题 求解 | ||||||||||||
| ANSWER: 建议你以表格的形式说明一下你想要输出的数据格式,目前题目里描述得不是很清楚,实在没看出分组是在干啥。
但是也不清楚需求,是要去重还是要在原数据上增加一列,题目里已知信息太少了,建议把问题背景描述一下吧,思路别跑偏了 | ||||||||||||
| LINK:https://ask.csdn.net/questions/7668122?answer=53726472 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667918 |
| ANSWER_ID:53725639 |
| TITLE:Win11家庭版如何解决找不到文件gpedit.msc的问题? |
| ANSWER: 你在网上找的那个代码,要鼠标右键使用管理员模式运行才有用,下面这篇文章里就是在win11home版里演示的 |
| LINK:https://ask.csdn.net/questions/7667918?answer=53725639 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667794 |
| ANSWER_ID:53725620 |
| TITLE:oar-01017问题怎么解决? |
| ANSWER: 用户名或密码不正确,请确认有创建这个用户,以及密码是否正确。 |
| LINK:https://ask.csdn.net/questions/7667794?answer=53725620 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667773 |
| ANSWER_ID:53725612 |
| TITLE:mysql递归如何实现,p_uid对应的uid数量 |
| ANSWER: 先说明下你的mysql版本吧,8之前和8之后的方法不一样
上面这个sql就是在查询结果里增加了根节点的字段,这样就方便使用group by 聚合了 |
| LINK:https://ask.csdn.net/questions/7667773?answer=53725612 |

| SOURCE:CSDN_ASK |
| ASK_ID:7667777 |
| ANSWER_ID:53725608 |
| TITLE:mysql两张表如何关联查询? |
| ANSWER: 你这两个表的关联字段是什么?id?如果是id的话,直接关联不就好了?而且也没说两个表是否完全匹配,我先假定是完全匹配的 你这个应该不是原表结构,没人会这么设计表格的,上面的sql仅针对你这个奇怪的表结构而写 是否存在table1有的type,在table2中不存在?如果全部都存在,那么直接用type关联就好了, 但奇怪的是,为啥你的price是个VARCHAR?而且还带符号?,这样的话要先把符号去掉才能计算 |
| LINK:https://ask.csdn.net/questions/7667777?answer=53725608 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667726 |
| ANSWER_ID:53725448 |
| TITLE:关于sql server 查询效率低的问题! |
| ANSWER: 把表结构先贴出来,目前无法判断你a表各字段的唯一情况,你子查询里的那张表是不是唯一完全不用管,因为你反正都是聚合。 |
| LINK:https://ask.csdn.net/questions/7667726?answer=53725448 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667717 |
| ANSWER_ID:53725439 |
| TITLE:微服务的项目应该怎么启动 |
| ANSWER: 微服务不是指的某个软件,而是指的一种软件架构方式,特点是按业务进行划分为独立的服务单元。 |
| LINK:https://ask.csdn.net/questions/7667717?answer=53725439 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667342 |
| ANSWER_ID:53725052 |
| TITLE:SQL中union all的使用 |
| ANSWER: 与列名没关系,如果提示 "表达式必须具有与相对应表达式相同的数据类型",那么肯定就是出现了类型不同的情况,请贴出你的表结构和完整sql看看 |
| LINK:https://ask.csdn.net/questions/7667342?answer=53725052 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667304 |
| ANSWER_ID:53725049 |
| TITLE:MySQL创建外键出现错误 |
| ANSWER: 画红圈的两个地方不一样
|
| LINK:https://ask.csdn.net/questions/7667304?answer=53725049 |

| SOURCE:CSDN_ASK |
| ASK_ID:7667274 |
| ANSWER_ID:53725045 |
| TITLE:mysql中两个count值相除,如何合并? |
| ANSWER: group by 的维度一样,没必要分两次查,可以直接在count里写判断条件 |
| LINK:https://ask.csdn.net/questions/7667274?answer=53725045 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667214 |
| ANSWER_ID:53725033 |
| TITLE:SQLserver中,AS RESULT(TNAME,C#,AVG_SCORE)AS X报错为啥?? |
ANSWER:
如果要对同一个子查询别名引用两次以上,应该使用with as |
| LINK:https://ask.csdn.net/questions/7667214?answer=53725033 |
| SOURCE:CSDN_ASK |
| ASK_ID:7667134 |
| ANSWER_ID:53724808 |
| TITLE:利用mysql解决多条件查询 |
| ANSWER: 你不把表和数据贴出来,别人怎么对着你的环境来解释?
|
| LINK:https://ask.csdn.net/questions/7667134?answer=53724808 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666858 |
| ANSWER_ID:53724417 |
| TITLE:用sql求出哪个地区男生的各科均分均比女生低? |
| ANSWER: 问sql题请提供建表及模拟数据的sql,并说明使用的数据库类型及版本号,这样才能方便答题人进行测试 |
| LINK:https://ask.csdn.net/questions/7666858?answer=53724417 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666820 |
| ANSWER_ID:53724405 |
| TITLE:关于Oracle里exists可以和in等价改写 |
| ANSWER: 你最后这个sql的确是删不掉数据的,"a.rowid in (select b.rowid ...) "表示 要找出 "a.rowid=b.rowid"的数据,但是这个in里面,又有这个条件"a.rowid < b.rowid",既等于又小于,这两个条件是不可能同时成立的,因此找不到数据。 其实子查询里select 的字段可以为任何东西,你select 1都行,比如 因为它的重点不在于select了哪个字段,而是在于后面的这两个条件 object_id 和 rowid, |
| LINK:https://ask.csdn.net/questions/7666820?answer=53724405 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666750 |
| ANSWER_ID:53724378 |
| TITLE:请教各位专家:pandas写入excel时,时间太长如何解决? |
| ANSWER: xlsx文件实际上是多个xml文件构成的压缩包,数据、格式等等都定义在了不同的xml文件内,甚至同一个sheet中的数字和文本都是放在了不同的xml文件里,因此读取数据和写入数据都需要进行不少的解析动作。 |
| LINK:https://ask.csdn.net/questions/7666750?answer=53724378 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666746 |
| ANSWER_ID:53724300 |
| TITLE:CONNECT BY ROWNUM |
| ANSWER: 请提供一下所使用的mysql版本号,
|
| LINK:https://ask.csdn.net/questions/7666746?answer=53724300 |

| SOURCE:CSDN_ASK |
| ASK_ID:7666715 |
| ANSWER_ID:53724298 |
| TITLE:虚拟机突然找不到基础命令如:vi,scp是为什么? |
| ANSWER: 执行一下这个看看 Linux的环境变量.bash_profile .bashrc profile文件 - lvmenghui001 - 博客园 Shell变量有局部变量、环境变量之分。局部变量就是指在某个Shell中生效的变量,只在此次登录中有效。环境变量通常又称“全局变量”,虽然在Shell中变量默认就是全局的,但是为了让子Shall继承当 https://www.cnblogs.com/lmh001/p/9999859.html |
| LINK:https://ask.csdn.net/questions/7666715?answer=53724298 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666637 |
| ANSWER_ID:53724180 |
| TITLE:find_in_set,函数,怎么用才能不影响索引 |
| ANSWER: 由于你的“ad.all_start_activity"这个字段是多个值拼出来的字符串,因此不管你怎么写都不会快,正常开发应该是要避免这种结构设计的,老老实实的放到一列里去吧 |
| LINK:https://ask.csdn.net/questions/7666637?answer=53724180 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666555 |
| ANSWER_ID:53724086 |
| TITLE:Navicat中MySQL导入CSV文件之后没法使用表中的中文字符查询 |
| ANSWER: 这是因为你当前窗口的字符集不匹配导致,处理方法为: |
| LINK:https://ask.csdn.net/questions/7666555?answer=53724086 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666310 |
| ANSWER_ID:53723769 |
| TITLE:mac安装mysql报错Found option without preceding group in config file /etc/my.cnf at line 1. |
| ANSWER: 要手动配置一下 "/etc/my.cnf"这个文件里面的内容 |
| LINK:https://ask.csdn.net/questions/7666310?answer=53723769 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666309 |
| ANSWER_ID:53723766 |
| TITLE:kettle做表输入时已成功连接到mysql,但是点入获取sql查询语句的时候出现了错误 |
| ANSWER: OPTION SQL_SELECT_LIMIT=DEFAULT java连接mysql错误_Penn_J的博客-CSDN博客_option sql_select_limit=default 今天公司要搬家了,为了方便在搬家的时候引起的网络变化而导致无法使用的公司测试服务器上的数据库,所以准备将服务器上的数据库备份到本机。 项目启动时创建本地的数据库连接的时候频繁的报出SQL错误: You have an error in your SQL syntax; check the manual that corresponds to your MySQL https://blog.csdn.net/jpiverson/article/details/21226021 建议更新一下connector的版本 |
| LINK:https://ask.csdn.net/questions/7666309?answer=53723766 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666289 |
| ANSWER_ID:53723716 |
| TITLE:MySQL 使用mycli查询表中文乱码 |
| ANSWER: 你这是在什么环境下?数据库字符集是什么?
从这个乱码的表现来看,的确是把UTF-8的字符当成了GBK字符识别了,因为UTF-8一个汉字是3个字节,GBK一个汉字是2个字节,所以"男"就变成了一个汉字加一个问号(半个字)。 但我不确定这个方法是否有效,因为我这里不管怎么改都不会乱码。。。 在mycli官方文档中有介绍,mycli的默认字符集是取的mysql客户端配置信息里的,即 ".my.cnf"文件中 client 的配置,因此还可以检查一下你本机这个文件里配置的是什么
|
| LINK:https://ask.csdn.net/questions/7666289?answer=53723716 |



| SOURCE:CSDN_ASK |
| ASK_ID:7666242 |
| ANSWER_ID:53723653 |
| TITLE:怎么通过函数实现最右一列结果的输出?如图所示 |
| ANSWER: 麻烦说明一下是要求是用什么工具或者什么开发语言实现? EXCEL的话,下面是一种方案,用if判断,然后字符串拼接,用字符串替换把两个逗号变成一个逗号,最后把首尾的逗号去掉。
|
| LINK:https://ask.csdn.net/questions/7666242?answer=53723653 |

| SOURCE:CSDN_ASK |
| ASK_ID:7666221 |
| ANSWER_ID:53723649 |
| TITLE:关于sql中set echo off的疑问 |
| ANSWER: 达梦官方文档中是这么描述ECHO的
DIsql 环境变量设置 | 达梦技术文档 使用 SET 命令可以对当前 DIsql 的环境变量进行设置。并通过 SHOW 命令来查看当前系统中环境变量的设置情况。也可以通过配置文件使 Disql 启动时自动设置一批环境变量。 3.1 DIsql 环境变量DIsql 中的系统环境变量,汇总如下: 表3.1 DIsql命令的快速参考 序号 变量名称 属性 用途 1 AUTO[COMMIT] https://eco.dameng.com/docs/zh-cn/pm/environment-variable-settings.html 也就是说,这个参数控制的不是spool是否输出sql内容,而是,是否输出你调用的sql脚本里的内容 |
| LINK:https://ask.csdn.net/questions/7666221?answer=53723649 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666170 |
| ANSWER_ID:53723586 |
| TITLE:linux中ifconfig:command not found |
| ANSWER: 执行一下这个看看 如果可以成功执行,说明你环境变量加载失败了,请检查环境变量的配置脚本是否有问题 linux安装报错之:ifconfig command not found解决 - WhoKnows1 - 博客园 问题描述: 用虚拟机VMware安装linux系统(镜像文件是从官网下载的CentOS-7.0-1406-x86_64-DVD.iso), 在安装完成之后,输入ifconfig命令报错:ifconfi https://www.cnblogs.com/whoknows1/p/9753097.html |
| LINK:https://ask.csdn.net/questions/7666170?answer=53723586 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666073 |
| ANSWER_ID:53723583 |
| TITLE:订单表和订单明细表join时,数据量大,能不能用分桶表优化? |
| ANSWER: 订单表和订单明细表上如果有同样的日期,可以尝试按日期范围把数据拆开,毕竟大数据计算的最大特点之一就是所谓的分布式。 |
| LINK:https://ask.csdn.net/questions/7666073?answer=53723583 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666030 |
| ANSWER_ID:53723572 |
| TITLE:大家觉得数据库设计的时候,流程状态字段用数字表示好,还是直接对应英文单词好? |
| ANSWER: 用数字的好处,上面各位都已经说了。 会接触到数据库的表和字段的人,会有开发人员(这里专指写程序代码的)、软件运维(这里指分析检查疑似数据异常及数据修复的)、数据分析人员(这里指出报表的)等等。 |
| LINK:https://ask.csdn.net/questions/7666030?answer=53723572 |
| SOURCE:CSDN_ASK |
| ASK_ID:7666011 |
| ANSWER_ID:53723544 |
| TITLE:优化sql 有没有回优化查询sql的 |
| ANSWER: 还需要了解一点信息
分析:
另外,可以尝试下面这个sql,但是可能需要对用到的两个表进行查询授权 这个是把视图拆开,只获取必要信息,减少了user_tables视图中的很多逻辑 |
| LINK:https://ask.csdn.net/questions/7666011?answer=53723544 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665984 |
| ANSWER_ID:53723426 |
| TITLE:Oracle在多条数据中,找出时间最大的一条数据,并对这些数据的某个字段进行汇总 |
| ANSWER: 不知道你是问题描述不全,还是的确是个简单的问题,最大不就是取max?汇总不就是取SUM? |
| LINK:https://ask.csdn.net/questions/7665984?answer=53723426 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665966 |
| ANSWER_ID:53723422 |
| TITLE:mysql order by count * 导致filesort |
| ANSWER: 这种sql避免不了 "Using temporary;" 和 "Using filesort",这是order by 非基表数据时会产生的,
|
| LINK:https://ask.csdn.net/questions/7665966?answer=53723422 |

| SOURCE:CSDN_ASK |
| ASK_ID:7665919 |
| ANSWER_ID:53723399 |
| TITLE:MySQL 用add字段 总是报错ERROR 1064 (42000) |
| ANSWER: 你单词拼写错误了,仔细对比一下这条sql,看和你的有什么区别 代码块颜色都不一样 |
| LINK:https://ask.csdn.net/questions/7665919?answer=53723399 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665875 |
| ANSWER_ID:53723396 |
| TITLE:使用python 实现对CSV文件数据的处理 |
| ANSWER: 我先用文字解析一下哈,看看是不是这个意思
因此原数据一定满足下面这样的格式
那么这其实就是按每行循环,按逗号切割成列表 后再循环 按空格切割生成一行新数据 |
| LINK:https://ask.csdn.net/questions/7665875?answer=53723396 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665892 |
| ANSWER_ID:53723389 |
| TITLE:想让一个字段的行数作为筛选条件 |
| ANSWER: 前10是指总共只取10行出来还是说要按哪些字段分组排序,取每个分组的前10?如果有分组的话是按哪几个字段? 如果是要分组取前10,开窗函数里加上 partition by 分组的字段就好了 |
| LINK:https://ask.csdn.net/questions/7665892?answer=53723389 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665729 |
| ANSWER_ID:53723125 |
| TITLE:SQL分组查询数量求旧 |
| ANSWER: 这个表里应该不止"饺子"和"米饭"这两种吧?如果这个值的清单不是确定的,随时可以修改,那么就不建议写固定的sql来进行转换,因为sql的列数和字段名必须是确定的,总不能加一种食物就改一下sql吧?
|
| LINK:https://ask.csdn.net/questions/7665729?answer=53723125 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665706 |
| ANSWER_ID:53723100 |
| TITLE:hive报错,无法查询等操作 |
| ANSWER: 这个报错里已经给了你建议的操作,要么把使用ssl设置成否,如果ssl要设置成是的话,必须同时提供对应的服务器证书 |
| LINK:https://ask.csdn.net/questions/7665706?answer=53723100 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665688 |
| ANSWER_ID:53723091 |
| TITLE:MDB数据排序问题既有数字又有字母 |
| ANSWER: 在查询时添加一个where条件就行了
|
| LINK:https://ask.csdn.net/questions/7665688?answer=53723091 |



| SOURCE:CSDN_ASK |
| ASK_ID:7665635 |
| ANSWER_ID:53723065 |
| TITLE:关于数据库某一个字段调整为年龄的某一类格式 |
| ANSWER: 其实就用case when 判断一下再拼个字符串就好了,重点是age的字段类型是什么,不同的字段类型判断处理方式不一样.
如果是数值类型,做需要转换成字符串类型再来做截取了,但是,你不觉得这题奇怪么? 小数点后0-9不一定就是表示的月份啊,它可能是0.5表示0.5年,即表示6个月,你得按照原始数据的定义来进行处理,不能自己去想象它是什么东西 |
| LINK:https://ask.csdn.net/questions/7665635?answer=53723065 |

| SOURCE:CSDN_ASK |
| ASK_ID:7665561 |
| ANSWER_ID:53723023 |
| TITLE:GIS10.6版本安装空间句法插件 |
| ANSWER: 把电脑上的杀毒软件什么的都关掉,然后鼠标右键使用管理员模式运行。 |
| LINK:https://ask.csdn.net/questions/7665561?answer=53723023 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665416 |
| ANSWER_ID:53722986 |
| TITLE:mysql 计算平均数出错 求解 |
| ANSWER: 你sql里的那些join都变成笛卡尔积数据翻倍了,所以结果肯定是错误的 如果是不支持开窗函数的数据库,就只能用类似楼上的方式了,先把满足条件的人查出来,再关联回原数据 |
| LINK:https://ask.csdn.net/questions/7665416?answer=53722986 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665084 |
| ANSWER_ID:53722956 |
| TITLE:留存率的时间区间怎么设置? |
| ANSWER: 用开窗函数的滑动窗口,可以实现取当前行的下N行, 看上去没我之前想的那么简单,还需要排除新用户的影响,那么这个时候就需要先得到一个数据,即每个用户每天在次日、7日、30日时的登录状态,这个可以使用开窗函数中的range between来处理,排序用日期差,这样1天就是一个range
|
| LINK:https://ask.csdn.net/questions/7665084?answer=53722956 |

| SOURCE:CSDN_ASK |
| ASK_ID:7665327 |
| ANSWER_ID:53722320 |
| TITLE:MySQL将表引擎修改为mrg_myisam后表数据丢失 |
| ANSWER: 我做了个测试,单纯的修改存储引擎后不会丢失数据 你在navicat右边看到的数据来自于统计信息,而统计信息并不是实时刷新的,这个表里面有没有数据,你直接写sql查就是了 的确在直接修改存储引擎为mrg_myisam后,数据会丢失,而且刷新统计信息后,这个表里也的确没有记录了。mrg_myisam的表的确本身是没有数据的,正确的用法应该是将多个myisam表链接到一个mrg_myisam表里,来实现同时对多个结构相同的表进行管理。 MySQL Bugs: #100443: Table data lost after changing the engine for a table https://bugs.mysql.com/bug.php?id=100443 这是mysql参数设置上的一个bug,至今没有修复,也没排上修复计划
但是这个反馈bug的用户发现:
你这个问题连官方都无解了,甚至这个bug都没排上修复计划
|
| LINK:https://ask.csdn.net/questions/7665327?answer=53722320 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665389 |
| ANSWER_ID:53722314 |
| TITLE:Win10开机黑屏,重做系统后依然黑屏 |
| ANSWER: 建议先排查一下看看是不是显示器的问题,比如先弄个别的什么显示设备接上去试试,没有多的显示器的话,可以用电视,电视都没有的话你就只能去借别人的显示器试下了,黑屏状态下电脑还有声音,这大概率与操作系统没有关系,而且根据你的描述来看,只有显示器没换了 |
| LINK:https://ask.csdn.net/questions/7665389?answer=53722314 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664893 |
| ANSWER_ID:53722312 |
| TITLE:从sql serve中查询出现的最后一次记录 |
| ANSWER: 用开窗函数分组排序就行了 |
| LINK:https://ask.csdn.net/questions/7664893?answer=53722312 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665335 |
| ANSWER_ID:53722308 |
| TITLE:GRANT ALL PRIVILEGES ON . TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;存在错误 |
| ANSWER: 去掉后面的 with grant option 试试, mysql8 grant授权报错:ERROR 1410 (42000): You are not allowed to create a user with GRANT - 简书 问题说明: 在8.0以前,我们习惯使用以下命令授权远程连接操作: 但在8.0以后,使用以上命令会报错: 分析原因: 因为在8.0以后,这个特性已被移除,官方文档如下: 原文:... https://www.jianshu.com/p/98a6d42e28c8 grant all privileges on . to 报错问题 - 代码先锋网 grant all privileges on . to 报错问题,代码先锋网,一个为软件开发程序员提供代码片段和技术文章聚合的网站。 https://www.codeleading.com/article/73012100466/ |
| LINK:https://ask.csdn.net/questions/7665335?answer=53722308 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665086 |
| ANSWER_ID:53722304 |
| TITLE:关于Mysql改变表不能保存问题 |
| ANSWER: 看下执行的输出结果中是否包含报错信息,如果不知道怎么看输出结果,那就直接写sql来修改字段长度。 |
| LINK:https://ask.csdn.net/questions/7665086?answer=53722304 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665082 |
| ANSWER_ID:53722292 |
| TITLE:Mysql连接问题(Nextcloud安装问题) |
| ANSWER: 你先搞个navicat连接一下数据库看能不能连上,如果连不上就是数据库配置有问题。 下面这个是我的docker管理器哈,24小时不间断一直在运行中
|
| LINK:https://ask.csdn.net/questions/7665082?answer=53722292 |

| SOURCE:CSDN_ASK |
| ASK_ID:7665000 |
| ANSWER_ID:53722279 |
| TITLE:sql中exists和in的区别是什么 |
| ANSWER: 你想象一下,如果你手里有两张纸制表格,让你自己用肉眼来过滤数据,会如何执行in以及exists?
好在,现在很多数据库已经认知到这种差异了,有的数据库已经在新版本中对in 和exists的执行计划进行了调优,自动去判断更适合使用哪种方式(虽然不是绝对判断准确) |
| LINK:https://ask.csdn.net/questions/7665000?answer=53722279 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663943 |
| ANSWER_ID:53722225 |
| TITLE:关于niceform.ocx的问题 |
ANSWER:
当然,建议还是直接咨询你们学校有经验的学长或者老师要来得快 |
| LINK:https://ask.csdn.net/questions/7663943?answer=53722225 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664561 |
| ANSWER_ID:53722198 |
| TITLE:查询第一行sign_in等于3和上一行sign_in等于3的(找到第一个出现3的行) |
| ANSWER: 写sql还是太绕了,而且还不是oracle数据库,给你一个plsql吧 执行结果
|
| LINK:https://ask.csdn.net/questions/7664561?answer=53722198 |

| SOURCE:CSDN_ASK |
| ASK_ID:7664984 |
| ANSWER_ID:53722185 |
| TITLE:请教个关于db数据加密的问题? |
| ANSWER: 这个嘛,其实是有方案的,你想想,构成整个软件系统的,除了程序代码以及数据以外,还有什么? |
| LINK:https://ask.csdn.net/questions/7664984?answer=53722185 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664966 |
| ANSWER_ID:53722181 |
| TITLE:CASE 添加 max() 便会报错 能否优化? |
| ANSWER: 建议先描述一下你的场景,你目前这个sql语法是有问题的,如果用max或者min这样的聚合函数,而且不开窗,而且有分组字段,那么必须要使用group by . 但是,mysql要8.0以上版本才支持,否则你就得写个子查询先把最小最大查出来,再去关联到原数据了 |
| LINK:https://ask.csdn.net/questions/7664966?answer=53722181 |
| SOURCE:CSDN_ASK |
| ASK_ID:7665002 |
| ANSWER_ID:53722015 |
| TITLE:MySQL十六进制转化不成字符 |
| ANSWER: 控制台界面默认不会进行自动转换,可以用cast手动转换一下
|
| LINK:https://ask.csdn.net/questions/7665002?answer=53722015 |

| SOURCE:CSDN_ASK | ||||||
| ASK_ID:7665005 | ||||||
| ANSWER_ID:53721921 | ||||||
| TITLE:update语句如何将字段值相同的另一字段值相加 | ||||||
| ANSWER: 你最后想要的结果是不是下面这样?
然后,你数据里,一个ks#是肯定只有两行还是会有更多行?如果有更多行的时候,是否会出现多行正数多行负数?这个时候你打算哪个和哪个加? 如果确定只有两行,很好处理,怕的就是你这是个复杂批次库存冲销业务,这是要根据业务逻辑写程序的,一个update实现不了 | ||||||
| LINK:https://ask.csdn.net/questions/7665005?answer=53721921 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664487 |
| ANSWER_ID:53721864 |
| TITLE:EXCEL如何实现多对多调取数据? |
| ANSWER: 看上去咋这么像透视表的筛选器呢?要达成同样的效果,不是非得用公式吧?
在上面选择条件,下面就会出现对应的数据,是多行多列的 |
| LINK:https://ask.csdn.net/questions/7664487?answer=53721864 |

| SOURCE:CSDN_ASK |
| ASK_ID:7664785 |
| ANSWER_ID:53721643 |
| TITLE:请问大家mysql数据库创建表时出现Cannot add foreign key constraint报错的原因 |
| ANSWER: 为了方便定位问题,能否说明一下你数据库的版本及配置信息,还有把这段执行的sql以代码块的方式添加到问题里,
|
| LINK:https://ask.csdn.net/questions/7664785?answer=53721643 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664526 |
| ANSWER_ID:53721528 |
| TITLE:SAP HAHA数据库有没有查询表字段属性的sql |
| ANSWER: https://help.sap.com/viewer/4fe29514fd584807ac9f2a04f6754767/2.0.00/en-US/2100d33a75191014868bbcd89274199c.html
查 TABLE_COLUMNS 这个视图就行了 |
| LINK:https://ask.csdn.net/questions/7664526?answer=53721528 |

| SOURCE:CSDN_ASK |
| ASK_ID:7664670 |
| ANSWER_ID:53721503 |
| TITLE:两个或多个项目中重复字段怎么处理? |
| ANSWER: 先假定你所说的数据是同一个维度的吧,如果不在一个维度就没必要讨论了,肯定是多张表。 都是多年实战经验积累下来的,不同行业甚至不同公司都会有所区别。 |
| LINK:https://ask.csdn.net/questions/7664670?answer=53721503 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664646 |
| ANSWER_ID:53721475 |
| TITLE:百万级别sql server 数据库 sql语句优化 |
| ANSWER: 加个where条件先过滤出需要的数据,其实上次就和你说过了 如果sqlserver版本老了没有EOMONTH这个函数的话,可以使用其他的替代方式,比如 |
| LINK:https://ask.csdn.net/questions/7664646?answer=53721475 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664599 |
| ANSWER_ID:53721464 |
| TITLE:为什么运行写好的sql语句,运行成功,但是没有表 |
| ANSWER: 你哪里看到运行成功了?下面不是有报错么?说你语法错误,在 "{"这个符号附近。 |
| LINK:https://ask.csdn.net/questions/7664599?answer=53721464 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664569 |
| ANSWER_ID:53721461 |
| TITLE:在连表前where更快还是连表后where呢 |
ANSWER:
这个意思是不是指a.a在b.b中都会存在? 让sql简单一点,oracle的优化器会更容易判断该如何执行更快,反正就只有两个表。 |
| LINK:https://ask.csdn.net/questions/7664569?answer=53721461 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664374 |
| ANSWER_ID:53720952 |
| TITLE:关于stata的安装显示无法提取文件 |
| ANSWER: 你下载的是一个压缩文件,先对准你下载的这个文件,鼠标右键,提取(或者解压),到一个文件夹,然后再进入这个文件夹执行安装程序 第二张图是让你填写你购买这个产品的序列号什么的,这个软件不是免费使用的哦 |
| LINK:https://ask.csdn.net/questions/7664374?answer=53720952 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664419 |
| ANSWER_ID:53720951 |
| TITLE:app迁移数据 微信登录也可以迁移吗 需要具备什么条件 |
| ANSWER: 不同的小程序,用户的openid不一样的,之前注册的时候需要获取到用户唯一信息,比如手机号,然后生成你自己对用户的唯一管理id, 有些项目会选择保存用户的微信号,但是微信号是可能为空的,而且微信号还可以修改,所以一般选择使用手机号来进行验证匹配 |
| LINK:https://ask.csdn.net/questions/7664419?answer=53720951 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664326 |
| ANSWER_ID:53720948 |
| TITLE:前端url请求中 非必填参数如何校验处理? |
| ANSWER: 建议看下后端是怎么处理的,当你有条件传空时,后端是否能正确返回数据? 另外,前端、后端必须要遵从相同的逻辑,比如这玩意到底是可以返回多行还是只能返回一行? 你报表服务器就是后端,必须要确定一下它sql的where条件是怎么写的,有这样两种情况
url这一部分的话,其实就是一个字符串拼接,你可以对每个可为空的参数,写个if判断逻辑,当参数不为空时,才把这个参数给拼上去 |
| LINK:https://ask.csdn.net/questions/7664326?answer=53720948 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664407 |
| ANSWER_ID:53720946 |
| TITLE:Tableau安装不了,如何解决? |
| ANSWER: 先确认你当前登录的用户是管理员, Win10打开软件提示"为了对电脑进行保护,已经阻止此应用"解决方法 - 知乎 首先确定你的系统版本是家庭版,还是专业版。为了方便理解,咱们先介绍专业版的解决办法。 一,win0专业版的解决办法 首先我们按下Win+R“”组合快捷键打开“运行”,在运行中输入“ gpedit.msc”并确定即可打开组… https://zhuanlan.zhihu.com/p/143754740 |
| LINK:https://ask.csdn.net/questions/7664407?answer=53720946 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664368 |
| ANSWER_ID:53720944 |
| TITLE:mysql少输入一个逗号 但是下一个行已经开始了 怎么添加?! |
| ANSWER: sql 命令没有严格的分行,你把这些东西都写到一行也是可以执行的,同理,你多分几行写也不影响。 |
| LINK:https://ask.csdn.net/questions/7664368?answer=53720944 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664311 |
| ANSWER_ID:53720942 |
| TITLE:ssm项目可以将数据库从sqlserver更换为数据库为mysql吗? |
| ANSWER: 别直接换,建议先搞套测试环境试试看,两个数据库有一些语法不一样的,甚至有些函数名称一样但用法不一样, |
| LINK:https://ask.csdn.net/questions/7664311?answer=53720942 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664360 |
| ANSWER_ID:53720932 |
| TITLE:Linux中正则表达式的相关问题 |
| ANSWER: 前2位相同,但第3位和第一位不同,第4位也和第一位不同?
从这里可以看到,你后面的"\1"已经不代表第一个分组了,所以错了 至于正确的正则表达式应该是怎样的,你先说下老师的原题是什么吧 我上面的回答已经告诉你错在哪里了,那个中括号里的"\1"已经不是代表第一个分组了,而是代表的字符"1",所以你“1111”没选出来的原因其实是因为你写的这个就是后两位不为"1",如果它来一个"2222"照样会被你这个表达式找出来。至于正确答案,楼下的已经说了,要用"?!". 如果后面两个字符要一样的话,楼下的答案也会有问题,你用我下面贴的这个应该就没问题了,注意我这里修改了正则匹配模式
下面这个题里写了关于linux的负向先行断言( negative lookahead assertion) regex - Using grep with a negative lookahead assertion - Stack Overflow  https://stackoverflow.com/questions/67780479/using-grep-with-a-negative-lookahead-assertion
|
| LINK:https://ask.csdn.net/questions/7664360?answer=53720932 |


| SOURCE:CSDN_ASK |
| ASK_ID:7664255 |
| ANSWER_ID:53720775 |
| TITLE:移动和家亲修改dns无效 |
| ANSWER: 一般情况下,VPN软件连上后,会加载静态路由表,配置指定的ip走哪条路由,但是你这个VPN可能并没有配置全,所以你可以尝试手工添加静态路由 route add |
| LINK:https://ask.csdn.net/questions/7664255?answer=53720775 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664241 |
| ANSWER_ID:53720764 |
| TITLE:电脑里老是被自动安装一个叫“影视大全”的软件 |
| ANSWER: 鼠标右键这个图标,打开文件所在位置,把完整的路径发出来,截个图看看里面有些什么文件,并且截一下图标看看 |
| LINK:https://ask.csdn.net/questions/7664241?answer=53720764 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664116 |
| ANSWER_ID:53720751 |
| TITLE:mysql初学者打不开文件 |
| ANSWER: 那你就点这个 "choose encoding"按钮, 再选择编码呗 |
| LINK:https://ask.csdn.net/questions/7664116?answer=53720751 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664243 |
| ANSWER_ID:53720724 |
| TITLE:java代码写千万级数据同步 |
| ANSWER: 是一次性操作还是经常要使用的操作? 是oracle的dblink?网络带宽及稳定性怎么样? 如果担心一次性吃不下,就按开户日期范围,分批create成多张表,最后再合并 |
| LINK:https://ask.csdn.net/questions/7664243?answer=53720724 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664140 |
| ANSWER_ID:53720710 |
| TITLE:SQL中select的简单运用简单运用 |
| ANSWER: sqlserver中,可以用datediff函数来计算时间差,第一个参数是需要返回值的度量单位,比如年、月、日等,后两个参数就是要计算时间差的时间了。
|
| LINK:https://ask.csdn.net/questions/7664140?answer=53720710 |

| SOURCE:CSDN_ASK |
| ASK_ID:7664173 |
| ANSWER_ID:53720680 |
| TITLE:一个用户将数据库中的题库信息修改掉,另一个用户访问题库时是已经被修改的 |
| ANSWER: 首先,有个”标准题库表“,这个表里面的数据所有外部用户都无法修改, |
| LINK:https://ask.csdn.net/questions/7664173?answer=53720680 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664225 |
| ANSWER_ID:53720671 |
| TITLE:怎么查询oracle表中,除了最小日期以外的所有数据 |
| ANSWER: 提sql问题的时候,麻烦给一下表结构和数据说明,以及最终需要的数据格式。 你不是说表里面的最小日期么?为什么还会有个group by 呢?你这group by 以后,就不是唯一的最小日期了,而是分组以后的最小日期,但你问题中并没有明确描述到底是个什么样的场景 |
| LINK:https://ask.csdn.net/questions/7664225?answer=53720671 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664010 |
| ANSWER_ID:53720545 |
| TITLE:mysql字符集错误 |
| ANSWER: 你把这个报错提示后面的这个Index.xml文件打开,看看里面有哪些字符集,你设置的字符集只能是在这个文件中有的。 |
| LINK:https://ask.csdn.net/questions/7664010?answer=53720545 |
| SOURCE:CSDN_ASK |
| ASK_ID:7664044 |
| ANSWER_ID:53720471 |
| TITLE:MYSQL 创建多对多表关系时,这两种创建方式有什么区别吗 |
| ANSWER: 外键主要看的是,”A依赖于B“,也就是说,先有B,才能有A, |
| LINK:https://ask.csdn.net/questions/7664044?answer=53720471 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663806 |
| ANSWER_ID:53720426 |
| TITLE:oracle查询出两个表内字段相同但数据量不同的表名字 |
| ANSWER: 这个题目有点歧义,两个表字段相同是指的所有字段名都相同还是只有部分字段名相同?还有字段顺序是否需要考虑?
其实主要就是两个处理方向, |
| LINK:https://ask.csdn.net/questions/7663806?answer=53720426 |

| SOURCE:CSDN_ASK |
| ASK_ID:7663818 |
| ANSWER_ID:53720339 |
| TITLE:merge into中处理空值问题 |
| ANSWER: 把你的 on里的条件用nvl处理一下 这个与merge into本身并没有关系,null值是不能直接用等于号来判断的 |
| LINK:https://ask.csdn.net/questions/7663818?answer=53720339 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663541 |
| ANSWER_ID:53720132 |
| TITLE:键值对,相比关系型字段名,是否浪费了空间? |
| ANSWER: 某张关系型表有3个字段,一个KEY,两个VALUE, |
| LINK:https://ask.csdn.net/questions/7663541?answer=53720132 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663644 |
| ANSWER_ID:53720107 |
| TITLE:把Navicat Premium15里面的数据表结构给导入Excel里!! |
| ANSWER: 你如果想确定字段名是什么,直接查出所有字段再去对比就知道了 比如是否可为空
至于查询结果的显示方式,你那个是15版本的Navicat Premium加的”特效“,我使用的是12版本不会进行自动转换,你可以看下软件设置里面是不是有什么针对查询结果显示效果的开关 |
| LINK:https://ask.csdn.net/questions/7663644?answer=53720107 |

| SOURCE:CSDN_ASK |
| ASK_ID:7663653 |
| ANSWER_ID:53720092 |
| TITLE:mysql 遍历查询部门下的用户数量 |
| ANSWER: 请说明一下mysql的版本,8之前和8之后的写法不一样
以上sql参考自 https://www.oschina.net/question/2402835_2285575 但不确定你人员信息里面的多个部门,是否可能在一个检索分支里?这样的话可能会被统计多次 如果存在一个人在多个检索分支里,那就查员工表,把部门当存在条件,下面这个sql就这个意思,但可以减少括号层数的,你自己看着改改吧 |
| LINK:https://ask.csdn.net/questions/7663653?answer=53720092 |

| SOURCE:CSDN_ASK |
| ASK_ID:7663690 |
| ANSWER_ID:53720075 |
| TITLE:如何在不用子查询的情况下使用SQL写出 |
| ANSWER: 这个题目没说得太明白,但是看上去好像是拜访表的第二个字段,用逗号分隔了员工编号,有一个逗号时表示拜访了两次,2个逗号表示拜访了3次,因此只需要统计出逗号的个数就行了。
根据题主补充信息来看,拜访表里的并不是大家以为的拜访人和被拜访人,拜访表里存的其实是拜访计划,两个字段的含义分别是拜访领队和拜访成员,也就是说,其实是要统计拜访表中,每个人员出现的次数,也就是说,要把逗号里的内容进行拆分,把所有的工号放到一列中去,此时才能用count。
我知道你们出题人的意思了,考的是like join产生的笛卡尔积,但是这样会存在一点问题,因为不确定是否存在工号长度不一,比如123和1234,两者可能会匹配上,需要做一些特殊处理
加上分隔符特殊处理,避免歧义
出题人给出的答案用了instr函数,如下 INSTR函数获取第二个参数在第一个参数中出现的位置,如果没有出现,那么返回的是0,这里写了大于0 ,其实和我上面写的like差不多一个意思,但这个答案的歧义问题还是得加上标识符,要改成像下面这样才算没有漏洞,因为员工工号只会为数字,加上任意非数字的分隔符能准确识别字符串的截断位置 |
| LINK:https://ask.csdn.net/questions/7663690?answer=53720075 |




| SOURCE:CSDN_ASK |
| ASK_ID:7663778 |
| ANSWER_ID:53720047 |
| TITLE:sql 时间区间怎么写 有无能人 |
| ANSWER: 请把你create table 的语句及模拟的insert数据贴出来,并用表格说明最后需要的查询效果 大概这样,只需要查一次这张表,where 条件里包含有你需要的数据范围,然后在count里加case when 来进行指定条件的统计
以上是oracle中的语法,其他数据库可能要处理下日期表示和日期计算,应该能看懂吧? |
| LINK:https://ask.csdn.net/questions/7663778?answer=53720047 |

| SOURCE:CSDN_ASK |
| ASK_ID:7663801 |
| ANSWER_ID:53720041 |
| TITLE:数据库设置表有中文设置不了 |
| ANSWER: 打开cmd后,输入 回车,然后再连接mysql,执行带有中文的命令。 |
| LINK:https://ask.csdn.net/questions/7663801?answer=53720041 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663376 |
| ANSWER_ID:53719426 |
| TITLE:如何让用户可以读取到阿里oss私有云(内网)的文件 |
| ANSWER: 你打开你的阿里云的控制台,进入oss的页面,看到下面这个画红圈圈的地方,把你链接的域名换了就可以公网访问了,当然前提是你配置了允许无密码访问,或者客户端设置好了验证方式
另外,走外网线路访问文件,是要收费的哟,而且是按流量收费 |
| LINK:https://ask.csdn.net/questions/7663376?answer=53719426 |

| SOURCE:CSDN_ASK |
| ASK_ID:7663418 |
| ANSWER_ID:53719418 |
| TITLE:前几天遇到一个MySQL面试题 |
| ANSWER: mysql 8.0以上支持开窗函数,可以使用row_number进行分组排序 由于你没说是否可能存在缺考的情况,我就没左关联了 |
| LINK:https://ask.csdn.net/questions/7663418?answer=53719418 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663156 |
| ANSWER_ID:53719409 |
| TITLE:如何通过一条sql语句根据子分类id获取子分类及其所有父分类 |
ANSWER:
mysql 向下无限递归(不使用函数,单纯sql) - OSCHINA - 中文开源技术交流社区 做一个无限向下递归查询,网上都是创建函数,使用函数的方式,想知道怎么只使用一条sql来实现。  https://www.oschina.net/question/2402835_2285575 |
| LINK:https://ask.csdn.net/questions/7663156?answer=53719409 |

| SOURCE:CSDN_ASK |
| ASK_ID:7663110 |
| ANSWER_ID:53719400 |
| TITLE:请问mysql这个查询是否开启日志的指令怎么不好使啊 |
ANSWER:
我试了5.5、5.6、5.7、8.0版本的mysql,这条命令都是有用的,有个可能性极低的情况,你复制的那个代码和我这个代码不一样 |
| LINK:https://ask.csdn.net/questions/7663110?answer=53719400 |

| SOURCE:CSDN_ASK |
| ASK_ID:7663125 |
| ANSWER_ID:53719390 |
| TITLE:sql Server2012安装程序支持文件失败 |
| ANSWER: 你本来安装的sql Server是哪个版本,就使用对应版本的sqlsupport.msi,你装的这个2012版本比你当前在用的版本要低,当然就装不上了 |
| LINK:https://ask.csdn.net/questions/7663125?answer=53719390 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663126 |
| ANSWER_ID:53719389 |
| TITLE:请问pgsql导入格栅数据时出现以下错误怎么办呀? |
| ANSWER: 你把那一串psql登录命令输入并回车后,程序会要求你输入口令,然后你就把数据库密码输入进去再回车 |
| LINK:https://ask.csdn.net/questions/7663126?answer=53719389 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663158 |
| ANSWER_ID:53719383 |
| TITLE:请教!我的MySQL一张表字段很多,将近800个,字段类型基本为float,少数为varchar(20),我这样的一张表大概可以存多少条记录 |
| ANSWER: 数据库的表没有行数限制的,但是可能会有单行的长度限制, |
| LINK:https://ask.csdn.net/questions/7663158?answer=53719383 |
| SOURCE:CSDN_ASK |
| ASK_ID:7663373 |
| ANSWER_ID:53719377 |
| TITLE:请问一下pgsql提示no password supplied怎么解决呀? |
| ANSWER: 这是说你没有输入口令(就是密码) |
| LINK:https://ask.csdn.net/questions/7663373?answer=53719377 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662992 |
| ANSWER_ID:53718893 |
| TITLE:DOS命令中验证JAVA的配置环境却是空白 |
| ANSWER: 是JAVA_HOME ,不是JAVA.HOME, |
| LINK:https://ask.csdn.net/questions/7662992?answer=53718893 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662952 |
| ANSWER_ID:53718884 |
| TITLE:sql怎么把修改后表的内容更新到老表里啊 我想把红圈里的这个值更新到另一个表里 |
| ANSWER: UPDATE (Transact-SQL) - SQL Server | Microsoft Docs UPDATE (Transact-SQL) https://docs.microsoft.com/en-us/sql/t-sql/queries/update-transact-sql?view=sql-server-ver15 选取其中一个例子 这个例子几乎和你的要求一模一样了,只需要把表名和字段名替换一下就行了 另外,关于多表关联更新,各个数据库虽然都有所区别,但其实有个通用的方法,可以用下面这个sql得到验证 |
| LINK:https://ask.csdn.net/questions/7662952?answer=53718884 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662980 |
| ANSWER_ID:53718804 |
| TITLE:linux系统的文件,属主 |
| ANSWER: 文件所有权的拥有者可以对这个文件进行任何操作 |
| LINK:https://ask.csdn.net/questions/7662980?answer=53718804 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662957 |
| ANSWER_ID:53718793 |
| TITLE:如何给SQL查询结果加标题? |
| ANSWER: sql的查询结果只会是一个表格,表格里包含字段名和对应的值,没有其他东西了, |
| LINK:https://ask.csdn.net/questions/7662957?answer=53718793 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662861 |
| ANSWER_ID:53718674 |
| TITLE:每张表格都需要计算不同项目的比例和和比例的平均数,要处理几百张表格,请问有简便方法吗(关键词-分表) |
| ANSWER: 你的表是在数据库里?还是excel还是文本? 如果是在excel里,目前较为简单的方式就是使用python来写段代码来处理了,循环读取所有文件,并对每个文件执行相同的操作,但这要求你具有一点基础的pytho开发知识 |
| LINK:https://ask.csdn.net/questions/7662861?answer=53718674 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662829 |
| ANSWER_ID:53718666 |
| TITLE:plsql数据库中如何批量截取两个字段的值拼接到第三个字段 |
| ANSWER: 你更新的原始字段来自于自己表的的本行,就没表要再去select一次了。 然后你的目的是把这个查询的第二列更新到第1列上去,所以转换成update语句就是下面这样写的 |
| LINK:https://ask.csdn.net/questions/7662829?answer=53718666 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662795 |
| ANSWER_ID:53718656 |
| TITLE:Oracle中select语句能调用存储过程吗? |
| ANSWER: 首先,oracle的存储过程没有return,因此不能在select语句里直接使用。 【ORACLE】谈一谈Oracle数据库使用的字符集,不仅仅是乱码_DarkAthena的博客-CSDN博客 一、前言先看一个比较有意思的案例上面这个sql,查询了a和b两个字段,均为"张三"两个汉字,并且使用length函数检查,长度均为2。但是,当你看到下面这几个sql的输出结果时,很有可能第一反应是:"这特喵的怎么可能?"其实,你所看到的两个"张三",的确长得是一模一样,用显微镜去看也不可能看到区别。但为什么a和b不相等呢?这是因为组成他们的成分不一样,这个成分就是 字符集二、什么是字符集?百度百科简单来说,字符(Character)是各种文字和符号的总称,包括各国家文字、标 https://darkathena.blog.csdn.net/article/details/122659532?spm=1001.2014.3001.5502 |
| LINK:https://ask.csdn.net/questions/7662795?answer=53718656 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662757 |
| ANSWER_ID:53718644 |
| TITLE:怎么求出每天的总产量和月累计产量 |
| ANSWER: 首先,你用 substr(prod_time, 1, 8) 这个东西,截出来的是不是长这个样子 ‘20220315’ 的8位年月日? 另外,你并没有说是否要将日产量和月产量合到一个查询结果里,也没说在一个查询结果中要如何展示,所以我也不展开说了 |
| LINK:https://ask.csdn.net/questions/7662757?answer=53718644 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662754 |
| ANSWER_ID:53718634 |
| TITLE:有谁知道sql插入语句如何添加fi判断或者case判断吗 |
| ANSWER: 把case when 表达式当成一个值用就OK了,只是要注意你判断的是个啥
|
| LINK:https://ask.csdn.net/questions/7662754?answer=53718634 |

| SOURCE:CSDN_ASK |
| ASK_ID:7662752 |
| ANSWER_ID:53718630 |
| TITLE:oracle正则表达式 |
| ANSWER: 这个不一定非得正则 如果要正则的话,就这样
|
| LINK:https://ask.csdn.net/questions/7662752?answer=53718630 |

| SOURCE:CSDN_ASK |
| ASK_ID:7662702 |
| ANSWER_ID:53718628 |
| TITLE:sql题:如何获取分组后,里面的某些指定行的数据。 |
| ANSWER: 如果是mysql 8.0以上,可以用开窗函数row_number进行分组排序 |
| LINK:https://ask.csdn.net/questions/7662702?answer=53718628 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662886 |
| ANSWER_ID:53718623 |
| TITLE:运行结果及报错内容,如何解决? |
| ANSWER: 第一个是警告,下面这个东西没有设置默认值,
可以在启动的时候添加后面的参数来跳过 第二个是报错,初始化的时候发现已经存在data目录了,如果你这个数据库里没有要保留的数据,可以把data目录删了 |
| LINK:https://ask.csdn.net/questions/7662886?answer=53718623 |

| SOURCE:CSDN_ASK |
| ASK_ID:7662617 |
| ANSWER_ID:53718173 |
| TITLE:电脑文件打不开,如何方式 |
| ANSWER: pkq是什么文件?
都找不到这种文件,没有默认打开方式这不是挺正常的么? |
| LINK:https://ask.csdn.net/questions/7662617?answer=53718173 |

| SOURCE:CSDN_ASK |
| ASK_ID:7662607 |
| ANSWER_ID:53718172 |
| TITLE:tomcat安装问题 |
| ANSWER: windows下查看本机ip用ipconfig命令 话说这tomcat不是你自己配置的端口号么?你在哪台机上配置的就是哪台机的IP,你不知道ip是怎么连上服务器来部署tomcat的?本地部署?虚拟机部署? |
| LINK:https://ask.csdn.net/questions/7662607?answer=53718172 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662603 |
| ANSWER_ID:53718139 |
| TITLE:我要怎样才可以跳转到D盘并且可以运行java |
| ANSWER: 切换到不同盘符至少有3种方式
如果是全路径,个人习惯用 pushd ,因为不需要输入多余的参数 |
| LINK:https://ask.csdn.net/questions/7662603?answer=53718139 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662440 |
| ANSWER_ID:53718000 |
| TITLE:将多个没有关联条件的表组成一个表,数据结果为多个表数据的相乘数,请问如何解决 |
| ANSWER: 没有关联条件,结果行数当然是乘积了,这就叫笛卡尔积。 |
| LINK:https://ask.csdn.net/questions/7662440?answer=53718000 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662428 |
| ANSWER_ID:53717968 |
| TITLE:SQLSEVER 如何输出的值可以满足两列值都不重复(看图说话) |
ANSWER:一般用上面这个写法就好了,比较好理解, 有些初学者可能会像下面这样写,不能算错,但某些情况下,查询效率会比较低 |
| LINK:https://ask.csdn.net/questions/7662428?answer=53717968 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662391 |
| ANSWER_ID:53717946 |
| TITLE:sql语句,查找学号和课程数 |
ANSWER:
所以,sql长下面这个样子 话说这是刚学么? |
| LINK:https://ask.csdn.net/questions/7662391?answer=53717946 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662349 |
| ANSWER_ID:53717943 |
| TITLE:sql简单运用简单运用 |
| ANSWER: 补充一下 |
| LINK:https://ask.csdn.net/questions/7662349?answer=53717943 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662309 |
| ANSWER_ID:53717836 |
| TITLE:r2dbc + postgresql,在@Query里面,如果参数值为null,怎样动态组装sql语句(语言-java) |
| ANSWER: 不同数据库及不同版本的函数可能会存在一点差异,常见的一般就是用nvl 或者coalesce函数来处理,比如 由于null和空字符串在不同数据库里存在不一样的情况,所以下面这种方式更为通用 这个查询条件,我直接在数据库里测试是没有问题的,传null或者传非null都可以正常输出结果
|
| LINK:https://ask.csdn.net/questions/7662309?answer=53717836 |

| SOURCE:CSDN_ASK |
| ASK_ID:7662308 |
| ANSWER_ID:53717826 |
| TITLE:如何以计算值作为查询条件 |
| ANSWER: 最直观的,比如要查折扣额为10元的 或者下面这个也是等价的 如果是要按折扣范围查 表达式既可以作为查询字段,也可以作为条件字段哦 折扣率也是一个道理 这东西加减乘除随你怎么玩 |
| LINK:https://ask.csdn.net/questions/7662308?answer=53717826 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662220 |
| ANSWER_ID:53717723 |
| TITLE:查询类似聊天会话列表的一个select语句 |
ANSWER:
目前能想到的就是开窗函数分组排序,取每个组里的第一条,但是不确定你分组的标准,A-B和B-A是两组还是一组?另外开窗函数外如果有聚合函数,那么开窗函数内的写法是有点区别的,而且不同的数据库这里的语法也有点区别,所以你最好说明一下数据库版本,并且给出建表sql,方便答题人进行调试 8.0支持开窗函数,所以重点就在你的分组了,根据你补充的描述来看,这个分组是不管顺序的,因此这里需要用到case when 来强制指定顺序,将双方拼成一个字符串,再使用这个字符串进行分组,sql如下,已经包含了你要的count了,count的分组方式和取最新一条的分组方式保持一致 |
| LINK:https://ask.csdn.net/questions/7662220?answer=53717723 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662190 |
| ANSWER_ID:53717698 |
| TITLE:SQL里两个count语句相除怎么除啊 |
| ANSWER: 麻烦给个报错信息? |
| LINK:https://ask.csdn.net/questions/7662190?answer=53717698 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661878 |
| ANSWER_ID:53717597 |
| TITLE:查出源数据库里新增数据办法都有哪些?有哪些开源工具可用或者代码咋写? |
| ANSWER: 这个要看你具体的业务系统逻辑,尤其是在oracle数据库上。
另外,如果数据是可能发生变更的,那么常见的做法是在源表上加个触发器,生成日志表的数据,然后使用日志表关联源表来替代源表的数据源,当然上面提到的序列就不需要在源表增加了,放在日志表中即可 |
| LINK:https://ask.csdn.net/questions/7661878?answer=53717597 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661947 |
| ANSWER_ID:53717567 |
| TITLE:批量更新9亿条数据,如何优化update? |
| ANSWER: 首先,这个sql建议再加一个条件,你确定是每一行都要更新? update会占用回滚段,尤其是你这9亿数据一把更新,如果还有索引的话会更慢。但create table as的方式会以数据块的形式直接复制数据。在oracle中如果涉及到大量数据要处理时,用create table as来替代insert /delete/update等操作是很常见的。 |
| LINK:https://ask.csdn.net/questions/7661947?answer=53717567 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661996 |
| ANSWER_ID:53717539 |
| TITLE:php+mysql 输出table 如何横向排列 |
| ANSWER: 最简单的方式的确是像楼上说的那样用case when ,比如 但是这有个缺陷,sql查询时必须固定好有多少列,因此这个sql是无法通过你数据的变化来动态变化列数的,只能先查一次数据,获得可能的值,再动态拼接sql来执行查询。 |
| LINK:https://ask.csdn.net/questions/7661996?answer=53717539 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662050 |
| ANSWER_ID:53717528 |
| TITLE:请问mysql怎么查询本周未登录的用户 |
| ANSWER: 用 not in 或者 not exists都行, |
| LINK:https://ask.csdn.net/questions/7662050?answer=53717528 |
| SOURCE:CSDN_ASK |
| ASK_ID:7662063 |
| ANSWER_ID:53717525 |
| TITLE:医疗大数据的建设标准? |
| ANSWER: 这个话题很大哈, |
| LINK:https://ask.csdn.net/questions/7662063?answer=53717525 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661712 |
| ANSWER_ID:53716813 |
| TITLE:MySQL创表,练习刚开始写就错了 |
| ANSWER: 如果数据库已经存在,再去创建的话,报错提示会是数据库已存在,而不是你第一张图提示的模式目录已存在。 |
| LINK:https://ask.csdn.net/questions/7661712?answer=53716813 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661708 |
| ANSWER_ID:53716803 |
| TITLE:希望排行榜上的玩家不会减少 |
| ANSWER: 封号依据是什么?能不能在取排行TOP10之前把封号的数据都过滤掉再来排序? 果然,就怕你这个逻辑是排序后再封号,因为这就会涉及到要做一个循环处理,而且一开始必须全部把序号排了 另外,为了节省开销,可以根据多次真实数据来计算一个概率,比如前30人完成TOP10的概率、前100人完成TOP10的概率.... |
| LINK:https://ask.csdn.net/questions/7661708?answer=53716803 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661698 |
| ANSWER_ID:53716789 |
| TITLE:调用函数去除列表中字符串的非字母 |
| ANSWER: 字符串对象的replace操作,是返回一个替换后的结果,而不是对原字符串对象进行修改,因此你需要把替换后的结果赋值给某个变量才行 |
| LINK:https://ask.csdn.net/questions/7661698?answer=53716789 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661305 |
| ANSWER_ID:53716409 |
| TITLE:为什么将含中文的URL复制到pycharm里面的就乱码了 |
| ANSWER: 关于这个,会牵扯到很久远的历史,最开始的字符输入或者传输是完全没有中文的,只有一些字母和符号,因此建立相关的通讯标准中也不存在中文。 |
| LINK:https://ask.csdn.net/questions/7661305?answer=53716409 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661128 |
| ANSWER_ID:53716311 |
| TITLE:mysql能否按照数值的相似度进行检索呢 |
| ANSWER: mysql没有自带的相似度计算函数,但是可以添加外部函数或者直接写算法来创建自定义函数来实现你需要的效果 similarity函数mysql_计算两个字符串的相似度mysql 自定义函数:Levenshtein_mysql_Mysql_数据库..._克里斯豆腐的博客-CSDN博客 1、功能描述:mysql 自定义函数。用来计算字符A转换成字符串B所花费的代价,数值越小,代价越低。(换句话来说,就计算两个字符串的相似度,值越小相似度越高)。该实现采用了编辑距离算法,详见:http://baike.baidu.com/link?url=EhmqDIoInSurOWI8VfR5bdmwxuYjPGKgqET2oNyv9--zDREhTUe5sYdxWLxS4v3tdK1PJVOF... https://blog.csdn.net/weixin_34392923/article/details/113194834 字符串相似度处理函数 - 5sdba - 博客园 oracle里面查比如存储过程里面与表SALES有关jobs: SELECT * FROM (SELECT a.name,upper(b.what)AS what,SYS.UTL_MATCH.edit https://www.cnblogs.com/5sdba-notes/p/12821175.html |
| LINK:https://ask.csdn.net/questions/7661128?answer=53716311 |
| SOURCE:CSDN_ASK |
| ASK_ID:7661002 |
| ANSWER_ID:53715997 |
| TITLE:提示 cannot import name 'version' from partially initialized module 'h5py' 是怎么了 |
| ANSWER: 这与h5py这个模块本身没有任何关系,这只是因为你循环导入了,
python 报错 most likely due to a circular import 解决方法_whatday的专栏-CSDN博客 原因各个python文件,互相引用,造成的 循环引用问题。解决方法:把需要引用的独立成一个文件,让其单向引用使用python写一个稍微大一点的工程时,经常会遇到循环import,即cicular import的问题。这篇文章会以flask里遇到的一个问题为原型,介绍一下cicular import产生的原因,以及python中使用import文件时,到底python在做什么。1. 一个circular import实例之前遇到一个circular import的问题,项目文件结构大概如下: https://blog.csdn.net/whatday/article/details/109333877 |
| LINK:https://ask.csdn.net/questions/7661002?answer=53715997 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660990 |
| ANSWER_ID:53715995 |
| TITLE:请问人工智能和大数据哪个专业好。。自由职业的话哪个好。。 |
| ANSWER: 人工智能和大数据,其实不能称之为职业,这只是两种工具而已,因此你的自由职业也不可能是这两个,就算你学会使用这两种工具了,没有落实到实际的行业中去的话也是白学。 很多情况下,这两个工具会一起使用来解决某些特定场景,比如人工智能需要大数据工具来提供大量的数据作为样本,然后人工智能计算出来的东西又可以补充回大数据。 |
| LINK:https://ask.csdn.net/questions/7660990?answer=53715995 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660927 |
| ANSWER_ID:53715932 |
| TITLE:问题是这个“查找尤金•奧尼爾EUGENE O'NEILL得獎的所有細節”,不明白为什么答案的O和‘之间要加| |
| ANSWER: 楼上说得对,我再补充一下。
|
| LINK:https://ask.csdn.net/questions/7660927?answer=53715932 |



| SOURCE:CSDN_ASK |
| ASK_ID:7660906 |
| ANSWER_ID:53715926 |
| TITLE:关于聚合函数的查询问题 |
| ANSWER: 你select 字段的顺序,会决定查询结果字段的输出顺序。在sql查询中,字段顺序本身其实也是一个要求
但你输出的字段顺序是:
这当然不对了 |
| LINK:https://ask.csdn.net/questions/7660906?answer=53715926 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660896 |
| ANSWER_ID:53715868 |
| TITLE:请问大家mysql为什么delete会没有办法删除空行呀 |
| ANSWER: 因为你条件写错了,null不能用等于号判断,只能用is |
| LINK:https://ask.csdn.net/questions/7660896?answer=53715868 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660877 |
| ANSWER_ID:53715857 |
| TITLE:利用SQL命令创建数据库失败 |
| ANSWER: 因为你这个命令里,主文件和日志文件重名了,建议仔细阅读官方文档,看看你的代码有什么区别 创建数据库 - SQL Server | Microsoft Docs 了解如何使用 SQL Server Management Studio 或 Transact-SQL 在 SQL Server 2019 中创建数据库。 查看有关该过程的建议。 https://docs.microsoft.com/zh-cn/sql/relational-databases/databases/create-a-database?view=sql-server-ver15 |
| LINK:https://ask.csdn.net/questions/7660877?answer=53715857 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660859 |
| ANSWER_ID:53715838 |
| TITLE:电脑打不开一直蓝屏 重启也是这样 |
| ANSWER: 傻了,竟然有这种坑人教程,把整个software都删了,这个里面是电脑里几乎所有软件的配置,包括操作系统自带的后台服务软件。。。 我去找了下你图里这个百度知道的链接,下面一堆评论都在骂人。。。 |
| LINK:https://ask.csdn.net/questions/7660859?answer=53715838 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660804 |
| ANSWER_ID:53715833 |
| TITLE:mySql截取逗号,的问题 |
| ANSWER: 用 REGEXP_INSTR 函数找到第二个逗号出现的位置,再使用substr进行截取,如下
|
| LINK:https://ask.csdn.net/questions/7660804?answer=53715833 |

| SOURCE:CSDN_ASK |
| ASK_ID:7660791 |
| ANSWER_ID:53715829 |
| TITLE:银行1104报表:用EAST 数据做1104报表,能否覆盖全部报表数据需求? |
| ANSWER: 监管数据治理治什么?1104、EAST、客户风险系统数据简介 监管数据治理治什么?1104、EAST、客户风险系统数据简介 http://www.360doc.com/content/22/0114/12/30502061_1013214786.shtml |
| LINK:https://ask.csdn.net/questions/7660791?answer=53715829 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660784 |
| ANSWER_ID:53715825 |
| TITLE:sql查询同名同姓学生名单 |
| ANSWER: 你子查询打算怎么统计?你又不知道最多会有多少个同名同性的人,如果有100个你不是得嵌套100层? |
| LINK:https://ask.csdn.net/questions/7660784?answer=53715825 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660699 |
| ANSWER_ID:53715749 |
| TITLE:查询字母数字组合的id时(例如a01),显示报错“Unknown column in where clause”,请问是怎么回事? |
| ANSWER: 注意一下下面两个sql的区别 上面两个sql中,第2条是有问题的,sql里的字符串,需要使用单引号包裹,否则就会被认为是列名或参数名什么的,而非具体的值。 |
| LINK:https://ask.csdn.net/questions/7660699?answer=53715749 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660664 |
| ANSWER_ID:53715621 |
| TITLE:数据库sql语句LIkE的用法 |
| ANSWER: 这个其实就是通配符转义,因为百分号和下划线都是通配符,如果想找的就是百分号或者下划线时,需要使用escape来识别转义的字符 MYSQL escape用法_wongyi1的专栏-CSDN博客_mysql.escape 在sql like语句中,比如select * from user where username like '%nihao%',select * from user where username like '_nihao',其中%做为通配符通配多个,_作为通配符通配一个如果要真的去查询username中含有 % _ 的,需要使他们不再作为通配符将% _ 在like中转义,拿_为例,转义前:sele... https://blog.csdn.net/wongyi1/article/details/79432444 |
| LINK:https://ask.csdn.net/questions/7660664?answer=53715621 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660665 |
| ANSWER_ID:53715613 |
| TITLE:MySQL能做前端么? |
| ANSWER: mysql本身并不具有提供前端服务的功能,更别谈什么设计友好界面了。 |
| LINK:https://ask.csdn.net/questions/7660665?answer=53715613 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660343 |
| ANSWER_ID:53715552 |
| TITLE:sql语句删除字段里两个字符串里中间的字符 |
| ANSWER: 建议你先举个例子,这个"模糊内容"不是很理解。 如果是,要对双引号中包含有特定字符串的全部去掉,就要使用正则了,比如
如果是去除某个字段里,所有的双引号中间的文字
|
| LINK:https://ask.csdn.net/questions/7660343?answer=53715552 |


| SOURCE:CSDN_ASK |
| ASK_ID:7660347 |
| ANSWER_ID:53715537 |
| TITLE:python去掉字典中value的单引号 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7660347?answer=53715537 |

| SOURCE:CSDN_ASK |
| ASK_ID:7660404 |
| ANSWER_ID:53715522 |
| TITLE:Mysql如何一次添加100条数据 |
| ANSWER: 这么个简单的东西没必要还写个存储过程用循环去插,用下面这个就行了,原理是借助一张系统表的数值列,但是它上限是700 另外,你使用mysql命令行工具创建存储过程时,需要注意修改结束符定义,否则它识别到分号就以为命令完了,像你那段代码应该改成下面这样再去执行 |
| LINK:https://ask.csdn.net/questions/7660404?answer=53715522 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660467 |
| ANSWER_ID:53715509 |
| TITLE:求和问题1111111111111111111111(好像有点循环的意思) |
| ANSWER: 用的是什么数据库?还有数据库版本是多少? 为什么你的case when 不能显示0-5?既然可以3-5那么没理由不能0-5,除非你限制了where条件,建议你先把原结构放出来,可能更容易处理,否则就得像下面这个sql一样要去解析你拼出来的这个字符串了
对于某一行要进行重复聚合,要么查多次来union all,要么在不同的字段来case when 后再做一次行列转换
|
| LINK:https://ask.csdn.net/questions/7660467?answer=53715509 |


| SOURCE:CSDN_ASK |
| ASK_ID:7660330 |
| ANSWER_ID:53715127 |
| TITLE:【满意秒结】mysql语句问题,以下语句怎么改成mysql? |
| ANSWER: mysql中的定位字符串位置的函数叫做"instr",语法为 instr(字段 ,'要查找的字符串')
另外,mysql里也没有 "len",对应的函数为 "length" |
| LINK:https://ask.csdn.net/questions/7660330?answer=53715127 |

| SOURCE:CSDN_ASK |
| ASK_ID:7660302 |
| ANSWER_ID:53715124 |
| TITLE:oracle求后七日数据 |
| ANSWER: 你这又犯了和前一题一样的错误, and 和 or 放在一个层级了,所有的and 就会都变成 or ,要记得加括号啊。 |
| LINK:https://ask.csdn.net/questions/7660302?answer=53715124 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660261 |
| ANSWER_ID:53715122 |
| TITLE:insert用法,进行修改和删除 |
| ANSWER: insert命令本身,肯定只有插入;delete命令本身,肯定也只有删除。 |
| LINK:https://ask.csdn.net/questions/7660261?answer=53715122 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660225 |
| ANSWER_ID:53715045 |
| TITLE:这个mysql查询速度怎么样啊 |
| ANSWER: 评价关系型数据的性能,小数据量的单表查询根本没有什么好比的,因为别人看的都是大表的读写、多表关联的效率、索引命中率等较为复杂的场景。 |
| LINK:https://ask.csdn.net/questions/7660225?answer=53715045 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660255 |
| ANSWER_ID:53715036 |
| TITLE:oracle 相同数据,count统计为1 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7660255?answer=53715036 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660194 |
| ANSWER_ID:53714959 |
| TITLE:windows server2019装完系统怎么重启进不了系统 |
| ANSWER: 点继续,这个页面没有任何报错信息,正常选择高级启动,也可以看到这个界面 |
| LINK:https://ask.csdn.net/questions/7660194?answer=53714959 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660177 |
| ANSWER_ID:53714942 |
| TITLE:sql语句无法识别,怎么解决啊? |
| ANSWER: 你表里面是"passsword" ,但你sql里写的是 "password" ,这两个不一样,当然会报错了,如果你看不出差别,就一个一个字母去比较 |
| LINK:https://ask.csdn.net/questions/7660177?answer=53714942 |
| SOURCE:CSDN_ASK |
| ASK_ID:7660039 |
| ANSWER_ID:53714873 |
| TITLE:怎么在表格添加三组数据 |
| ANSWER: 你插入时有3个值,但你表里有5个字段,数据库不知道你想把这3个值分别插到哪个字段,所以你需要指定一下插哪几个字段,比如下面这样 |
| LINK:https://ask.csdn.net/questions/7660039?answer=53714873 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659955 |
| ANSWER_ID:53714691 |
| TITLE:insert 加 where条件 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7659955?answer=53714691 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659975 |
| ANSWER_ID:53714683 |
| TITLE:sql怎么获取连续最大id? |
| ANSWER: 先说下你的数据库类型以及数据库版本
|
| LINK:https://ask.csdn.net/questions/7659975?answer=53714683 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659890 |
| ANSWER_ID:53714681 |
| TITLE:SQL SERVER 里面 怎么取出特定的字符 |
| ANSWER: sqlserver支持with递归,可以在查询中实现类似循环的效果; |
| LINK:https://ask.csdn.net/questions/7659890?answer=53714681 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659880 |
| ANSWER_ID:53714582 |
| TITLE:java.sql.SQLSyntaxErrorException: ORA-01776: 无法通过联接视图修改多个基表 |
| ANSWER: 如果你的视图里是基于多个表join出来的数据,那么这个视图是无法进行update操作的,老老实实去一张一张表更新吧 |
| LINK:https://ask.csdn.net/questions/7659880?answer=53714582 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659610 |
| ANSWER_ID:53714463 |
| TITLE:提问mysql求年预算问题 |
| ANSWER: 把表结构贴出来一下,并且给一点样本数据,否则无法进行分析 |
| LINK:https://ask.csdn.net/questions/7659610?answer=53714463 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659616 |
| ANSWER_ID:53714458 |
| TITLE:datediff函数问题 |
| ANSWER: "jsonb_extract_path_text" 这个函数是postgresql的,sqlserver里面没有. |
| LINK:https://ask.csdn.net/questions/7659616?answer=53714458 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659794 |
| ANSWER_ID:53714447 |
| TITLE:一张菜单表,父菜单和子菜单都在这个表,有一个pid,查询所有菜单的时候怎么能一起把每个子菜单的父菜单都查出来 |
| ANSWER: 咋一看以为需要递归,但仔细一看,你只需要展现当前层级和父层级两个,不需要找祖父层级,那么使用简单的自关联即可 当然,如果你需要找到当前层级往上的所有层级,mysql8.0中可以使用with递归sql,写法也不复杂 |
| LINK:https://ask.csdn.net/questions/7659794?answer=53714447 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659797 |
| ANSWER_ID:53714433 |
| TITLE:oracle启用密码复杂度后现有的用户会强制要求修改密码吗? |
| ANSWER: 你可以再设置一个密码有效期,只要一登录就会提示密码过期了,然后用户就必须改了 |
| LINK:https://ask.csdn.net/questions/7659797?answer=53714433 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659686 |
| ANSWER_ID:53714381 |
| TITLE:数据库插入语句无反应,报出 |
| ANSWER: 你直接点运行,它是从第一行开始运行,你第一行是建表,这个表已经存在了,它当然就报错了。你要选中你要执行的语句,再点运行 |
| LINK:https://ask.csdn.net/questions/7659686?answer=53714381 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659704 |
| ANSWER_ID:53714376 |
| TITLE:SQLSERVER 某个表更新完数据后向另外一张表插入更新之后的数据,表结构相同,且数据量庞大,50W条。 |
| ANSWER: 你如果改成一条一条处理的话,估计会更慢,比较合适的方法是,你不要对所有50w都更新成0,而是使用循环批量更新, |
| LINK:https://ask.csdn.net/questions/7659704?answer=53714376 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659752 |
| ANSWER_ID:53714367 |
| TITLE:pgsql正则表达式匹配数字问题 |
| ANSWER: 先说一下你正则匹配是想实现什么效果?把10替换成别的东西?截取出10?还是只看是否包含? 如果是要把"10"替换掉,比如把"10"替换成"YY"
|
| LINK:https://ask.csdn.net/questions/7659752?answer=53714367 |

| SOURCE:CSDN_ASK |
| ASK_ID:7659662 |
| ANSWER_ID:53714231 |
| TITLE:怎么写一条sql语句查询出一个字段下不同情况的占比 |
| ANSWER: 先说明下数据库类型及版本,不同的数据库可以使用的函数有区别, 不直接上代码的原因是你提供的信息不全,
如果需要调整截断点以及输出格式
如果是oracle,还可以用更高级的WIDTH_BUCKET函数
在hive里或者其他数据库里甚至还有更多方案,以后提问sql一定要记得说清楚自己的数据库以及版本 |
| LINK:https://ask.csdn.net/questions/7659662?answer=53714231 |



| SOURCE:CSDN_ASK |
| ASK_ID:7659483 |
| ANSWER_ID:53713788 |
| TITLE:SQL的左外连接和右外连接 |
| ANSWER: 我查了下,两个输出是一模一样的,只是顺序有区别而已
你不对的原因,是你的sql中间多了一个分号,导致sql截断了,后面的where条件没有生效 |
| LINK:https://ask.csdn.net/questions/7659483?answer=53713788 |

| SOURCE:CSDN_ASK |
| ASK_ID:7659456 |
| ANSWER_ID:53713762 |
| TITLE:诡异的ora01861 文字与格式字符串不匹配 |
| ANSWER: 如果要确认视图的字段类型,可以查all_tab_cols视图 如果确认这个字段是date类型,那么你上面写的这两个sql都没问题,这个时候,还有两个地方可能有问题
|
| LINK:https://ask.csdn.net/questions/7659456?answer=53713762 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659067 |
| ANSWER_ID:53713744 |
| TITLE:oracle断号边界查询问题 |
| ANSWER: 正好刚刚在另一个问题里写了个类似的,改了一下
|
| LINK:https://ask.csdn.net/questions/7659067?answer=53713744 |

| SOURCE:CSDN_ASK |
| ASK_ID:7658965 |
| ANSWER_ID:53713678 |
| TITLE:请问oracle存储过程中几个表关联查询出一条数据,怎么拆分成几行数据并用来更新其他表 |
| ANSWER: 存储过程里,对于临时使用的值,不需要存到表里,要么存变量里,要么使用游标。 上面这个sql没有处理你的工作日,主要是因为每个公司的工作日都会有区别,而且法定节假日也是一个外部数据,这个只能你自己去匹配日期了 |
| LINK:https://ask.csdn.net/questions/7658965?answer=53713678 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659062 |
| ANSWER_ID:53713669 |
| TITLE:第一列等于1的不查询。 查询第一行等于3的,和上一行也等于3的,(就是找到第一个出现3的行),这两个等于3的行之间不能有等于1的并且相隔年份大于一年。 |
| ANSWER: 用模式匹配sql加开窗函数 先把空行都剔除,然后模式匹配进行连续统计,发现有1的时候断开,重新进行统计,借用lag开窗函数获取上n行的值,这个n就是连续统计值减1. Oracle 12c 的新功能:模式匹配查询 - Oracle开发 - ITPUB论坛-专业的IT技术社区 Oracle 12c 的新功能:模式匹配查询 ,ITPUB论坛-专业的IT技术社区 http://www.itpub.net/forum.php?mod=viewthread&tid=2057442&page=1&extra=#pid23315171 |
| LINK:https://ask.csdn.net/questions/7659062?answer=53713669 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659158 |
| ANSWER_ID:53713622 |
| TITLE:kafka 链接oracle 报错 operation not allowed from within a pluggable database |
| ANSWER: 因为你的kafka调用了oracle的DBMS_LOGMNR这个包,但是这个包只能在cdb的连接里使用,而你当前连接是个pdb,它就报错了 |
| LINK:https://ask.csdn.net/questions/7659158?answer=53713622 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659167 |
| ANSWER_ID:53713618 |
| TITLE:sql中select出现的问题 |
| ANSWER: 你这个是以十六进制形式表示一个二进制字节,x后面只能接两个字符,一个字节最大只能是 "FF",你输入长度为3的”100“,它当然会报错了,它报的这个错是语法错误。 |
| LINK:https://ask.csdn.net/questions/7659167?answer=53713618 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659324 |
| ANSWER_ID:53713602 |
| TITLE:远程连接阿里云服务器上的mysql,用sqlyog,出现以下问题 |
| ANSWER: 要么不用ssh,取消勾选ssh隧道再试; |
| LINK:https://ask.csdn.net/questions/7659324?answer=53713602 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659348 |
| ANSWER_ID:53713595 |
| TITLE:oracle数据库子查询 |
| ANSWER: 先给你的表结构和样本数据,要不然没办法对着你的数据进行说明。 |
| LINK:https://ask.csdn.net/questions/7659348?answer=53713595 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658917 |
| ANSWER_ID:53713397 |
| TITLE:impala中查询本用户下的表 |
ANSWER:impala CREATE TABLE语句_w3cschool CREATE TABLE语句用于在Impala中的所需数据库中创建新表。 创建基本表涉及命名表并定义其列和每列的数据类型。 语法以下是CREATE TABLE语句的语法。 这里,IF NOT EXISTS是一个可选的子句。 如果使用此子句,则只有在指定数据库中没有具有相同名称的现有表时,才会创建具_来自impala 教程,w3cschool编程狮。  https://www.w3cschool.cn/impala/impala_create_table_statement.html |
| LINK:https://ask.csdn.net/questions/7658917?answer=53713397 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659101 |
| ANSWER_ID:53713387 |
| TITLE:Mysql 普通索引的回表的问题? |
| ANSWER: 第2种写法简直是脱裤子放气。 |
| LINK:https://ask.csdn.net/questions/7659101?answer=53713387 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658904 |
| ANSWER_ID:53713366 |
| TITLE:pgsql修改 如何判断已经是否修改成功 |
| ANSWER: 这个,首先你得定义下什么叫修改成功? |
| LINK:https://ask.csdn.net/questions/7658904?answer=53713366 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658912 |
| ANSWER_ID:53713349 |
| TITLE:自动识别输入数的进制 |
| ANSWER: 你输入的数字是否存在特殊标志?比如十六进制 "0x00" 之类的? |
| LINK:https://ask.csdn.net/questions/7658912?answer=53713349 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658913 |
| ANSWER_ID:53713324 |
| TITLE:hive 如果做到两个月的数据关联 |
| ANSWER: 两种方法,
二、开窗函数 hive中的日期计算比较麻烦,需要转成unixtimestamp格式才能进行计算,下面这个sql就是获取 '2022-01' 的上一个月,并以相同格式表示,即 '2021-12' |
| LINK:https://ask.csdn.net/questions/7658913?answer=53713324 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658944 |
| ANSWER_ID:53713317 |
| TITLE:mycat1.6.7连接mysql8出现问题 |
| ANSWER: 你到这台服务器的 系统属性-高级-环境变量里看看,到底有没有设置JAVA_HOME这个环境变量
|
| LINK:https://ask.csdn.net/questions/7658944?answer=53713317 |

| SOURCE:CSDN_ASK |
| ASK_ID:7658978 |
| ANSWER_ID:53713296 |
| TITLE:多个LEFT JOIN语法问题 |
| ANSWER: 不同的条件,结果会不一样,视不同的业务场景而定
|
| LINK:https://ask.csdn.net/questions/7658978?answer=53713296 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659064 |
| ANSWER_ID:53713275 |
| TITLE:mysql数据库设置smallint |
| ANSWER: smallint字段设置成 UNSIGNED(即无符号) 的时候,才能放65535 |
| LINK:https://ask.csdn.net/questions/7659064?answer=53713275 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659069 |
| ANSWER_ID:53713252 |
| TITLE:微信公众平台开发过程中如何进行本地测试? |
| ANSWER: 使用微信公众开发平台官方提供的"微信开发者工具"
|
| LINK:https://ask.csdn.net/questions/7659069?answer=53713252 |

| SOURCE:CSDN_ASK |
| ASK_ID:7659040 |
| ANSWER_ID:53713236 |
| TITLE:关于sql解决递归时间查询的问题,开关机时间处理 |
| ANSWER: 请补充一下你的问题是什么 |
| LINK:https://ask.csdn.net/questions/7659040?answer=53713236 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659041 |
| ANSWER_ID:53713225 |
| TITLE:数据库怎么归类,困扰很久了求解答 |
| ANSWER: 首先,你这个分类是否为一个标准分类方式?这个分类是否已经在内部达成了共识? |
| LINK:https://ask.csdn.net/questions/7659041?answer=53713225 |
| SOURCE:CSDN_ASK |
| ASK_ID:7659050 |
| ANSWER_ID:53713213 |
| TITLE:在内网中,文件并发上传到服务器,能否提供一个具有可行性的思路? |
| ANSWER: 别人的文件服务器不是一台设备,人家是分布式的多台设备。无论是网络带宽、内存、cpu、还是磁盘读写,全面碾压你单机。 |
| LINK:https://ask.csdn.net/questions/7659050?answer=53713213 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658619 |
| ANSWER_ID:53713098 |
| TITLE:商品定价出售或拍卖如何设计数据表 |
| ANSWER: 需要拍卖的商品,在拍卖流程完结之后,这个商品就没有用了,因此不建议此类商品放在正常出售的商品表里。 |
| LINK:https://ask.csdn.net/questions/7658619?answer=53713098 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658668 |
| ANSWER_ID:53713086 |
| TITLE:关于#mysql#的筛选排序问题,如何解决? |
| ANSWER: 这和你上一题不差不多么, |
| LINK:https://ask.csdn.net/questions/7658668?answer=53713086 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658823 |
| ANSWER_ID:53713066 |
| TITLE:查询某地区的销量最高的产品,一直出错 |
| ANSWER: 你窗口函数里面的那个排序排的是什么东西?客户id去重求和?统计销量最高不是应该用销量字段么?如果一个客户购买了多次难道你只统计一次? |
| LINK:https://ask.csdn.net/questions/7658823?answer=53713066 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658846 |
| ANSWER_ID:53713057 |
| TITLE:Mysql查询结果分组 |
| ANSWER: 你是只需要一个汇总sql,还是要用sql输出json数组? 假设要进行行列转换 假设要转换成json,并且是mysql8.0以上 |
| LINK:https://ask.csdn.net/questions/7658846?answer=53713057 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658884 |
| ANSWER_ID:53713031 |
| TITLE:如何查询出date最新时间num=3和num最开始等于3,中间不能有num=1的并且时间要大于一年的两列数据 |
| ANSWER: 写个滑动窗口,将上一行和当前行求和,满足等于6,且两个日期差大于等于365天,提取出满足此条件的当前行,然后再以此为条件,从原数据里把对应的上一行也找到
|
| LINK:https://ask.csdn.net/questions/7658884?answer=53713031 |

| SOURCE:CSDN_ASK |
| ASK_ID:7658853 |
| ANSWER_ID:53712993 |
| TITLE:计算近几周数据然后汇总,sql问题 |
| ANSWER: mysql 8.0以上版本,可以使用with递归补充中间缺失的数据。
如果是mysql8.0以下,可以构造一个虚拟的列(可以用系统表),然后left join 上面汇总好的数据 |
| LINK:https://ask.csdn.net/questions/7658853?answer=53712993 |

| SOURCE:CSDN_ASK |
| ASK_ID:7658882 |
| ANSWER_ID:53712922 |
| TITLE:oracle打开sqlplus 无法解析指定的连接标识符 |
| ANSWER: 检查下你客户端的tnsnames.ora文件中是否你连接的这个数据库名称,以及默认客户端路径(环境变量)是否设置正确 |
| LINK:https://ask.csdn.net/questions/7658882?answer=53712922 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658537 |
| ANSWER_ID:53712424 |
| TITLE:更改新内容保存位置可以吗? |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7658537?answer=53712424 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658575 |
| ANSWER_ID:53712420 |
| TITLE:简单的excel问题 |
ANSWER:
明显方法1和2都比方法3要简单得多。。。当然前提是这个列里全部都是qq邮箱,如果存在某个值没有“@qq.com”时,出来的就不是qq号了。 |
| LINK:https://ask.csdn.net/questions/7658575?answer=53712420 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658588 |
| ANSWER_ID:53712417 |
| TITLE:mysql保存不了查询文件 |
| ANSWER: 可能程序权限不够,建议使用管理员用户启动,或者设置保存路径为其他文件夹 |
| LINK:https://ask.csdn.net/questions/7658588?answer=53712417 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658592 |
| ANSWER_ID:53712415 |
| TITLE:我知道学号怎么输出,对应输出语句我就不知道了 |
| ANSWER: 我解释一下楼上这个代码吧 然后他用了一个f,表示格式化字符串,当然你也可以直接用加号进行字符串拼接 |
| LINK:https://ask.csdn.net/questions/7658592?answer=53712415 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658489 |
| ANSWER_ID:53712387 |
| TITLE:商品省份归属统计,36行代码运行太慢,如何简化提速? |
| ANSWER: 一个sql就能同时取出所有省份的统计数据,干哈分这么多? 从数据库取数据不是你这么取的啊,哪有查一个列表的数据时,一个sql只查一个值的啊,你直接一个查询,然后循环输出结果不就好了? php如何查询mysql数据并显示-PHP问题-PHP中文网 php查询mysql数据并显示的方法:首先在数据库内创建表并插入多条数据;然后创建文件,使用header方法将页面的编码格式设置为【utf-8】;接着选择要操作的数据库,并将结果集数据转换为数组形式;最后在浏览器打开文件查看结果。 https://www.php.cn/php-ask-462898.html |
| LINK:https://ask.csdn.net/questions/7658489?answer=53712387 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658514 |
| ANSWER_ID:53712384 |
| TITLE:没人解的开了。。Oracle SQL 如何计算start date到end date小于30天,且加交易总数值小于两百万 |
| ANSWER: 你这题咋说没人解得开呢?
t表是模拟数据, 还是写个低版本的处理方法吧
这个sql在11g/12c/18c/19c/21c均测试通过。 |
| LINK:https://ask.csdn.net/questions/7658514?answer=53712384 |


| SOURCE:CSDN_ASK |
| ASK_ID:7658471 |
| ANSWER_ID:53712259 |
| TITLE:在安装VMware16.2.2的过程中,遇到另一个安装实例已在运行,正在退出。怎么办。 |
| ANSWER: 因为你之前已经启动一次安装程序了,那个安装程序还没安装完也没退出,你又启动一次安装程序,他当然会报这个错了 |
| LINK:https://ask.csdn.net/questions/7658471?answer=53712259 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658408 |
| ANSWER_ID:53712256 |
| TITLE:请教关于SAP中EDI的退货问题 |
| ANSWER: 这个与你的业务模型有关,重点是在库存管理的部分。
但无论怎么改,多一种业务类型肯定会需要对你当前业务模型及报表统计进行全盘的分析,看看哪里会有影响,并分析是否有可行的修改方案 |
| LINK:https://ask.csdn.net/questions/7658408?answer=53712256 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658411 |
| ANSWER_ID:53712246 |
| TITLE:mysql 查询用户表,如何关联每个用户的消费总数 #mysql |
| ANSWER: 问题描述不是很清楚
|
| LINK:https://ask.csdn.net/questions/7658411?answer=53712246 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658206 |
| ANSWER_ID:53712226 |
| TITLE:关于SQL 数据提取个数的疑问! |
| ANSWER: 其实就是取抽检个数为空的和排个序取前2的(nulls last,可是mysql没这个语法,用if和isnull处理成类似效果) 从你发出来的这个样本数据里看,没有出现重复的商品,貌似不需要求和?
|
| LINK:https://ask.csdn.net/questions/7658206?answer=53712226 |

| SOURCE:CSDN_ASK |
| ASK_ID:7658226 |
| ANSWER_ID:53712197 |
| TITLE:mysql多表数据库查询 |
| ANSWER: 看样子你这个库只是用于数据采集,并非是针对数据分析建立,因此建议再建个专门用于数据分析的数据仓,把你这些数据都同步进去,多个表的都合到一个表里去。 |
| LINK:https://ask.csdn.net/questions/7658226?answer=53712197 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658327 |
| ANSWER_ID:53712189 |
| TITLE:如何利用SQ乚查询语句查找需要的数据 |
| ANSWER: 假设是mysql 假设是要查满足条件的完整记录,开一次窗就行了 |
| LINK:https://ask.csdn.net/questions/7658327?answer=53712189 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657799 |
| ANSWER_ID:53711844 |
| TITLE:windows11系统,Edge浏览器,html网页获取SQLserver数据库信息的主流方式是什么? |
| ANSWER: 你这是做了个纯静态网页?没有后端服务的? |
| LINK:https://ask.csdn.net/questions/7657799?answer=53711844 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658140 |
| ANSWER_ID:53711831 |
| TITLE:如何从公网访问树莓派? |
| ANSWER: 如果你家是电信的网络,可以申请开通桥接模式和动态公网IP。
但无论是哪种,内网穿透的原理都一样,就是必须有一个公网服务,内网设备连上这个公网服务后,你访问这个公网服务对应的端口时,就会转发到你的内网设备上,所以,用别人的服务器要想网速快,会需要按流量收费,否则那1m2m的免费带宽会相当让人捉急 |
| LINK:https://ask.csdn.net/questions/7658140?answer=53711831 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658130 |
| ANSWER_ID:53711806 |
| TITLE:我遇到一个数据库数据字典设计的问题,请各位解惑一下该怎么设计,最好用navicat截个图 |
| ANSWER: 有啥要求?是否有多语言?要求单独字典表还是共用字典表? |
| LINK:https://ask.csdn.net/questions/7658130?answer=53711806 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657693 |
| ANSWER_ID:53711766 |
| TITLE:关于MYSQL三表联查的问题 |
| ANSWER: 这个表设计存在严重问题,尤其是表1和表2,为啥子要把主从关系中的多个从横着放啊,这样怎么去做join呢?未来如果要增加从的数据,岂不是要往后面加字段?
另外,GROUP_CONCAT这个函数你用显示错误说明你sql写错了,不能说因为你不知道正确的sql语法就说不能用吧? 如果把表结构改成我上面这个样子,这么点数据3表联查没有任何性能压力 |
| LINK:https://ask.csdn.net/questions/7657693?answer=53711766 |

| SOURCE:CSDN_ASK |
| ASK_ID:7657770 |
| ANSWER_ID:53711746 |
| TITLE:SQLserver 求1到3月,每月最后一天的各项的值 |
| ANSWER: 你sqlserver的版本是多少? |
| LINK:https://ask.csdn.net/questions/7657770?answer=53711746 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658032 |
| ANSWER_ID:53711713 |
| TITLE:sql查询语句 想要的结果是如果第一行时间数据为空的话,就拿第二行的时间数据显示 |
| ANSWER: 用开窗函数取个max |
| LINK:https://ask.csdn.net/questions/7658032?answer=53711713 |
| SOURCE:CSDN_ASK |
| ASK_ID:7658047 |
| ANSWER_ID:53711708 |
| TITLE:关于#oracle#的问题,请各位专家解答! |
| ANSWER: 这与安装oracle没关系,仔细回忆下你是不是改过区域、字符集、语言之类的东西,比如下面这个
|
| LINK:https://ask.csdn.net/questions/7658047?answer=53711708 |

| SOURCE:CSDN_ASK |
| ASK_ID:7657866 |
| ANSWER_ID:53711565 |
| TITLE:oracle查询出含有这个值的数据如何加密或者替换,只是替换查询的结果,数据库中的数据不变 |
| ANSWER: 用regexp_replace或者regexp_substr,可以对满足你指定的这个正则表达式的字符串进行替换或者截取,比如
|
| LINK:https://ask.csdn.net/questions/7657866?answer=53711565 |

| SOURCE:CSDN_ASK |
| ASK_ID:7657794 |
| ANSWER_ID:53711547 |
| TITLE:oracle 数据库,不同数据库的用户,可以互相授予权限吗? |
| ANSWER: bb用户在另一个数据库?这要在另一个数据库里建立访问你这个数据库的dblink |
| LINK:https://ask.csdn.net/questions/7657794?answer=53711547 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657080 |
| ANSWER_ID:53711045 |
| TITLE:求一个加密函数,但需要相同的值在不同的表中加密后,显示的结果相同 |
| ANSWER: 你这是sqlserver吧?标签咋写个golang。。。 像你那个例子根本不叫加密,原字符串直接就能识别出来,顶多算个扩充原有字符串 |
| LINK:https://ask.csdn.net/questions/7657080?answer=53711045 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657593 |
| ANSWER_ID:53711040 |
| TITLE:如何安装yum命令,在站内搜索到的结局方法好像都不好使 |
| ANSWER: iTerm2是MacOS的终端软件,yum是linux系统的软件安装工具, |
| LINK:https://ask.csdn.net/questions/7657593?answer=53711040 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657492 |
| ANSWER_ID:53710879 |
| TITLE:想开发一个monitor,用来管理salesforce上的case |
| ANSWER: 你这个salesforce是公司本地化部署的么?为啥不考虑一下把消息提醒集成到钉钉或者企业微信呢?这个对于你公司的技术人员应该不是什么大问题吧,反正有后台权限,可能都是有公共api的,就算没有,直接查下数据库再做个自动推送也不是什么难事。 |
| LINK:https://ask.csdn.net/questions/7657492?answer=53710879 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657462 |
| ANSWER_ID:53710794 |
| TITLE:正则表达式怎么提取可能出现的字符但不包括这个字符的内容 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7657462?answer=53710794 |

| SOURCE:CSDN_ASK |
| ASK_ID:7657473 |
| ANSWER_ID:53710776 |
| TITLE:sql中如何实现查询结果从小到大按行排列? |
| ANSWER: 请说明一下你用的什么数据库以及数据库版本 sql server 2008版本太老了,很多写法都不支持,而且也难得找个线上测试环境测试,我先分析一下吧。 即按照前3个字段,聚合第4个字段,并且让第4个字段从左至右排列。 sqlserver数据库查询问题-大数据-CSDN问答 CSDN问答为您找到sqlserver数据库查询问题相关问题答案,如果想了解更多关于sqlserver数据库查询问题 database、sqlserver、数据库、 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7648725?answer=53698372 按照上面这个方式对应到你这个题,sql如下
其实指定分隔符为逗号后,你输出到csv,自动就会变成多个列 |
| LINK:https://ask.csdn.net/questions/7657473?answer=53710776 |

| SOURCE:CSDN_ASK |
| ASK_ID:7657380 |
| ANSWER_ID:53710631 |
| TITLE:Word怎么恢复默认设置 |
| ANSWER: 页面布局,背景,删除页面背景
|
| LINK:https://ask.csdn.net/questions/7657380?answer=53710631 |

| SOURCE:CSDN_ASK |
| ASK_ID:7657369 |
| ANSWER_ID:53710621 |
| TITLE:erp系统中生产物料辅料如何规范命名 |
| ANSWER: 你这个就像个小型的品类管理哈,总而言之,其实就是定业务标准,下面几点可以参考一下
|
| LINK:https://ask.csdn.net/questions/7657369?answer=53710621 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657350 |
| ANSWER_ID:53710600 |
| TITLE:access锁定数字编号 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7657350?answer=53710600 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657228 |
| ANSWER_ID:53710569 |
| TITLE:按照特定字段进行分组排序,并更新序号 |
| ANSWER: 假设你用的是mysql8.0以上版本,
那么可以通过开窗函数获取分组序号
然后用这个查询去更新原表的字段
确认更新结果
|
| LINK:https://ask.csdn.net/questions/7657228?answer=53710569 |




| SOURCE:CSDN_ASK |
| ASK_ID:7657321 |
| ANSWER_ID:53710538 |
| TITLE:ORACLE数据库,我想使用用户B中的表,在用户A创建视图(VIEW) |
| ANSWER: 不确定你的目的是让用户A获得创建视图的权限还是让用户A能查到用户B的数据
|
| LINK:https://ask.csdn.net/questions/7657321?answer=53710538 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657306 |
| ANSWER_ID:53710498 |
| TITLE:如何获得数据库中SQL查询的查询树? |
| ANSWER: 你上面这个图是人家手工单独查表手工做的示意图,那个表里面怎么可能只有两行数据,如果数据很多,工具难道要把表里面的数据全部显示出来么? |
| LINK:https://ask.csdn.net/questions/7657306?answer=53710498 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656920 |
| ANSWER_ID:53710477 |
| TITLE:一句sql不会优化,一共三张表,是要查出不要的东西。 |
ANSWER:或者 |
| LINK:https://ask.csdn.net/questions/7656920?answer=53710477 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656933 |
| ANSWER_ID:53710468 |
| TITLE:python或者SQL如何将表格合并转置 |
| ANSWER: ORACLE和sqlserver都支持pivot来进行行列转换,而且超简单,
|
| LINK:https://ask.csdn.net/questions/7656933?answer=53710468 |

| SOURCE:CSDN_ASK |
| ASK_ID:7656983 |
| ANSWER_ID:53710451 |
| TITLE:使用navicate,删除数据时出现问题 |
| ANSWER: 先用sql,count一下整张表,看看这个表总共有多少行,
另外,你删除数据的时候where条件是咋写的?有没有先用这个where条件来查询一下数据看看查不查得出?你用乱码作为where条件是查不到数据的,因为存在不可见字符你复制不到,建议用其他非乱码的字段作为查询条件去删 |
| LINK:https://ask.csdn.net/questions/7656983?answer=53710451 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657018 |
| ANSWER_ID:53710436 |
| TITLE:关于#mysql#的问题:如何用MY SQL,按照月份进行拆分原始数据 |
| ANSWER: 这种题已经有不少人问过了,如果是mysql8.0以上,支持递归sql。
|
| LINK:https://ask.csdn.net/questions/7657018?answer=53710436 |

| SOURCE:CSDN_ASK |
| ASK_ID:7657072 |
| ANSWER_ID:53710321 |
| TITLE:服务器装的系统是server2012,装数据库sql2012卡在install_vsshell_cpu32_action:PublishProduct这个安装界面一直运行不下去了如何解决 |
| ANSWER: 只要没报错,建议先等1到2个小时再看 |
| LINK:https://ask.csdn.net/questions/7657072?answer=53710321 |


| SOURCE:CSDN_ASK |
| ASK_ID:7657170 |
| ANSWER_ID:53710307 |
| TITLE:sql server 复制一个数据库的sql 语句 |
| ANSWER: 你这个应该叫做数据库迁移,如果是同版本的话,可以用下面这个方式 数据存储迁移助手 (SQL Server) - SQL Server | Microsoft Docs 了解如何使用数据迁移助手将SQL Server数据库迁移到其他 SQL Server 或 Azure 数据库 https://docs.microsoft.com/zh-cn/sql/dma/dma-overview?view=sql-server-ver15 手把手教你如何进行SQL Server数据库迁移 - 知乎 概述本篇我们将利用DMA一步一步实现SQL Server 的迁移。帮助大家理解现在的SQL Server与新版本的融合问题,同时需要我们做哪些操作来实现新版本的升级或者迁移。 SQL Server 迁移一定要有一个准备好的计划,我下面… https://zhuanlan.zhihu.com/p/33670509 |
| LINK:https://ask.csdn.net/questions/7657170?answer=53710307 |
| SOURCE:CSDN_ASK |
| ASK_ID:7657157 |
| ANSWER_ID:53710291 |
| TITLE:这段SQL语句的各个意思? |
| ANSWER: 这段sql里没看到有任何特殊的语法,关联几个表求个和而已,不知道你是哪里看不懂。
|
| LINK:https://ask.csdn.net/questions/7657157?answer=53710291 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656302 |
| ANSWER_ID:53709622 |
| TITLE:SQLserver AVG函数求1到3月的各项平均值 |
| ANSWER: 你把你的else 0都删掉试试。 avg不对的原因是,它的算法是求和再除以非空的行数,你这行数没有发生变化,不是指定月份的数据你给了个0,它当然数据会偏小了 另外,你确定不在后面加个where条件限定下查询数据的范围么?你这样查,整个表的数据都扫到了 |
| LINK:https://ask.csdn.net/questions/7656302?answer=53709622 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656782 |
| ANSWER_ID:53709613 |
| TITLE:windows server部署mysql大家都用管理员用户部署还是普通用户部署 |
| ANSWER: windows上的服务,如果涉及到文件的读写,你不给个管理员身份就很容易遇到各种奇奇怪怪的问题,所以建议还是放到服务里去。 |
| LINK:https://ask.csdn.net/questions/7656782?answer=53709613 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656752 |
| ANSWER_ID:53709481 |
| TITLE:请教!有什么办法可以把D盘剩余的空间匀出来一些给C盘,现在D盘还剩150个G,C盘只剩下14个G了T_T |
| ANSWER: 在PE下使用diskgenius可以把D盘切一部分出来,然后合到C盘, |
| LINK:https://ask.csdn.net/questions/7656752?answer=53709481 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656730 |
| ANSWER_ID:53709464 |
| TITLE:为什么CSDN网页界面这么大? |
| ANSWER: 按住ctrl,然后鼠标滚轮往下滚 |
| LINK:https://ask.csdn.net/questions/7656730?answer=53709464 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656705 |
| ANSWER_ID:53709458 |
| TITLE:打开网站但是需要使用微信继续打开如果跳过 |
| ANSWER: 如果它没做微信号身份验证的话,那么改下请求头就好了 |
| LINK:https://ask.csdn.net/questions/7656705?answer=53709458 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656711 |
| ANSWER_ID:53709453 |
| TITLE:字符型常量和整型常量有什么关系吗 |
| ANSWER: 字符就是文本,可以放数字字母符号以及各国语言文字; |
| LINK:https://ask.csdn.net/questions/7656711?answer=53709453 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656713 |
| ANSWER_ID:53709450 |
| TITLE:第27题:圆括号的优先级不是应该比其他的优先级高嘛,为什么先算了a+b |
| ANSWER: 按这个题应该是这个意思, |
| LINK:https://ask.csdn.net/questions/7656713?answer=53709450 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656715 |
| ANSWER_ID:53709437 |
| TITLE:mysql一个小的建表问题 |
| ANSWER: 语法不对,为什么建表连字段名都不写? |
| LINK:https://ask.csdn.net/questions/7656715?answer=53709437 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656440 |
| ANSWER_ID:53709412 |
| TITLE:sql一张表的嵌套查询 |
| ANSWER: 用原表关联你查出来的这个数据,关联条件为原表的时间小于你查出来的这个数据的时间就行了,由于不清楚你这个id是什么东西,还有用户字段是啥,也不知道你原表长什么样子,也不知道还有些别的什么字段,因此无法给出sql。 |
| LINK:https://ask.csdn.net/questions/7656440?answer=53709412 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656594 |
| ANSWER_ID:53709406 |
| TITLE:Oracle VM VirtualBox恢复备份是灰色的 |
| ANSWER: 正在运行的机器是不能备份的,因为数据一直在变,请先关机再进行备份 |
| LINK:https://ask.csdn.net/questions/7656594?answer=53709406 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656667 |
| ANSWER_ID:53709398 |
| TITLE:plsql怎么批量修改如下数据 |
| ANSWER: oracle12c开始,提供了一些函数支持json的读写操作
如果是要更新表里面的数据的话,直接一个update 就完事了,当然前提是你要确保字符串规则是完全一致的 |
| LINK:https://ask.csdn.net/questions/7656667?answer=53709398 |

| SOURCE:CSDN_ASK |
| ASK_ID:7656566 |
| ANSWER_ID:53709371 |
| TITLE:刚学pl/SQL,想问一下怎样可以判断等腰直角三角形 |
| ANSWER: 你这段plsql逻辑看上去没问题,你想问的是怎么输入参数能识别成等腰直角三角形吧?
|
| LINK:https://ask.csdn.net/questions/7656566?answer=53709371 |

| SOURCE:CSDN_ASK |
| ASK_ID:7656196 |
| ANSWER_ID:53708998 |
| TITLE:谁能翻译一下这段内容,是Oracle的 |
| ANSWER: 这玩意直接翻译出来你也不一定能懂,我换种方式说明一下吧
上面这个sql里,执行计划就有nested loop,它就相当于套了两个循环,下面是伪代码 最外层循环的employees 叫驱动表,因为它先定义了数据范围job_id='101',然后把这个数据中的每一行丢到内部再循环获取departments 的数据 |
| LINK:https://ask.csdn.net/questions/7656196?answer=53708998 |

| SOURCE:CSDN_ASK |
| ASK_ID:7656360 |
| ANSWER_ID:53708968 |
| TITLE:dbeaver连接数据库报错 |
| ANSWER: 检查下这台数据库的SQLNET.ora文件里是不是做了什么特殊配置
Got minus one from a read call异常 - lclc - 博客园 Caught: java.sql.SQLException: Io 异常: Got minus one from a read call 使用JDBC连接Oracle时,多次出现上述错误,后来去网上找 https://www.cnblogs.com/lcword/p/8035651.html |
| LINK:https://ask.csdn.net/questions/7656360?answer=53708968 |

| SOURCE:CSDN_ASK |
| ASK_ID:7656318 |
| ANSWER_ID:53708947 |
| TITLE:SQL 两列,第一列ID相同,第二列数据不全,增加第三列根据ID补全空值 |
| ANSWER: 我和楼上考虑的点是一样的,第二列存在多种值的时候,第三列的规则应该是怎样的?excel的vlookup是取的从上往下数第一条. |
| LINK:https://ask.csdn.net/questions/7656318?answer=53708947 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656031 |
| ANSWER_ID:53708929 |
| TITLE:JDBC 的初始问题 统一资源定位符 |
| ANSWER: 猜测一下哈,后面单独设置的属性会被当成字符串拼接,而拼接的规则就是在原字符串上 +"&" +key+"=" +value,如果原字符串后面没有任何参数的话,那连接串的格式就错了,所以至少得先接一个参数 |
| LINK:https://ask.csdn.net/questions/7656031?answer=53708929 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656038 |
| ANSWER_ID:53708917 |
| TITLE:Oracle下载第七步卡在42% |
| ANSWER: 卡住不动等了多久了?oracle数据库安装有时候的确会出现卡进度条的假象,因为某一步操作需要消耗很长时间,而这个进度条又不是按照消耗时长均匀分配的长度。建议先等个1到2小时再看 有没有把杀毒软件什么的都关掉? 安装这种大型服务软件的时候,只要确保软件来源是可信的情况下,建议关闭所有三方安全软件及杀毒软件,因为这些所谓的安全软件会限制安装程序写注册表、注册动态库、以及复制文件到关键位置等等操作,然后好一点的安装软件就会不断重试,造成了卡在那里的假象 |
| LINK:https://ask.csdn.net/questions/7656038?answer=53708917 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656147 |
| ANSWER_ID:53708906 |
| TITLE:高斯数据库,发现字段中英文混合,截取发现为字节数,汉字截取报错了 |
| ANSWER: 你是不是用错函数了,不要用结尾带b的那个。 |
| LINK:https://ask.csdn.net/questions/7656147?answer=53708906 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656340 |
| ANSWER_ID:53708893 |
| TITLE:怎么把数据导入html中以表格显示出来? |
| ANSWER: 纯静态网页,不借助其他开发语言的话,可以用excel公式去拼标签。 |
| LINK:https://ask.csdn.net/questions/7656340?answer=53708893 |
| SOURCE:CSDN_ASK |
| ASK_ID:7656008 |
| ANSWER_ID:53708286 |
| TITLE:用审查元素的方式修改公司网页内容,然后把保存按钮显示出来,就可以保存修改后的数据 |
| ANSWER: 因为公司发现了这个漏洞,就做了控制呗,这种控制前端后端数据库里都能做。 |
| LINK:https://ask.csdn.net/questions/7656008?answer=53708286 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655967 |
| ANSWER_ID:53708240 |
| TITLE:有没有人能给个将oracle数据库里指定表的所有字段名从小写修改成大写的脚本? |
| ANSWER: 刚好写过这个玩意,实际上就是循环拼接动态sql来执行 |
| LINK:https://ask.csdn.net/questions/7655967?answer=53708240 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655926 |
| ANSWER_ID:53708200 |
| TITLE:python无法创建数据库 |
| ANSWER: 先把完整运行的代码和报错截图贴出来,因为并不确定你代码里其他地方是否有问题,单一个建表语句看不出,还有,生成不了肯定有个报错提示啊,报错提示里会告诉你为什么生成不了。 下面这个教程有完整的语法说明,你可以看一下,是不是有哪里和你理解的不一样 SQLite – Python | 菜鸟教程 SQLite - Python 安装 SQLite3 可使用 sqlite3 模块与 Python 进行集成。sqlite3 模块是由 Gerhard Haring 编写的。它提供了一个与 PEP 249 描述的 DB-API 2.0 规范兼容的 SQL 接口。您不需要单独安装该模块,因为 Python 2.5.x 以上版本默认自带了该模块。 为了使用 sqlite3 模块,您首先必须创建一个表示数据库的连接对象,然后您可以有选择地创..  https://www.runoob.com/sqlite/sqlite-python.html |
| LINK:https://ask.csdn.net/questions/7655926?answer=53708200 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655889 |
| ANSWER_ID:53708188 |
| TITLE:sublime中读取不了文件 |
| ANSWER: 它这提示的就是没有这个文件,你去计算机的c盘下的file目录里看看这个文件在不在,还有文件名以及后缀是否正确 |
| LINK:https://ask.csdn.net/questions/7655889?answer=53708188 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655911 |
| ANSWER_ID:53708183 |
| TITLE:mysql亿级数据量的时候,大家帮看看这个sql如何优化呢? |
| ANSWER: 只从个sql上看的话, 另外,都已经亿级了,就不能做成分区表么?如果查询条件带分区字段,查询效率会提高不少 |
| LINK:https://ask.csdn.net/questions/7655911?answer=53708183 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655850 |
| ANSWER_ID:53708179 |
| TITLE:恢复出厂设置可以恢复注册表误删吗? |
| ANSWER: win10中的高级启动菜单里的确有恢复出厂的操作,但是这会删掉系统里所有你后来安装的软件,而且会删掉你所有的文件,请慎重执行。 |
| LINK:https://ask.csdn.net/questions/7655850?answer=53708179 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655851 |
| ANSWER_ID:53708176 |
| TITLE:Window文件夹日志的错误怎么解决 |
| ANSWER: 看上去是与NV显卡有关的问题,网上有不少人都有同样的问题,但引起的原因有很多
|
| LINK:https://ask.csdn.net/questions/7655851?answer=53708176 |

| SOURCE:CSDN_ASK |
| ASK_ID:7655862 |
| ANSWER_ID:53708169 |
| TITLE:装了Linux之后,是这个页面。是我用的光盘不一样吗,为啥没有也没有。终端都找不到 |
| ANSWER: 你这个安装的是带有图形化界面的linux系统, |
| LINK:https://ask.csdn.net/questions/7655862?answer=53708169 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655837 |
| ANSWER_ID:53708132 |
| TITLE:mysql已经配好了环境变量,命令行窗口为什么还是不能用 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7655837?answer=53708132 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655817 |
| ANSWER_ID:53708110 |
| TITLE:mysql 拆分表,怎么查询? |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7655817?answer=53708110 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655781 |
| ANSWER_ID:53708106 |
| TITLE:如何读取mysql的结果实现with open读取txt的效果 |
| ANSWER: 你是想实现这种效果?
或者和txt里一样?
|
| LINK:https://ask.csdn.net/questions/7655781?answer=53708106 |


| SOURCE:CSDN_ASK |
| ASK_ID:7655769 |
| ANSWER_ID:53708067 |
| TITLE:SQL 两列,第一列ID相同,第二列数据不全,增加第三列,根据ID补全空值 |
ANSWER:
比如下面这个数据要变成什么样子 |
| LINK:https://ask.csdn.net/questions/7655769?answer=53708067 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655741 |
| ANSWER_ID:53708022 |
| TITLE:win10安装MySQL connector/python 失败 |
| ANSWER: 鼠标右键,使用管理员身份运行,其实你贴的这个信息里面已经有失败原因和建议你要怎么操作了
大概翻译过来就是:安装程序没有这个目录的权限,安装不能继续,用管理员身份登录或者联系你的系统管理员 |
| LINK:https://ask.csdn.net/questions/7655741?answer=53708022 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655713 |
| ANSWER_ID:53708008 |
| TITLE:视图 left join 一个千万级别的表查询非常慢已建立索引 |
| ANSWER: 对于硬件配置较好的oracle数据库来说,千万行真不是什么问题。
以上是单从逻辑上来分析,另外,oracle21c支持一些新特性,比如sql宏,可以让视图外的查询条件写到视图内的子查询中,但NC系统估计是不会用这个oracle版本的 【ORACLE】21版本新特性之SQL宏(SQL MACROS)的分析_DarkAthena的博客-CSDN博客 前言在21c发布后,很多文章中都提到了SQL宏,但看到的人们大多都有个疑问,这个SQL宏看上去和一般的函数没什么区别,为什么还要重点拿出来说?我们先看看ORACLE官方是怎么说的https://docs.oracle.com/en/database/oracle/oracle-database/21/nfcon/sql-macros-282902288.htmlYou can create SQL Macros (SQM) to factor out common SQL expressions https://darkathena.blog.csdn.net/article/details/121412432 |
| LINK:https://ask.csdn.net/questions/7655713?answer=53708008 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655705 |
| ANSWER_ID:53707985 |
| TITLE:MySQL语句问题,初学者 |
| ANSWER: 从你这两个表上来看,应该是想要tb_user的desc_id 来自于tb_user_desc 的id吧,那么外键就应该放在tb_user这个表上,按照普通的外键方式建立,这没有任何问题。 |
| LINK:https://ask.csdn.net/questions/7655705?answer=53707985 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655451 |
| ANSWER_ID:53707862 |
| TITLE:linux 有哪些在使用命令时 需要加 / |
| ANSWER: 主要是避免歧义问题,假设你在bin下有一个python程序,然后下载了一个绿色版python放到了 /python3 文件夹下, |
| LINK:https://ask.csdn.net/questions/7655451?answer=53707862 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655574 |
| ANSWER_ID:53707855 |
| TITLE:关机后vscode的应用变成了unins0000.exe,怎么还原vscode |
| ANSWER: 这个不是变成了unins0000.exe,而是本来就有一个unins0000.exe,这个玩意是卸载程序,你打开它就会卸载vscode,这个文件夹下完整的文件是这样的
既然已经被卸载了,当然只能重新安装了 |
| LINK:https://ask.csdn.net/questions/7655574?answer=53707855 |

| SOURCE:CSDN_ASK |
| ASK_ID:7655386 |
| ANSWER_ID:53707853 |
| TITLE:sql2012下载失败 |
| ANSWER: 你下载这个的这个是sqlserver2012.rar,先鼠标右键点它,选解压到当前文件夹, |
| LINK:https://ask.csdn.net/questions/7655386?answer=53707853 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655409 |
| ANSWER_ID:53707849 |
| TITLE:树莓派解压时找不到路径 |
| ANSWER: 在Desktop这个路径下执行ls,看看到底有没有这个文件 |
| LINK:https://ask.csdn.net/questions/7655409?answer=53707849 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655432 |
| ANSWER_ID:53707847 |
| TITLE:git push报错怎么解决 |
| ANSWER: 如果是github的话,建议隔一会儿重试,因为国内访问github并不稳定,间歇性抽风 |
| LINK:https://ask.csdn.net/questions/7655432?answer=53707847 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655463 |
| ANSWER_ID:53707845 |
| TITLE:下载数据库相关软件时遇到这个问题怎么解决? |
| ANSWER: 安装目录请不要使用中文等非英文字符 |
| LINK:https://ask.csdn.net/questions/7655463?answer=53707845 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655510 |
| ANSWER_ID:53707842 |
| TITLE:一键重装xp系统后ie浏览器网页图片全部不显示全部是红色的x。 |
| ANSWER: winXP自带浏览器是IE6,目前大多数页面都不支持IE6了,请下载其他浏览器进行访问。 |
| LINK:https://ask.csdn.net/questions/7655510?answer=53707842 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655557 |
| ANSWER_ID:53707840 |
| TITLE:关于#android#的问题:请教一下如何制作安卓L2TP和PPTP拨号器? |
| ANSWER: 提示一下,安卓是开源的,所以完全可以在安卓源码中找到相关代码是怎么写的。。。 可以去安卓开源项目官网获得下载源代码的方式
不过国内貌似不能直接访问哦 |
| LINK:https://ask.csdn.net/questions/7655557?answer=53707840 |

| SOURCE:CSDN_ASK |
| ASK_ID:7655539 |
| ANSWER_ID:53707837 |
| TITLE:第三范式传递依赖判断 |
| ANSWER: 按照不同的表结构设计(或者说业务逻辑设计),这个既可以依赖也可以不依赖。 |
| LINK:https://ask.csdn.net/questions/7655539?answer=53707837 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655500 |
| ANSWER_ID:53707826 |
| TITLE:sql语句询问(我有这三列数据,需要找到人数前10的作品,其对应的作者的全部作品 这用sql语句该怎么写?) |
| ANSWER: 问sql题的时候,请提供你的数据库类型以及版本, 然后,题主要求的不仅仅是取前十行,而是要求的取前十行的数据,提取出作者,然后再取这些作者的所有书,因此楼上专家的答案有点问题 以mysql为例,按照这个逻辑直接写的出sql是这样的 |
| LINK:https://ask.csdn.net/questions/7655500?answer=53707826 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655348 |
| ANSWER_ID:53707815 |
| TITLE:rootkit病毒会由U盘传播吗 |
| ANSWER: 移动存储设备中的病毒向外扩散的方式,大多数都是通过"自动播放"这一功能,因此建议在电脑系统中设置关闭自动播放。这样插上去就不会自动扩散(针对大多数病毒)。 |
| LINK:https://ask.csdn.net/questions/7655348?answer=53707815 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655150 |
| ANSWER_ID:53707577 |
| TITLE:笔记本不支持高清摄像头 |
| ANSWER: 可以从三方面考虑
|
| LINK:https://ask.csdn.net/questions/7655150?answer=53707577 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655283 |
| ANSWER_ID:53707561 |
| TITLE:对象存储oss文件上传 |
| ANSWER: 你数据库里这个字段的字段类型是啥? |
| LINK:https://ask.csdn.net/questions/7655283?answer=53707561 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654415 |
| ANSWER_ID:53707552 |
| TITLE:mysql的json_extract函数碰到部分数据为空报错 |
| ANSWER: 条件加下面不行,那就加上面呗 |
| LINK:https://ask.csdn.net/questions/7654415?answer=53707552 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655052 |
| ANSWER_ID:53707529 |
| TITLE:grace level2数据下载 |
| ANSWER:
你这个网址里说在 ftp://podaac.jpl.nasa.gov/allData/grace/L2/CSR/RL06/ 这里看,但我这里打开太慢,不确定里面是不是还有数据,所以顺藤摸瓜找到了其官网,如下 但这个里面L2的文件夹是空的,L3的还有数据
另外,这个地址国内不能访问。。。 |
| LINK:https://ask.csdn.net/questions/7655052?answer=53707529 |


| SOURCE:CSDN_ASK |
| ASK_ID:7655124 |
| ANSWER_ID:53707507 |
| TITLE:MySql多对多,怎么插入中间表 |
| ANSWER: 从你这个3个表的关系来看,应该要有3个维护操作,分别对应这3张表
但是,如果你这个关系表就这么3个字段,而且user和group是一对一的关系,那么单独做这张表没有意义的,还不如在user表里再加一个gno字段,并修改一下操作流程
|
| LINK:https://ask.csdn.net/questions/7655124?answer=53707507 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655142 |
| ANSWER_ID:53707503 |
| TITLE:navicate导入表格时候出现Unknown system variable 'innodb_large_prefix'错误?如何解决 |
| ANSWER: mysql8里没有这个系统参数了,可以跳过这行代码不执行
|
| LINK:https://ask.csdn.net/questions/7655142?answer=53707503 |

| SOURCE:CSDN_ASK |
| ASK_ID:7655203 |
| ANSWER_ID:53707497 |
| TITLE:MySQL中的一个字段的默认值为另外两个字段值的拼接,如何实现? |
| ANSWER: 参考语法 这个 AS 括号里面的东西就是整个函数表达式 MySQL :: MySQL 5.7 Reference Manual :: 13.1.18.7 CREATE TABLE and Generated Columns https://dev.mysql.com/doc/refman/5.7/en/create-table-generated-columns.html 根据你这个例子,其实就是
|
| LINK:https://ask.csdn.net/questions/7655203?answer=53707497 |

| SOURCE:CSDN_ASK |
| ASK_ID:7655112 |
| ANSWER_ID:53707480 |
| TITLE:mysql第七题 查询不会 求解 |
| ANSWER: 两个表join,然后按部门聚合,汇总收入,用having 筛出大于9000 的 你信不信我这查询结果是对的,但你老师可能会判错,因为可能更多人是下面这么写的 但是你可以发现,我给的第一个sql只group by 了一个字段,因为部门编号本就是唯一,再按部门名称group by 没有意义了,会拖慢性能, |
| LINK:https://ask.csdn.net/questions/7655112?answer=53707480 |
| SOURCE:CSDN_ASK |
| ASK_ID:7655040 |
| ANSWER_ID:53707327 |
| TITLE:WPS无法打开文件怎么办 |
| ANSWER: 你之前是不是开启了文件加密功能? NTFS分区加密文件,重装了系统后,无法打开了,怎么办?_无线网络世界的技术博客_51CTO博客 NTFS分区加密文件,重装了系统后,无法打开了,怎么办?,NTFS请选用以下方法: Pleaseselectfollowingmethod:A1:用ntfsdos启动进入X盘,把所需文件夹拷贝到没加密的分区中。或者先用ghost制作X盘的分区影像文 https://blog.51cto.com/wirless/291100 |
| LINK:https://ask.csdn.net/questions/7655040?answer=53707327 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654996 |
| ANSWER_ID:53707269 |
| TITLE:取出每个人最后更新的那条 |
| ANSWER: 问sql以及数据库相关的题,请先说明使用的数据库类型以及数据库版本,因为不同数据库支持的sql写法不一样; 但是如果这个表里不止这两个字段,而且要取出完整的行记录时,则需要使用开窗函数。 |
| LINK:https://ask.csdn.net/questions/7654996?answer=53707269 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654936 |
| ANSWER_ID:53707264 |
| TITLE:怎么使用msql对中文列转行[无奈] |
ANSWER:
另外,如果你英文列可以转,那么中文列也可以使用同样的方法转,这两者在逻辑上并没有什么区别 mysql 5.7 及以下版本支持的sql写法比8少多了,所以写这种sql会比较繁琐。
另外,其实这种数据处理,如果允许导出数据,那么在excel中全选复制、选择性粘贴、勾上转置的方式来处理要快得多 |
| LINK:https://ask.csdn.net/questions/7654936?answer=53707264 |

| SOURCE:CSDN_ASK |
| ASK_ID:7654957 |
| ANSWER_ID:53707261 |
| TITLE:sql求出每两个相邻的时间差 |
| ANSWER: 问sql以及数据库相关的题,请先说明使用的数据库类型以及数据库版本,因为不同数据库支持的sql写法不一样; 如果是sqlserver,在使用开窗函数获得上一行的时间后,用 datediff(second, 开始日期,结束日期) 来计算时间差 但sqlserver2008版本太老了,不确定是否有lag函数,当前没有环境可以测试
微软官方都没有提供这个版本的文档了
刚在官网一个角落找到了sqlserver2008r2的文档,里面没有介绍有关开窗函数的内容 内置函数 (Transact-SQL) | Microsoft Docs https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms174318(v=sql.105) 除了使用开窗函数以外,要在本行查询到非本行数据,只能使用自关联了, |
| LINK:https://ask.csdn.net/questions/7654957?answer=53707261 |


| SOURCE:CSDN_ASK |
| ASK_ID:7654917 |
| ANSWER_ID:53707241 |
| TITLE:装机方面遇到问题急需解决,有偿 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7654917?answer=53707241 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654164 |
| ANSWER_ID:53707232 |
| TITLE:按照查询条件,分别把 表#tb02 的 w1~11 替换成对应的数字,并每一行从小到大排序 |
| ANSWER: sql来了
除了你曾经提出的这些问题以外,我是真没见过拿数据库做这种事的。 |
| LINK:https://ask.csdn.net/questions/7654164?answer=53707232 |

| SOURCE:CSDN_ASK |
| ASK_ID:7654528 |
| ANSWER_ID:53707137 |
| TITLE:关于#sql#的问题,请各位专家解答! |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7654528?answer=53707137 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654912 |
| ANSWER_ID:53707128 |
| TITLE:为什么这个SQL语句一直不正确 |
| ANSWER: 左上角切换一下数据库类型,因为sqlite数据库不支持comment添加字段注释 |
| LINK:https://ask.csdn.net/questions/7654912?answer=53707128 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654812 |
| ANSWER_ID:53707107 |
| TITLE:连接本地数据库没有问题,但是连接服务器数据库报错No operations allowed after connection closed.怎么解决 |
ANSWER:
连接不可用,请求超时 |
| LINK:https://ask.csdn.net/questions/7654812?answer=53707107 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654879 |
| ANSWER_ID:53707100 |
| TITLE:join和select子句中的子查询 效率比较 |
| ANSWER: 这两种方式在不同场景下,效率可能各有高低,主要是看这两个表中的记录数、通过where限制条件后需要展示的记录数、主表(或者说一个主查询SQL)是否为一个比较复杂的查询。 |
| LINK:https://ask.csdn.net/questions/7654879?answer=53707100 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654689 |
| ANSWER_ID:53706819 |
| TITLE:请问一下这里的 is是用来比较地址是否一致的吗 还有A和C不是一个形式吗 为什么x is y输出不为True呢? |
| ANSWER: XY和MN的区别在于,XY是浮点,MN是整型
is 比较的东西,可以理解为是 id() 返回的值,在这里可以发现,对于值相同的两个浮点,返回的地址是不一样的,至于为什么会不一样,这是python的规则 而且还有个与这个题类似的
|
| LINK:https://ask.csdn.net/questions/7654689?answer=53706819 |



| SOURCE:CSDN_ASK |
| ASK_ID:7653998 |
| ANSWER_ID:53706818 |
| TITLE:SQL语句如何进行优化? |
| ANSWER: 我觉得,把 t3.type_ = 2 这个条件,从on 里去掉,放到where后面,可能会比你目前要好 |
| LINK:https://ask.csdn.net/questions/7653998?answer=53706818 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654149 |
| ANSWER_ID:53706817 |
| TITLE:SQL条件判断筛选问题 |
| ANSWER: 加一个where条件 分析过程: 另外,这种代码麻烦不要贴截图,请直接使用代码块添加,你提问的时候,平台上是有提示的吧 |
| LINK:https://ask.csdn.net/questions/7654149?answer=53706817 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654152 |
| ANSWER_ID:53706815 |
| TITLE:请问HANA如何排除字段为空的行? |
| ANSWER: 你如果是希望排除某几个字段同时为空的数据,可以这么写条件 |
| LINK:https://ask.csdn.net/questions/7654152?answer=53706815 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654234 |
| ANSWER_ID:53706810 |
| TITLE:MySQL 千万级 分组怎么优化 |
| ANSWER: 建议写个定时任务,每天凌晨执行一次统计,将结果插入到一张汇总表,然后其他程序就查这张汇总表。 |
| LINK:https://ask.csdn.net/questions/7654234?answer=53706810 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654276 |
| ANSWER_ID:53706806 |
| TITLE:sqlserver2012无法执行KILL命令 |
| ANSWER: 无法在用户事务内部使用,那意思其实就是可以在用户事务外部使用。 |
| LINK:https://ask.csdn.net/questions/7654276?answer=53706806 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654317 |
| ANSWER_ID:53706803 |
| TITLE:oracle相关问题 |
| ANSWER: 在线的免费oracle环境大多数不提供本地直连,而且拒绝从数据库里连接到外网,因为oracle数据库里可以直接对操作系统进行各种侵入式操作,太危险了。 测数据库基本功能,可以尝试使用墨天轮提供的在线实训数据库,这个是提供了一个整个操作系统 有华为技术加持的墨天轮在线数据库在线实训平台实测_DarkAthena的博客-CSDN博客 背景最近各种折腾Oracle数据库,奈何自己电脑的资源有限,没办法搞多个版本的实例来测试。Oracle官方提供的云服务既要绑国际信用卡,而且国内连接网速太慢,测起来实在不爽。而且安装数据库也不是个很简单的事,要是国内能有数据库在线测试平台就好了。刚好墨天轮近期上线了在线实训平台,看上去还不错,正好拿来折腾折腾。当然折腾前,先要了解下这个平台,虽然我是很信任了,但还是要看看这个平台靠不靠谱,是不是网络陷阱(不是舍不得这1分钱哈)。平台介绍点击查看发布信息:墨天轮在线实训平台发布,领取开箱即用的数据库 https://darkathena.blog.csdn.net/article/details/121124888 另外,还有一些平台可以切换不同的数据库简单的跑跑sql,比如 |
| LINK:https://ask.csdn.net/questions/7654317?answer=53706803 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654323 |
| ANSWER_ID:53706798 |
| TITLE:使用python往mysql中传入数据编码出现问题 |
| ANSWER: 插入时,使用convert函数转换字符集 |
| LINK:https://ask.csdn.net/questions/7654323?answer=53706798 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654330 |
| ANSWER_ID:53706795 |
| TITLE:请大家帮我看下什么原因? |
| ANSWER: 建议你先直接用数据库管理工具连接mysql,直接执行一下这条sql,看看到底有没有数据。 |
| LINK:https://ask.csdn.net/questions/7654330?answer=53706795 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654339 |
| ANSWER_ID:53706794 |
| TITLE:odbc连接oracle数据库查询sql乱码 |
| ANSWER: userenv('language')这个是查的客户端的字符集。 【ORACLE】谈一谈Oracle数据库使用的字符集,不仅仅是乱码_DarkAthena的博客-CSDN博客 一、前言先看一个比较有意思的案例上面这个sql,查询了a和b两个字段,均为"张三"两个汉字,并且使用length函数检查,长度均为2。但是,当你看到下面这几个sql的输出结果时,很有可能第一反应是:"这特喵的怎么可能?"其实,你所看到的两个"张三",的确长得是一模一样,用显微镜去看也不可能看到区别。但为什么a和b不相等呢?这是因为组成他们的成分不一样,这个成分就是 字符集二、什么是字符集?百度百科简单来说,字符(Character)是各种文字和符号的总称,包括各国家文字、标 https://darkathena.blog.csdn.net/article/details/122659532 |
| LINK:https://ask.csdn.net/questions/7654339?answer=53706794 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654413 |
| ANSWER_ID:53706790 |
| TITLE:mysql删除某个表100条之后的数据 |
| ANSWER: 如果表里面有唯一标识符,比如id或者单号什么的, |
| LINK:https://ask.csdn.net/questions/7654413?answer=53706790 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654447 |
| ANSWER_ID:53706789 |
| TITLE:用正则替换字符串里括号里面所有内容 |
ANSWER:
原理,识别所有的以左括号开始中间任意个数字符然后以右括号结尾,然后替换成空 非得一个个符号解释么。。。 也就是说,这个正则表达式匹配的就是所有的括号及括号里的内容 |
| LINK:https://ask.csdn.net/questions/7654447?answer=53706789 |

| SOURCE:CSDN_ASK |
| ASK_ID:7654484 |
| ANSWER_ID:53706781 |
| TITLE:达梦数据库创建视图后插入数据显示视图为只读视图 |
| ANSWER: 当然啊,你这个视图里有两个表,不能直接插入的。 |
| LINK:https://ask.csdn.net/questions/7654484?answer=53706781 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654495 |
| ANSWER_ID:53706779 |
| TITLE:oracle与pg数据库差异 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7654495?answer=53706779 |
| SOURCE:CSDN_ASK |
| ASK_ID:7654568 |
| ANSWER_ID:53706778 |
| TITLE:请问大家 我想添加一个“入职时间”的字段 意思就是在每一个人后面填充进对应入职时间 应该怎么办啊 |
| ANSWER: "insert" 是指插入,数据库中对表数据的插入都是指插入一行。 |
| LINK:https://ask.csdn.net/questions/7654568?answer=53706778 |
| SOURCE:CSDN_ASK | ||||||||||
| ASK_ID:7654576 | ||||||||||
| ANSWER_ID:53706777 | ||||||||||
| TITLE:SQL 多行ID相同,但只有第一行有数值,把其他行空值填充第一行的值 | ||||||||||
| ANSWER: 先说下用什么数据库以及版本,并且提供一下你的表结构,因为不同数据库的写法是有区别的。
那么可以使用类似如下的sql 当然max不是唯一选择,sum也行,甚至还可以用first_value或者last_value排序取第一行或者最后一行。 | ||||||||||
| LINK:https://ask.csdn.net/questions/7654576?answer=53706777 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653892 |
| ANSWER_ID:53705592 |
| TITLE:SQL语句如何优化。 |
| ANSWER: 假设不改主体逻辑的话,可以把你这些or的条件改成in,这样代码会短不少。 |
| LINK:https://ask.csdn.net/questions/7653892?answer=53705592 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653821 |
| ANSWER_ID:53705571 |
| TITLE:请问怎么做怎么做做呀 |
| ANSWER: 首先,题目标题里麻烦对问题进行简要描述,你这题我差点就跳过去了, 这里我假设你是用的oracle自带的hr这个schema中employees表,
答案不是唯一的,就算使用开窗函数,这个题也可以写得五花八门 |
| LINK:https://ask.csdn.net/questions/7653821?answer=53705571 |

| SOURCE:CSDN_ASK |
| ASK_ID:7653817 |
| ANSWER_ID:53705550 |
| TITLE:MySQL 命令不了,特别好奇 |
| ANSWER: 这个其实就是停止服务,你可以去Windows的计算机管理里,找到对应的服务来关闭或者开启。 在cmd中net不是内部命令_weixin_33989780的博客-CSDN博客 阅读指南:在安装完mysql和配置完环境变量后,发现net命令不能使用。方案:我的电脑-->属性-->高级-->环境变量 path的变量值新加:%SystemRoot%\system32修改完成后,需要重新打开cmd命令行,否则不会生效的。转载于:https://www.cnblogs.com/zdb292034/p/8963811.html... https://blog.csdn.net/weixin_33989780/article/details/94443727 但是,如果之前path里还有别的,估计你得看看别人正常的电脑里还有些啥再对照着补回来了 |
| LINK:https://ask.csdn.net/questions/7653817?answer=53705550 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653709 |
| ANSWER_ID:53705472 |
| TITLE:mysql查询语句 select id from table where id in (1,2,3) 和id in (2,5,4)两个sql什么区别? |
| ANSWER: 这个我做个类比吧, 上面这个类比中,excel表格就相当于磁盘存储,光标就相当于磁盘的磁头,尽量让其要读取的数据是连续的,这样能减少一些不必要的性能开销 |
| LINK:https://ask.csdn.net/questions/7653709?answer=53705472 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653739 |
| ANSWER_ID:53705458 |
| TITLE:请教SQL自连接的实现? |
| ANSWER: 用开窗函数只需要查一次这个表,不知道为啥要用什么自连接 自连接无非就是同一个表写两个别名,然后join起来,但你这个是要找工资最少的,那么当然是min一下,但这个数据聚合后就不是同一个表了,所以换个思路, 即在b表中不存在比a表中还小的数据时, a表这一行就是最小。 |
| LINK:https://ask.csdn.net/questions/7653739?answer=53705458 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653657 |
| ANSWER_ID:53705373 |
| TITLE:sql中in database的使用? |
ANSWER:
一定要注意,千万不要把不同厂家的数据库混为一谈,有些数据库的database层级是其他数据库的schema层级,有些数据库schema和user是一个层级 |
| LINK:https://ask.csdn.net/questions/7653657?answer=53705373 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653617 |
| ANSWER_ID:53705362 |
| TITLE:hana数据库 sql版本号字段的问题 |
| ANSWER: 先分组排序,然后再筛选出每组中的第一行,最后求和。另外,排序的确会有问题,当你版本大于10以后,按字符串排序就不对了,所以要转换成数字再来排序 |
| LINK:https://ask.csdn.net/questions/7653617?answer=53705362 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653337 |
| ANSWER_ID:53705298 |
| TITLE:SQL SERVER 存储过程 多行数据不同的时间段进行合并,有什么便捷的实现方法吗? |
| ANSWER: 你想合并成什么样子? |
| LINK:https://ask.csdn.net/questions/7653337?answer=53705298 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653346 |
| ANSWER_ID:53705295 |
| TITLE:关于postgre \o 命令如何输出制表符或者其他特殊符号 |
| ANSWER: 看下这篇文章吧, 这篇文章示例中,\o的sql里面已经拼接好了分隔符 Postgresql将查询结果导出到文件中_shiyibodec的专栏-CSDN博客_postgresql 查询结果导出 1、写入文件命令:\o /mytemp/write.txt接下来执行query命令:select rs.* from (select distinct(phone_no || ',') from t_cw where phone_no like '1__________' and phone_no not like '17%') rs limit 10000 offset 170000;执行的结果将 https://blog.csdn.net/shiyibodec/article/details/53425093 在官方文档中\o的命令也没有分隔符参数
因此,如果要使用自定义分隔符的话,建议使用copy命令 |
| LINK:https://ask.csdn.net/questions/7653346?answer=53705295 |

| SOURCE:CSDN_ASK |
| ASK_ID:7653354 |
| ANSWER_ID:53705284 |
| TITLE:mysql关联模糊查询时,加入排序变得很慢 |
| ANSWER: 这样试试 |
| LINK:https://ask.csdn.net/questions/7653354?answer=53705284 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653151 |
| ANSWER_ID:53704834 |
| TITLE:上课用不了虚拟机怎么办 |
| ANSWER: 方法一:按下重启电脑后,狂点del,进入bios |
| LINK:https://ask.csdn.net/questions/7653151?answer=53704834 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652990 |
| ANSWER_ID:53704827 |
| TITLE:为什么通过sql查询生成的dataframe转换成列表和读取csv文件转换成列表的数据不一样呀(语言-python) |
| ANSWER: csv文本抛弃了字段类型,再读取的话是无法识别原字段类型的,这样有可能导致数据处理出问题。而df可以保留原字段类型 |
| LINK:https://ask.csdn.net/questions/7652990?answer=53704827 |
| SOURCE:CSDN_ASK |
| ASK_ID:7653095 |
| ANSWER_ID:53704825 |
| TITLE:关于plsql for循环和goto语句的使用 |
| ANSWER: 参考下面这个, 一般如非必要,不太建议使用goto,goto的大多数场景都可以用判断及循环来实现 |
| LINK:https://ask.csdn.net/questions/7653095?answer=53704825 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652642 |
| ANSWER_ID:53704390 |
| TITLE:egg-mysql怎么批量操作数据 |
| ANSWER: 一般这种工具都会提供自定义sql执行的,比如 |
| LINK:https://ask.csdn.net/questions/7652642?answer=53704390 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652377 |
| ANSWER_ID:53704274 |
| TITLE:关于本地navicat连接远程oracle报错 |
| ANSWER: 只要数据库服务起来了,那么数据库服务器本地就是可以连接数据的; 并且你需要确保监听文件配置是正确的 |
| LINK:https://ask.csdn.net/questions/7652377?answer=53704274 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652812 |
| ANSWER_ID:53704259 |
| TITLE:mysql不会建表 求解答 |
| ANSWER: 你在这个数据库里,输入下面这条命令回车,就可以查出建表的sql了 |
| LINK:https://ask.csdn.net/questions/7652812?answer=53704259 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652818 |
| ANSWER_ID:53704249 |
| TITLE:python往数据库里面插入一段js代码,提示错误,如何解决? |
| ANSWER: 这个要根据你插入是用的字符串拼接的方式还是用的绑定变量的方式来看, 因为sql中,单引号引起来的表示字符串,你直接拼含单引号的字符串时,会导致字符串被截断,因此需要使用两个单引号。 |
| LINK:https://ask.csdn.net/questions/7652818?answer=53704249 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652844 |
| ANSWER_ID:53704238 |
| TITLE:oracleA表时间是否在B表时间段里? |
| ANSWER: 这个问题看上去,是打算根据日计划汇总月计划,并且月份的日期分段由B表确定 |
| LINK:https://ask.csdn.net/questions/7652844?answer=53704238 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652766 |
| ANSWER_ID:53704227 |
| TITLE:excel进行查找时,只能显示被找到的单元格数,但我想查找某个数字总共出现几次,怎么解决 |
| ANSWER: 找个空单元格,输入 注意公式输入完后不要按回车,而是按 ctrl + shift +回车,即数组公式
用于在 Excel 中计算文本、字符和单词出现次数的公式 - Office | Microsoft Docs 提供示例以描述计算文本、字符和单词出现次数的公式。 https://docs.microsoft.com/zh-cn/office/troubleshoot/excel/formulas-to-count-occurrences-in-excel
|
| LINK:https://ask.csdn.net/questions/7652766?answer=53704227 |


| SOURCE:CSDN_ASK |
| ASK_ID:7652638 |
| ANSWER_ID:53704090 |
| TITLE:union all後数据来源哪张表 |
ANSWER:其实就是先查a表,放在查询结果的最上面,然后再查b表,把b表数据拼在刚刚查出来的a表数据的下面。 |
| LINK:https://ask.csdn.net/questions/7652638?answer=53704090 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652686 |
| ANSWER_ID:53704078 |
| TITLE:计算机网络几乎0基础 求一个懂ip知识的朋友回答下疑问 |
| ANSWER: 静态ip就是不会变的ip,与之相反的就是动态ip。 百度安全验证 https://baijiahao.baidu.com/s?id=1718565388970084956&wfr=spider&for=pc&searchword=%E5%8E%9F%E7%94%9Fip 独立IP就是这个IP不是共用的。 代理IP是有角度追踪来源的,但一般开发商不会去做,因为耗费成本过高。 查IP所在区域很简单,你打开百度首页,输入IP,点搜索,就会出现IP的归属地
|
| LINK:https://ask.csdn.net/questions/7652686?answer=53704078 |

| SOURCE:CSDN_ASK |
| ASK_ID:7652547 |
| ANSWER_ID:53703846 |
| TITLE:mysql查询近一年数据 有的月没有数据但是还是需要展示商品名 |
| ANSWER: 方案一,你这个数据库里应该还有个完整的商品信息表吧,你把那个商品信息表和你做的这个月份数据进行笛卡尔积join,即不使用任何条件,即可得到任意商品和任意月份的组合数据,这个时候再用这个数据去left join你的订单数据即可。但是这个缺点是,你商品表里可能有很多垃圾数据,即从未进行过任何交易的商品,这样最后你的数据里就会存在很多无用数据。所以,你还可以尝试用这个订单数据distinct商品出来替代前面说的这个完整商品信息表,但缺点就是查询效率变低了 方案二,如果是8.0以上,可以使用with递归,判断本行没有数据就用上一行的数据(商品名称),但你没写数据库版本,也没给建表和模拟数据的sql,我就不细说了,可以参考下面这个问答,只是"WITH cte_name AS" 要改成"WITH RECURSIVE cte_name AS",和其他数据库相比多了个"RECURSIVE" 用SQLServer 填充缺少日期的不同项目不同产品的每日结存-微软技术-CSDN问答 CSDN问答为您找到用SQLServer 填充缺少日期的不同项目不同产品的每日结存相关问题答案,如果想了解更多关于用SQLServer 填充缺少日期的不同项目不同产品的每日结存 sqlserver、数据库、有问必答 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7647825?answer=53697052 |
| LINK:https://ask.csdn.net/questions/7652547?answer=53703846 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652542 |
| ANSWER_ID:53703821 |
| TITLE:数据库连接池参数设置 |
| ANSWER: 连接一次数据库是需要消耗不少时间的,如果一开始就已经把连接建立好了,那么在使用过程中就不需要考虑连接数据库的时间消耗了。 |
| LINK:https://ask.csdn.net/questions/7652542?answer=53703821 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652221 |
| ANSWER_ID:53703746 |
| TITLE:怎么把格式化不了的U盘救活 |
| ANSWER: U盘修复工具哪个好?7款u盘低级格式化工具对比介绍-U盘修复教程-U盘量产网 U盘修复工具哪款好?u盘低级格式化工具真有万能的吗?很显然不是。现在的u盘越来越便宜了,使用的人也非常多,但是u盘也很容易损坏,很多朋友都喜欢使用u盘高级或低级格式化工 https://www.upantool.com/jiaocheng/xiufu/2014/5045.html |
| LINK:https://ask.csdn.net/questions/7652221?answer=53703746 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652254 |
| ANSWER_ID:53703733 |
| TITLE:在使用临时表的时候 无论是事务级的临时表还是会话级的临时表 ,插入数据后,新打开一个SQL调试窗口,查询该临时表,都是空的 |
| ANSWER: 一个会话里是可以有多个事务的,对于TEMPORARY TABLE而言,不同会话间的数据都是隔离的,
这个按钮来在调试会话中执行查询的 |
| LINK:https://ask.csdn.net/questions/7652254?answer=53703733 |

| SOURCE:CSDN_ASK |
| ASK_ID:7652482 |
| ANSWER_ID:53703705 |
| TITLE:oracle数据库中,表数据是日增的,字段有一个每日增加的产品代码,有可能重复,还有一个save_time 是 DATE类型 |
| ANSWER: 索引的建立,都是按使用场景来的,一般都是按执行sql中的where条件来创建,但是当你索引建得比较复杂的时候,那么插入速度就会受到影响,而且复杂索引的存储空间也会很大,所以,此时要看下查询时的限制,比如每次查询时有限定时间范围长度,那么可以尝试按时间建立范围分区,那么在查询的时候就不会扫到无关分区,而且插入的时候也能直接定位到分区。 |
| LINK:https://ask.csdn.net/questions/7652482?answer=53703705 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652289 |
| ANSWER_ID:53703681 |
| TITLE:关于#SQL#的问题,如何解决? |
| ANSWER: 我就觉得奇怪了,为什么别人的答案都是限定前6位再统计,那有个啥意义啊,这当然是截取前6位来group by 啊 |
| LINK:https://ask.csdn.net/questions/7652289?answer=53703681 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652097 |
| ANSWER_ID:53703190 |
| TITLE:oracle数据库if语句放for循环报错,求答疑和解决方案,如何解决? |
| ANSWER: 3个错误
改成下面这个样子就可以跑通了 |
| LINK:https://ask.csdn.net/questions/7652097?answer=53703190 |
| SOURCE:CSDN_ASK |
| ASK_ID:7652045 |
| ANSWER_ID:53703112 |
| TITLE:plsql编程,这个为什么会报错啊 |
| ANSWER: OPEN C_emp 这行命令没写结束符,后面少了个分号 。
|
| LINK:https://ask.csdn.net/questions/7652045?answer=53703112 |

| SOURCE:CSDN_ASK | ||||||||||||||||||||||||||
| ASK_ID:7652034 | ||||||||||||||||||||||||||
| ANSWER_ID:53703108 | ||||||||||||||||||||||||||
| TITLE:关于mysql执行顺序的一个问题 | ||||||||||||||||||||||||||
| ANSWER: 当然要先确定会查询到哪些行,之后才能根据这些行里的数据进行聚合(折叠) 如果你已经聚合了,就筛不掉了啊,比如有一列是1、2、3,根据where条件是 要取1和3,如果求和则得4,但是如果先聚合,求和就变成了6,这个时候你难道根据where条件再从6里面把2减掉么? 我这个例子你没看懂么?我再举一个例子:
按type分组,计算字段c中偶数的平均值,则sql为 得
但假设按你说的,先group by ,那么sql为 得
然后你拿着这两行数据,怎么用where把聚合前的奇数去掉,来获得和正确sql执行一样的结果?? 这个例子中,group by时, 如果不使用avg、sum、max、min等聚合函数对未group by 的字段进行处理,那么这些字段就会直接被舍弃了,group by 时产生了一个新的数据集,行数为group by 后面字段去重的个数,此时已经无法再对原数据进行任何过滤,因为当前阶段已经没有原数据了 因为group by 之后,数据就已经被折叠了,多行变成了一行。下面这两个sql是等效的: 当这个c表里面如果除了a和b以外还有其它字段,如果不聚合,其余字段的数据就会被舍弃,如果聚合,那么只会得到聚合后的结果,找不到聚合之前的数据了 | ||||||||||||||||||||||||||
| LINK:https://ask.csdn.net/questions/7652034?answer=53703108 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651916 |
| ANSWER_ID:53703105 |
| TITLE:mysql怎么计算分组的数量? |
| ANSWER: 楼上的方法需要再执行一次查询,这样有可能由于时间差,数据已经发生了改变,所以建议使用开窗函数 当然这要mysql8.0以上才支持 |
| LINK:https://ask.csdn.net/questions/7651916?answer=53703105 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651969 |
| ANSWER_ID:53703096 |
| TITLE:用SQL算出每块电表的用电量 |
| ANSWER: 请说明一下使用的是什么数据库,以及数据库的版本,还有你最终想得到的数据是长什么样子,有哪些字段。 但是有部分数据库是不支持开窗函数的。 另外,如果你是想聚合数据,按指定的时间点来进行分段统计,那么你需要说明一下每15分钟的第1分钟是从哪里开始 你这个格式的话,要说明一下每个字段打算怎么计算,明明输出的每个电表只有一行记录,哪里来的每小时?
|
| LINK:https://ask.csdn.net/questions/7651969?answer=53703096 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651982 |
| ANSWER_ID:53703077 |
| TITLE:怎么从一张表中剔除数据 |
| ANSWER: 如果只是查询,not in 或not exists 都行 如果是要删除A表中的数据,用in 或者exists 都行 |
| LINK:https://ask.csdn.net/questions/7651982?answer=53703077 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651931 |
| ANSWER_ID:53703070 |
| TITLE:oracle查询问题 |
| ANSWER: 如果只要提取满足条件的bh,那么可以使用下面这个sql,注意这个count(distinct )=2,也就是必须满足 权利人和义务人同时存在 如果是要在查询qlr表的时候,多一个字段显示是否满足要求,那么可以使用开窗函数 另外,我不确定你这个数据里,对于同一个BH是否会存在多个权利人或者多个义务人,如果有的话,你先得说明一下,如果存在一个权利人和一个义务人满足条件,但存在另一个权利人不满足条件,那么这个BH是否还满足条件? |
| LINK:https://ask.csdn.net/questions/7651931?answer=53703070 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651808 |
| ANSWER_ID:53702884 |
| TITLE:关于数据库的几个小问题 |
| ANSWER: 所有数据都是以二进制形式存储在存储介质上的,比如磁带、磁盘, 而数据库又分很多种类,你说的mysql,管理的拥有关系的多张表格,这个叫关系型数据库。早期这种数据是以纯文本形式存储,当时的关系型数据模型管理也只是编写了一些代码来对这些文本文件进行访问及处理, 关系型数据库问世前,是怎么做数据存储管理? - 知乎 如果有人问你,关系型数据库发展的历史,让他看这篇文章——关于关系型数据发展的简史。我们把关系型数据库问世前、诞生时的“爱恨情仇”都好好地梳理一遍,还原最直观的数据库历史,帮助大家更全面地了解关系型数… https://zhuanlan.zhihu.com/p/31549663 然后,你说的"本地数据库",这里需要纠正一下,一个操作系统的启动运行并不依赖数据库,而是软件在开发中,发现使用数据库更容易管理数据,才会在这个软件中添加数据库并添加数据库管理相关的内容,比如常见的有使用文本文件来保存数据或者用sqlite/access等小型单文件数据库,所以windows系统中是存在大量的数据库的,因为它自带的前后台软件极多。 "本地"是一个网络概念,相对的是"远程",某台电脑上装了个数据库,在这台电脑上它叫本地数据库,其他设备来访问这个数据库的时候,它就叫远程数据库了。 mysql安装时,你完全可以把它当成一个普通的软件,和qq微信一样,都是解压文件到你电脑上,然后改几个注册表键值,再新增一个自启动服务。 tips:excel是1985年开发的,第一个商用关系型数据库是1976年发布的。。。 |
| LINK:https://ask.csdn.net/questions/7651808?answer=53702884 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651778 |
| ANSWER_ID:53702821 |
| TITLE:DB2 load加载数据文件,最后几条没有加载进去 |
| ANSWER: 检查第1520条到1521条之间的分隔方式是否完全和前后保持一致 |
| LINK:https://ask.csdn.net/questions/7651778?answer=53702821 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651694 |
| ANSWER_ID:53702813 |
| TITLE:linux安装的oracle,可以使用sys用户登陆,但是用本地plsql连接linux上的oracle时,报ora-01031没有权限,请问该怎么解决? |
| ANSWER: 这个提示不是没有权限,而是这个视图查出来没有数据 |
| LINK:https://ask.csdn.net/questions/7651694?answer=53702813 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651645 |
| ANSWER_ID:53702626 |
| TITLE:同一款APP可以同时安装在PDA和智能手机上吗?有区别吗? |
| ANSWER: 我先假定你说的PDA和智能手机都是android系统(如果不是同一个系统就没有讨论意义了)。 |
| LINK:https://ask.csdn.net/questions/7651645?answer=53702626 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651624 |
| ANSWER_ID:53702554 |
| TITLE:请问一下,文件服务器的权限怎么设置 |
| ANSWER: 看你是用的什么东西搭建的文件服务器,不同的工具设置方式不一样 windows server 自带的文件服务器是可以设置权限的
把指定用户的写入及修改去掉,就不能删除文件了
Windows文件服务器搭建_张宇的博客-CSDN博客_文件服务器搭建 入门级文件服务器搭建过程一、事前二、准备三、开始搭建3.1、环境安装3.2、创建用户3.2.1、更改用户密码3.2.2、删除用户3.3、创建组3.3.1、添加用户进组3.3.2、将用户从组中删除3.3.3、用户转移到其它组3.4、创建共享文件夹3.5、设置文件夹权限3.5.1、整个文件夹设置为用户组权限,并拥有其子文件夹的所以权限,无需禁用继承一、事前在搭建之前,我们所要知道的几个问题。什么是文件服务器?文件服务器的功能?需要做到什么样的效果?知道这些问题之后,我们尝试回答一下这几个问题。 https://blog.csdn.net/weixin_42523454/article/details/119136593 |
| LINK:https://ask.csdn.net/questions/7651624?answer=53702554 |



| SOURCE:CSDN_ASK |
| ASK_ID:7651379 |
| ANSWER_ID:53702550 |
| TITLE:文件地址如何有效存储在数据库中 |
| ANSWER: 参考知名的私有云文件管理软件nextcloud(owncloud),它在数据库中的文件路径设置是用的递归
如果页面中只是要显示一个文件的这三个地址,我建议直接切字符串 |
| LINK:https://ask.csdn.net/questions/7651379?answer=53702550 |

| SOURCE:CSDN_ASK |
| ASK_ID:7651514 |
| ANSWER_ID:53702502 |
| TITLE:SQL Server 存储过程 多行结果 合并为一行数据,请问怎么实现呢? |
| ANSWER: 下面这段 改成 |
| LINK:https://ask.csdn.net/questions/7651514?answer=53702502 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651525 |
| ANSWER_ID:53702501 |
| TITLE:请问HeidiSQL导出MySQL表里的数字变成科学计数该怎么解决? |
| ANSWER: 其实吧,导出的数据应该并没有变成科学计数法,是你打开的excel进行了自动格式化显示,你可以用文本编辑工具,比如记事本,打开这个csv文件,看这个csv文件里面的内容到底长什么样子 |
| LINK:https://ask.csdn.net/questions/7651525?answer=53702501 |
| SOURCE:CSDN_ASK | ||||||||||||
| ASK_ID:7651581 | ||||||||||||
| ANSWER_ID:53702495 | ||||||||||||
| TITLE:mysql有俩个字段一个是记录状态的,另一个是记录状态录入时间的,怎么计算一个状态的持续时间 | ||||||||||||
ANSWER:
以上面这个数据为例,你是想得到 初始化的时间为 处理中的时刻减去初始化的时刻是吧? 至于计算持续时间,比较开始时刻和完成时刻这两个字段就行了,用timestampdiff这个函数 | ||||||||||||
| LINK:https://ask.csdn.net/questions/7651581?answer=53702495 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651470 |
| ANSWER_ID:53702483 |
| TITLE:MySQL优化方案对比 |
| ANSWER: 目前我没环境可以造这么大量的数据进行实机测试,而且综合评估的话还得看磁盘读取效率、内存速度等,所以我还是保留上一个问题中回答的观点,使用exists,因为它只要扫到任意一行满足条件的就会true,不会把所有记录都扫到 MySQL优化方案对比(酬谢一百起步)-大数据-CSDN问答 CSDN问答为您找到MySQL优化方案对比(酬谢一百起步)相关问题答案,如果想了解更多关于MySQL优化方案对比(酬谢一百起步) mysql、数据库、有问必答 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7650978?answer=53701943 |
| LINK:https://ask.csdn.net/questions/7651470?answer=53702483 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651333 |
| ANSWER_ID:53702080 |
| TITLE:SQL中TMP代表什么 |
| ANSWER: tmp本身没有任何含义,在你这个SQL里,tmp是你前面这个子查询的别名,可以理解为有张叫tmp的表,表里的数据为这个SQL的查询结果 当然,实际这张表是不存在的,只是为了方便引用而已,而且你把这个tmp改成别的名称也一样没问题,只是引用到的地方也得一起改 |
| LINK:https://ask.csdn.net/questions/7651333?answer=53702080 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651356 |
| ANSWER_ID:53702076 |
| TITLE:关于公司产量业务的问题 |
| ANSWER: 300万的存量提成=3000.105=31.5 这是小学数学题么? |
| LINK:https://ask.csdn.net/questions/7651356?answer=53702076 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651252 |
| ANSWER_ID:53701979 |
| TITLE:sql文exception中出现的raise是什么意思 |
| ANSWER: 你把原始代码贴一下看看,怕你精简这个代码不是原代码的本意 首先,应该有个地方声明了这个"A"作为exception, 然后后面要加日志,就写了个exception,其实这个时候的raise A已经和第一个raise A 不一样了。 exception里面如果不raise的话,程序不会向调用它的程序抛出错误,至于是raise A还是raise别的,不影响这段程序的运行逻辑。其实如果exception里不raise,你就可以当它是个类似if或者case when的判断逻辑,如果出现特定情况就执行特定的代码 |
| LINK:https://ask.csdn.net/questions/7651252?answer=53701979 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651260 |
| ANSWER_ID:53701975 |
| TITLE:oracle密码问题 |
| ANSWER: 请提供报错信息,报错信息里已经说了原因,这与你昨天是不是改了密码没有关系 |
| LINK:https://ask.csdn.net/questions/7651260?answer=53701975 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650882 |
| ANSWER_ID:53701959 |
| TITLE:db2数据库查询 如果某个字段的值为0时则显示上个月的数据 |
| ANSWER: db2支持开窗函数,可以使用lag来查上一行的记录 由于没有环境测试,而且你也没提供建表的sql,因此不确定DB2的开窗函数中是否允许使用聚合,如果不允许的话,请在外面再包一层,然后再用开窗函数 |
| LINK:https://ask.csdn.net/questions/7650882?answer=53701959 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650923 |
| ANSWER_ID:53701953 |
| TITLE:这一条sql 为什么会执行成功 SELECT *,COUNT(c_id) FROM Score GROUP BY c_id |
| ANSWER: 你查一下这个 如果里面不包含"ONLY_FULL_GROUP_BY",那么就不会报错,反之就会报错。 |
| LINK:https://ask.csdn.net/questions/7650923?answer=53701953 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650939 |
| ANSWER_ID:53701948 |
| TITLE:SQL如何根据某字段包含的数据主键(某主键,某主键)分组求和 |
| ANSWER: 说一下是什么数据库吧,指定分隔符的字符串转列在很多数据库都算是个比较麻烦的事,你指定了数据库后我再按你指定数据库的语法来写一下
|
| LINK:https://ask.csdn.net/questions/7650939?answer=53701948 |

| SOURCE:CSDN_ASK |
| ASK_ID:7650978 |
| ANSWER_ID:53701943 |
| TITLE:MySQL优化方案对比(酬谢一百起步) |
| ANSWER: 关于哪个好,是有不同的评价标准,比如代码简洁度、查询速度、占资源多少等。 当然,由于不清楚实机情况,数据库的执行计划不是绝对能按你想的去走,它会有一些自行处理的优化,所以无法100%判断哪个跑得更快。 |
| LINK:https://ask.csdn.net/questions/7650978?answer=53701943 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650997 |
| ANSWER_ID:53701927 |
| TITLE:mysql 计算'年-月'格式日期的月份差 |
| ANSWER: 用concat补全字符串就行了
|
| LINK:https://ask.csdn.net/questions/7650997?answer=53701927 |

| SOURCE:CSDN_ASK |
| ASK_ID:7650999 |
| ANSWER_ID:53701905 |
| TITLE:数据分析的学习路径是什么? |
| ANSWER: 想具备数据分析能力的话,不是先学技术,而是应该先去了解有些什么东西可以分析,需求方希望得到一个什么样的分析结果,换句话说,就是先定目标,不知道目标长啥样子的话,可以先多看看别人写的分析报告。 |
| LINK:https://ask.csdn.net/questions/7650999?answer=53701905 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651040 |
| ANSWER_ID:53701888 |
| TITLE:如何用达梦语句实现MySQL数据库中的group by效果 |
| ANSWER: 你这个语法不符合sql标准,MYSQL8.0默认都不支持你这个写法了。 |
| LINK:https://ask.csdn.net/questions/7651040?answer=53701888 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651145 |
| ANSWER_ID:53701881 |
| TITLE:ERROR: index row requires 8856 bytes, maximum size is 8191 |
| ANSWER: 索引是有最大大小的,目前PG的限制为8191,但你这个数据的索引大小达到了8856,超过了PG的限制,当然报错了。一般超过这个值,说明是索引设计或者表设计存在问题,建议进行一下优化,比如减少索引的字段,或者检查数据是否有异常,比如某个索引字段超长。一般是用较短数据的字段作为索引的,那种长的字段应该做全文检索,而不是建普通索引。 |
| LINK:https://ask.csdn.net/questions/7651145?answer=53701881 |
| SOURCE:CSDN_ASK |
| ASK_ID:7651155 |
| ANSWER_ID:53701871 |
| TITLE:Excel数据导入数据库错误 |
| ANSWER: 你在插表的时候,指定了两个变量,但是parames却是一个元素个数大于2的列表,当然插不进去了,而且你上面的循环,把EXCEL里所有行和所有列的值全部都放到一个一维列表里去了,也就是一行记录,这样哪里还能区分哪个值放第一个字段哪个值放第二个字段呢? |
| LINK:https://ask.csdn.net/questions/7651155?answer=53701871 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650802 |
| ANSWER_ID:53701351 |
| TITLE:Postgresql如何用游标查出所有表的大小和条数,然后插入某张表? |
| ANSWER: 查pg_class,速度更快,只是里面的数据是定时刷新。 给你一个官方提供的循环并执行了动态sql的例子吧,你只要把游标sql改了,把动态sql改成拼insert语句就行了 中文官方文档地址 |
| LINK:https://ask.csdn.net/questions/7650802?answer=53701351 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650847 |
| ANSWER_ID:53701340 |
| TITLE:查询Score表中除了每门课程最高分的学生编号和课程编号 |
| ANSWER: 用开窗函数做分组排行,再把第一名剔除就是 如果不用开窗函数的话,那就得先写个子查询,得到每个课程的最高分,即课程和分数两个字段,然后再从原表里把对应的课程和分数进行剔除,可以用not in 也可以用not exists ,但这样相当于一张表要查两次,明显不如开窗函数来得优雅 |
| LINK:https://ask.csdn.net/questions/7650847?answer=53701340 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650588 |
| ANSWER_ID:53700846 |
| TITLE:有没有查询MySQL数据库关键字的方法 |
| ANSWER: |
| LINK:https://ask.csdn.net/questions/7650588?answer=53700846 |
| SOURCE:CSDN_ASK | |||||||||||||||||||||||||||||||
| ASK_ID:7650500 | |||||||||||||||||||||||||||||||
| ANSWER_ID:53700739 | |||||||||||||||||||||||||||||||
| TITLE:分别取两张表的两个字段的所有值 | |||||||||||||||||||||||||||||||
| ANSWER: 先不说有没有关联字段,重点是,你的查询结果想显示什么样的数据?如果两个数据不做任何关联,直接join,那么你查询出来的结果条目数为两张表条目数的乘积,即对于A表中的任意行匹配B表中的所有行。比如下面这样 A表
B表
查询结果
另外一种情况是,按照行号进行匹配,即A表中第一行匹配B表中第一行,A表中第二行匹配B表中第二行,以此类推,这个时候只需要在两个数据中分别加上行号字段即可,用行号做为条件来进行join。但是A表和B表的总行数可能不一致,那么就需要说清楚是仅展示能匹配上的行?还是A表记录为准?还是以B表记录为准?sql如下,根据不同的需要,full可以改成left或者right 如果C表只是要建表结构,不要数据的话,倒是问题不大 但既然这样的话,为什么不直接指定字段类型和字段名称来建表呢? | |||||||||||||||||||||||||||||||
| LINK:https://ask.csdn.net/questions/7650500?answer=53700739 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650394 |
| ANSWER_ID:53700696 |
| TITLE:怎样快速熟练运用存储过程 |
| ANSWER: 我也没师傅教,自己多看,多分析,然后多练。 |
| LINK:https://ask.csdn.net/questions/7650394?answer=53700696 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650475 |
| ANSWER_ID:53700690 |
| TITLE:ValueError: list.remove(x): x not in list报错 |
| ANSWER: 因为你没有准确的写什么时候退出循环,然后它就一直在那删,当列表里没有这个元素的时候你还去删,它就会报错 |
| LINK:https://ask.csdn.net/questions/7650475?answer=53700690 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650463 |
| ANSWER_ID:53700683 |
| TITLE:想问问stata合并了缺失项之后怎么删除那个点 |
| ANSWER: 咋最近有人开始问stata的了,这玩意不算数据库,顶多只能算一个数据分析工具,加载到里面的数据不能sql语言进行查询,在这里应该很少有人知道的。 stata中两列数据如何合并相互补齐呢?-大数据-CSDN问答 CSDN问答为您找到stata中两列数据如何合并相互补齐呢?相关问题答案,如果想了解更多关于stata中两列数据如何合并相互补齐呢? database、sql、有问必答 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7648406?answer=53697734 |
| LINK:https://ask.csdn.net/questions/7650463?answer=53700683 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650288 |
| ANSWER_ID:53700570 |
| TITLE:CASE WHEN 里面嵌套了一个CASE WHEN 给我报缺少关键字 |
| ANSWER: 这个提问的提示里,说了 ** "问题相关代码,请勿粘贴截图"** 然后,为什么要用嵌套?case when 不是你这么用的,从你这个sql看不出你想实现什么效果,只能看出最后要么是money要么是0, 而且case when 也可以 when 多次 ``` |
| LINK:https://ask.csdn.net/questions/7650288?answer=53700570 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650217 |
| ANSWER_ID:53700501 |
| TITLE:Oracle密码过期处理(ORA-28002),如何处理? |
| ANSWER: 修改密码,或者改成密码永不过期 注意密码不过期的策略是按PROFILE 来的,一个PROFILE 可以给多个用户使用,因此同一个PROFILE下的用户拥有相同的规则 |
| LINK:https://ask.csdn.net/questions/7650217?answer=53700501 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650150 |
| ANSWER_ID:53700339 |
| TITLE:VMware虚拟机设置里面使用ISO映像文件为啥是灰色的? |
| ANSWER: 虚拟机要关机后,才能修改虚拟机设置 |
| LINK:https://ask.csdn.net/questions/7650150?answer=53700339 |
| SOURCE:CSDN_ASK |
| ASK_ID:7650020 |
| ANSWER_ID:53700190 |
| TITLE:想问问如何创建递增的数值列,并且位数固定为6位 |
| ANSWER: 在原来的基础上限制字段长度为6位。 |
| LINK:https://ask.csdn.net/questions/7650020?answer=53700190 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649908 |
| ANSWER_ID:53700144 |
| TITLE:有没有懂ftp上传的,请教个问题 |
| ANSWER: 你问的这个问题与FTP本身没有任何关系啊,你这只是要根据数据库里数据的情况来确定是否要执行某一条命令而已,而且客户端上传还必须用你的程序,不能直接用FTP传,因为FTP本身是不支持你说的这个逻辑的。 Java 实现ftp文件上传 - 简书 在JAVA程序中,经常需要和FTP打交道,比如向FTP服务器上传文件、下载文件,本文详细介绍如何利用FTPClient(在commons-net包中)图片的上传和HTTP请求... https://www.jianshu.com/p/44d9b05691a8 |
| LINK:https://ask.csdn.net/questions/7649908?answer=53700144 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649977 |
| ANSWER_ID:53700138 |
| TITLE:vmware虚拟机安装macos出现问题 |
| ANSWER: 第一张图显示,虚拟机硬盘里没有文件,CD-ROM里面没有可以启动的东西, 全网最详细的VMware虚拟机安装MacOS系统教程,没有之一!!!附全部资源 - 知乎 一、准备工作 1.安装环境: 2.所需工具: 3.资源下载: 二、安装教程 三、优化 昨天给大家分享了VMware的安装教程,今天就给大家分享使用VMware安装MacOS系统的详细教程。 大部分Windows用户都想体验一下简洁易用… https://zhuanlan.zhihu.com/p/337036027 |
| LINK:https://ask.csdn.net/questions/7649977?answer=53700138 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649937 |
| ANSWER_ID:53700137 |
| TITLE:mysql的一个问题 |
| ANSWER: 这个玩意是动态变化的,建议两个一起查,你分两次查,数据已经不一样了 |
| LINK:https://ask.csdn.net/questions/7649937?answer=53700137 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649931 |
| ANSWER_ID:53700132 |
| TITLE:关于mysql的一个问题 |
| ANSWER: 后面的排序改成 我有点怀疑你是写成了下面这个样子,导致没有排序 能不能上个实际运行的截图看看? |
| LINK:https://ask.csdn.net/questions/7649931?answer=53700132 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649969 |
| ANSWER_ID:53700125 |
| TITLE:SQL中DESC代表什么 |
| ANSWER: 我补充一下,你这个语法在mysql 8.0开始已经不支持了,如果要排序,必须使用order by MySQL解惑——GROUP BY隐式排序 - 潇湘隐者 - 博客园 MySQL中GROUP BY隐式排序是什么概念呢? 主要是其它RDBMS没有这样的概念,如果没有认真了解过概念,对这个概念会感觉有点困惑,我们先来看看官方文档的介绍: 官方文档MySQL 5.7 Re https://www.cnblogs.com/kerrycode/p/11836647.html |
| LINK:https://ask.csdn.net/questions/7649969?answer=53700125 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649873 |
| ANSWER_ID:53699985 |
| TITLE:crontab执行hbase shell命令输出列数改变 |
| ANSWER: 输出日志的shell里,前面加上行宽设置 crontab用的是内部终端,默认行宽大小和你手动在当前终端下执行的当然不一样。 |
| LINK:https://ask.csdn.net/questions/7649873?answer=53699985 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649795 |
| ANSWER_ID:53699903 |
| TITLE:postgres数据库有没有all_source表 |
| ANSWER: 查 pg_proc 这个表 |
| LINK:https://ask.csdn.net/questions/7649795?answer=53699903 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649716 |
| ANSWER_ID:53699824 |
| TITLE:SQL SERVER 存储过程 查询出来的数据为一行合计 不需要进行分组,如何进行调整。 |
| ANSWER: 把最下面那段select改成这样 |
| LINK:https://ask.csdn.net/questions/7649716?answer=53699824 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649593 |
| ANSWER_ID:53699663 |
| TITLE:oracle登录了下不了jdk,网页打不开怎么办 |
| ANSWER:
|
| LINK:https://ask.csdn.net/questions/7649593?answer=53699663 |

| SOURCE:CSDN_ASK |
| ASK_ID:7649604 |
| ANSWER_ID:53699645 |
| TITLE:关于#sql#的问题,如何解决? |
| ANSWER: 这就一个自关联笛卡尔积的灵活运用
|
| LINK:https://ask.csdn.net/questions/7649604?answer=53699645 |

| SOURCE:CSDN_ASK |
| ASK_ID:7649388 |
| ANSWER_ID:53699342 |
| TITLE:数据库时间条件查询问题 |
ANSWER:
第一个sql,是把一个datetime类型的数据转换成varchar(100)的类型,因此可以使用字符串进行匹配,单引号引起来的就是字符串,"CONVERT(varchar(100), CreateTime, 23) "这个函数的用法是sqlserver独有的。 第二个sql,你没说这个create_time是什么类型,但是右边的 '2022-01-13%'肯定是个字符串类型,此时mysql会对左边的字段进行隐式转换,也变成一个字符串,因此可以用like来进行匹配 |
| LINK:https://ask.csdn.net/questions/7649388?answer=53699342 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649350 |
| ANSWER_ID:53699322 |
| TITLE:SQL Sever如何在计算结果中增加一定百分比的损耗值,比如求和结果理论用量为10,需要加百分之十五的损耗率,就是用11.5 |
| ANSWER: 你这个sql里面其实已经有类似的写法了 |
| LINK:https://ask.csdn.net/questions/7649350?answer=53699322 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649282 |
| ANSWER_ID:53699292 |
| TITLE:怎么根据B表字典,替换A表多列单元格中的内容? |
| ANSWER: 列数不确定,列名不确定,这个问题有意思,直接上sql
无论你有多少列,哪怕有几百个列,而且列名没有任何规则,用这个sql都可以把你数据给转换了,不需要在excel表里对每一个列都单独写公式,因为这个sql里面没有指定任何列名,全是动态获取 |
| LINK:https://ask.csdn.net/questions/7649282?answer=53699292 |

| SOURCE:CSDN_ASK |
| ASK_ID:7649150 |
| ANSWER_ID:53699118 |
| TITLE:关于#数据库#的问题,请各位专家解答! |
| ANSWER: 把你plsql里首选项设置里的Unicode选项勾上,然后重启plsql再试。 |
| LINK:https://ask.csdn.net/questions/7649150?answer=53699118 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649103 |
| ANSWER_ID:53698802 |
| TITLE:怎样通过sql,将A列和B列作为判断,A列为空时,将B列的数据转换到A列显示,如果B列的数据为空,还是保持原样,这个sql要怎么写? |
| ANSWER: 是什么数据库?不同数据库空值函数不一样,oracle是nvl,mysql是ifnull,另外还有个通用的coalesce函数。 |
| LINK:https://ask.csdn.net/questions/7649103?answer=53698802 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649089 |
| ANSWER_ID:53698798 |
| TITLE:mysql连接一段时间不使用后连接卡顿失效 |
| ANSWER: 你的wait_timeout设置为600,意思就是断开超过10分钟sleep的连接。 |
| LINK:https://ask.csdn.net/questions/7649089?answer=53698798 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649068 |
| ANSWER_ID:53698786 |
| TITLE:python读取mysql中的数据,里面有转义字符,反斜杠又会被转义该如何处理 |
| ANSWER: 替换字符串,把两个反斜杠替换成一个反斜杠 |
| LINK:https://ask.csdn.net/questions/7649068?answer=53698786 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649045 |
| ANSWER_ID:53698769 |
| TITLE:又报错了,ERROR 1064 (42000)呜 |
| ANSWER: 语法错误,你的else后面没有指定值,当然会报错,下面几种写法都不会报错 |
| LINK:https://ask.csdn.net/questions/7649045?answer=53698769 |
| SOURCE:CSDN_ASK |
| ASK_ID:7649012 |
| ANSWER_ID:53698765 |
| TITLE:PgSql 提示42P01错误!试了很多方法还是报错 |
| ANSWER: 这个其实就是告诉你"dwb_gov_office_item_list_min“这张表不存在,在你上面的数据库截图里面的确也没看到这张表(可能在下面没截到?) |
| LINK:https://ask.csdn.net/questions/7649012?answer=53698765 |
| SOURCE:CSDN_ASK |
| ASK_ID:7648976 |
| ANSWER_ID:53698716 |
| TITLE:MySQL会话第一次执行此SQL时抛出“子查询返回多行结果”的异常,如何解决? |
ANSWER:先查一下在这个表里面是否存在一个id对应多个pid的情况。 按照你这个表结构,我模拟了4条数据,然后用你这个sql怎么查都不会出现你这个报错,因此怀疑是你表里面的数据有问题,
|
| LINK:https://ask.csdn.net/questions/7648976?answer=53698716 |

| SOURCE:CSDN_ASK |
| ASK_ID:7648791 |
| ANSWER_ID:53698654 |
| TITLE:关于#sql#的问题,写一个SQL查询,找出每个部门获得前三高工资的所有员工占前三工资总和的比列 |
| ANSWER: 到底是oracle还是hive?两个数据库的函数有区别的
问sql题麻烦用create table 和insert或者with语句把原始数据贴出来,方便回答的人调试,造数据很浪费时间的 |
| LINK:https://ask.csdn.net/questions/7648791?answer=53698654 |

| SOURCE:CSDN_ASK |
| ASK_ID:7648842 |
| ANSWER_ID:53698638 |
| TITLE:oracle分组查询一段天数内每天18点到第二天8点的数据 |
| ANSWER: 首先,你这个问题有点奇怪,每天18点到第二天8点,这才14个小时,另外还有10小时的数据是不要进行统计么?(假设不统计) 假设你的日期和时间是在time 这个字段里,并且如题已经限制了天数范围,由于你只统计14个小时,另外10个小时没有在查询条件里剔除,那么只能在select 的时候用case when 来处理了,比如
(之前的sql有点小问题,已修正) 上面查的这个字段可以让你的数据得到可以用于聚合的日期字段,你按这个日期group by 就行了,这个字段为空的就是你不要的那10个小时,要去掉。 另外,如非必要,在查询条件里尽量不要对字段进行格式化,因为格式化字段会导致查询不走索引以及分区。 |
| LINK:https://ask.csdn.net/questions/7648842?answer=53698638 |

| SOURCE:CSDN_ASK |
| ASK_ID:7648714 |
| ANSWER_ID:53698443 |
| TITLE:db2数据库如何优化视图的查询效率 |
| ANSWER: 对推荐人计算积分,那么where条件应该是推荐人id,索引也应该是这个id,因此用于计算积分的case when字段与索引没有关系 ,积分字段是不应该有索引的; |
| LINK:https://ask.csdn.net/questions/7648714?answer=53698443 |
| SOURCE:CSDN_ASK |
| ASK_ID:7648761 |
| ANSWER_ID:53698393 |
| TITLE:从MySQL的某个表中随机取出几条数据的语句是什么啊? |
| ANSWER: 你说的不好用是什么意思?是查询报错还是每次查都是一样的? 实测该sql没有问题,连着查几次,每次结果都不一样。
|
| LINK:https://ask.csdn.net/questions/7648761?answer=53698393 |


| SOURCE:CSDN_ASK |
| ASK_ID:7648725 |
| ANSWER_ID:53698372 |
| TITLE:sqlserver数据库查询问题 |
ANSWER:
上面这个sql已经考虑到数据里存在分组的情况了,sql不用改
话说你自己就没去试一下么? |
| LINK:https://ask.csdn.net/questions/7648725?answer=53698372 |


| SOURCE:CSDN_ASK |
| ASK_ID:7648742 |
| ANSWER_ID:53698338 |
| TITLE:SQL:怎么计算一个表中的和并插入到另一个表中 |
| ANSWER: 对已经存在的行的部分字段进行修改,这个叫更新,不叫插入。 或者用plsql游标循环 |
| LINK:https://ask.csdn.net/questions/7648742?answer=53698338 |
| SOURCE:CSDN_ASK |
| ASK_ID:7648625 |
| ANSWER_ID:53698159 |
| TITLE:如何用oracle查询最近的一天数据。 |
ANSWER:如果这个字段是日期类型,肯定没问题,你说不行,那肯定是有条件没说明。 |
| LINK:https://ask.csdn.net/questions/7648625?answer=53698159 |

| SOURCE:CSDN_ASK |
| ASK_ID:7648170 |
| ANSWER_ID:53697448 |
| TITLE:oracle数据库,时间计算的sql问题 |
| ANSWER: 请提供create table和insert 命令,并以表格形式举例说明你想达到的效果 |
| LINK:https://ask.csdn.net/questions/7648170?answer=53697448 |
| SOURCE:CSDN_ASK |
| ASK_ID:7648147 |
| ANSWER_ID:53697441 |
| TITLE:ORA-04091: 表发生了变化, 触发器/函数不能读它 |
| ANSWER: 建议把代码贴出来看看 你读A表会读本次操作以外的行么? |
| LINK:https://ask.csdn.net/questions/7648147?answer=53697441 |
| SOURCE:CSDN_ASK |
| ASK_ID:7648055 |
| ANSWER_ID:53697430 |
| TITLE:MYSQL嵌套排序,先排序筛选最新数据,再将这个列表自定义排序 |
| ANSWER: 建议举个例子,从目前的题目上来看没有任何难点 |
| LINK:https://ask.csdn.net/questions/7648055?answer=53697430 |
| SOURCE:CSDN_ASK |
| ASK_ID:7648018 |
| ANSWER_ID:53697190 |
| TITLE:Oracle数据库表中的null 和空值' ',数据库是否可以配置成只要是空值自动写入null这种解决办法? |
| ANSWER: 首先,ORACLE 中的空字符串''和null是一样的, 上面这两条sql插入后没有任何区别。 然后,你具体是遇到了什么问题?无论是''还是null,本来就都不能作为关联条件,因为空不等于任何,空也不等于空,只能用is null 或者is not null。 |
| LINK:https://ask.csdn.net/questions/7648018?answer=53697190 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647825 |
| ANSWER_ID:53697052 |
| TITLE:用SQLServer 填充缺少日期的不同项目不同产品的每日结存 |
| ANSWER: 用with递归可以实现
sqlserver的递归sql里不能使用外关联,否则也不需要用子查询来来获取上一行了 |
| LINK:https://ask.csdn.net/questions/7647825?answer=53697052 |

| SOURCE:CSDN_ASK |
| ASK_ID:7647962 |
| ANSWER_ID:53696986 |
| TITLE:plsql插入数据问题 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7647962?answer=53696986 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647718 |
| ANSWER_ID:53696523 |
| TITLE:数据库连接断开重连,是会创建新的链接吗? |
| ANSWER: 直连数据库的情况下,断开后重连肯定是要重新输入用户名密码登录的,当然会创建新的连接。 |
| LINK:https://ask.csdn.net/questions/7647718?answer=53696523 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647459 |
| ANSWER_ID:53696481 |
| TITLE:informix数据库怎么将一行数据拆分成多行 |
| ANSWER: 用regexp_split函数,第一个参数是原字符串,第二个参数是分隔符 |
| LINK:https://ask.csdn.net/questions/7647459?answer=53696481 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647668 |
| ANSWER_ID:53696475 |
| TITLE:数据库可以增加修改,无法查询 |
| ANSWER: |
| LINK:https://ask.csdn.net/questions/7647668?answer=53696475 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647608 |
| ANSWER_ID:53696446 |
| TITLE:MySQL多表查询问题 |
| ANSWER: 这个用开窗函数分组排序就好了呀 |
| LINK:https://ask.csdn.net/questions/7647608?answer=53696446 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647512 |
| ANSWER_ID:53696228 |
| TITLE:plsql导出表数据为CSV或者xlsx格式表格,但是速度特别慢,这种应该怎么提高速度呢?(数据量比较大)数据量大概有个几百万行,大概有个30G |
| ANSWER: plsql developer不适合导出大量数据,建议使用sqluldr2,这个应该是除了自带dmp以外最快的导出方式了 |
| LINK:https://ask.csdn.net/questions/7647512?answer=53696228 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647496 |
| ANSWER_ID:53696216 |
| TITLE:sql如何将字符串替换成不同的字符? |
| ANSWER: 如果是日期类型,直接用date_format格式化成字符串就好了
如果本来就是字符类型,那么可以先转成日期类型再用上面这个方式。 或者用最笨的方法 |
| LINK:https://ask.csdn.net/questions/7647496?answer=53696216 |

| SOURCE:CSDN_ASK |
| ASK_ID:7647495 |
| ANSWER_ID:53696204 |
| TITLE:数据库手动sql修改完数据,java代码查询数据是修改前的 |
| ANSWER: 你在数据库里改了后,有没有执行commit?
左边这个按钮是提交commit,右边这个是回滚rollback |
| LINK:https://ask.csdn.net/questions/7647495?answer=53696204 |

| SOURCE:CSDN_ASK |
| ASK_ID:7647309 |
| ANSWER_ID:53696156 |
| TITLE:Clikhouse数据库如何根据String类型字段的首字母排序 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7647309?answer=53696156 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647043 |
| ANSWER_ID:53695548 |
| TITLE:查出数据库表中字段1或字段2中能够匹配到关键字key的数据,想优先显示字段1中匹配的数据 |
| ANSWER: 问题有点模糊,先确认几个点。
我先猜一下,给个sql 条件没有用concat的原因是,因为不清楚你数据长啥样,怕字段1的后半截和字段2的前半截组合后刚好和key相似,因此分别写条件。而展示的数据,case when 完美的诠释了优先级的用法 |
| LINK:https://ask.csdn.net/questions/7647043?answer=53695548 |
| SOURCE:CSDN_ASK |
| ASK_ID:7647020 |
| ANSWER_ID:53695461 |
| TITLE:SQL 如何去除不同列不同行的重复数据 |
| ANSWER: 请举个例子,原始数据是什么样子,以及 你想处理成什么样子 |
| LINK:https://ask.csdn.net/questions/7647020?answer=53695461 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646931 |
| ANSWER_ID:53695355 |
| TITLE:java拼接有null的查询条件要怎么办呢? |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7646931?answer=53695355 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646929 |
| ANSWER_ID:53695350 |
| TITLE:SqlServer里面null可以用update修改成某个值吗 |
| ANSWER: 没有 "= null" 这种写法,等号要求左右两边必须有数据(二进制数据),存在至少一侧为空它就false了。 |
| LINK:https://ask.csdn.net/questions/7646929?answer=53695350 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646901 |
| ANSWER_ID:53695338 |
| TITLE:关于#mysql#的问题,如何解决? |
| ANSWER: 你这平均数是个位数不确定的浮点,浮点是不精确的,而等号则要求完全相等, |
| LINK:https://ask.csdn.net/questions/7646901?answer=53695338 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646876 |
| ANSWER_ID:53695182 |
| TITLE:oracle 语句求全注释 |
| ANSWER: 目的是更新C_NE 这张表, 然后,对这部分数据,更新a.zassu_gra 这个字段,更新成(select zlevel from temp_zzz b where a.product_no = b.xinid) 这个值,如果想在更新前看这个数据的话,你可以这么查一下 所以,实际上你这个更新的效果,就是把上面这个sql的新值更新到旧制对应的字段上去 |
| LINK:https://ask.csdn.net/questions/7646876?answer=53695182 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646733 |
| ANSWER_ID:53695157 |
| TITLE:无论是outlook 还是excel 还是word在录入单词的时候 词中字母录入时 会出现混乱大小写得情况 |
| ANSWER: 向日葵远程连接电脑大小写键冲突_Fanor_的博客-CSDN博客 向日葵远程连接电脑大小写键冲突解决思路步骤1.系统输入“高级键盘设置”。2. 选择“语言栏选项”。3. 选择“高级键设置”,选择“按SHIFT”键切换大小写。解决思路临时改变大小写键切换的按键步骤1.系统输入“高级键盘设置”。2. 选择“语言栏选项”。3. 选择“高级键设置”,选择“按SHIFT”键切换大小写。... https://blog.csdn.net/Fanor_/article/details/120586124 |
| LINK:https://ask.csdn.net/questions/7646733?answer=53695157 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646743 |
| ANSWER_ID:53695142 |
| TITLE:mysql怎么查询两个时间段分别最近的一条数据 |
| ANSWER: 分两次查,伪代码 |
| LINK:https://ask.csdn.net/questions/7646743?answer=53695142 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646716 |
| ANSWER_ID:53694949 |
| TITLE:用proxifier连接公司内网,navicat中可以连接到oracle,但是本地启动项目却始终尝试连线失败 |
| ANSWER: 换下新版的jdbc试试 |
| LINK:https://ask.csdn.net/questions/7646716?answer=53694949 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646598 |
| ANSWER_ID:53694628 |
| TITLE:想问下大伙遇到过sql语句更新成功但没改变数据库吗 |
| ANSWER: 你的查询条件和更新后的值都是同一个 params.title ,如果你想要修改title,那么传入的参数应该要有两个不同的title,一个老的一个新的, |
| LINK:https://ask.csdn.net/questions/7646598?answer=53694628 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646528 |
| ANSWER_ID:53694624 |
| TITLE:interval day to second 可以取底,为什么不能取顶 |
| ANSWER: 你用的是啥数据库?
|
| LINK:https://ask.csdn.net/questions/7646528?answer=53694624 |

| SOURCE:CSDN_ASK |
| ASK_ID:7646506 |
| ANSWER_ID:53694622 |
| TITLE:navicat导入数据 |
| ANSWER: B库里面的表有数据,而且A库里同一张表也有数据?假设主键冲突,是保留B的数据还是用A的数据覆盖?如果有外键约束或者规则约束之类的,这些数据也可能会有冲突。在存在多种复杂场景的情况下,这根本不是任何一个工具能做到的事情,主要还是看数据保留规则怎么制定,不同表的规则根据业务情况可能还不一样。 |
| LINK:https://ask.csdn.net/questions/7646506?answer=53694622 |
| SOURCE:CSDN_ASK |
| ASK_ID:7646432 |
| ANSWER_ID:53694604 |
| TITLE:HiveSQL行列转换题 |
ANSWER:
添加一个辅助列id,主要为了确定行的顺序,要不然无法知道哪行是第一行,哪行是第二行 |
| LINK:https://ask.csdn.net/questions/7646432?answer=53694604 |

| SOURCE:CSDN_ASK |
| ASK_ID:7646396 |
| ANSWER_ID:53694518 |
| TITLE:利用#开窗函数#的问题,如何解决?#面试题# |
| ANSWER: 你的月累计和年累计的确是用开窗函数没问题,用order by 或者滑动窗口都行。 开窗函数不能增加不存在的记录,所以只能先构建一个不存在的记录了,不用递归sql大概长这样 之所以没用PERIOD_MONTH这个字段,是怕数据里有跨年的,光这个月份字段无法进行准确分组,因此从日期里重新截取年月和年 如果sqlserver不支持这种窗口,那么可以使用移动窗口,从第一行到当前行 , 关于递归的话,我举个类似的例子吧
假设dt是日期,可以看到原始数据不连续,但通过cte中的递归,实现了数据的补齐,并且还可以同时把累加一起做了,而且,最后的数据行数可能还会比笛卡尔积的要少,因为这个对于每个产品只会从有销售的第一天开始统计,避免了很多无效数据 |
| LINK:https://ask.csdn.net/questions/7646396?answer=53694518 |

| SOURCE:CSDN_ASK |
| ASK_ID:7646223 |
| ANSWER_ID:53694510 |
| TITLE:MySQL如何建立大量字段的表 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7646223?answer=53694510 |

| SOURCE:CSDN_ASK |
| ASK_ID:7646298 |
| ANSWER_ID:53694387 |
| TITLE:mysql全表更新加where和不加where效率有区别吗? |
| ANSWER: 大多数情况下,加where更快,这与你是不是更新成一样的值没关系,这个只考虑要更新的记录数。 |
| LINK:https://ask.csdn.net/questions/7646298?answer=53694387 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645949 |
| ANSWER_ID:53693925 |
| TITLE:excel里把日期时间改成2022-02-10 07:11:13 |
| ANSWER: 自定义单元格格式
|
| LINK:https://ask.csdn.net/questions/7645949?answer=53693925 |

| SOURCE:CSDN_ASK |
| ASK_ID:7645884 |
| ANSWER_ID:53693864 |
| TITLE:SQL计算同指令下最晚完成时间及状态个数和完成情况。 |
| ANSWER: 是什么数据库?版本多少? 只要是支持开窗函数的数据库,都可以用下面的方式来查询 |
| LINK:https://ask.csdn.net/questions/7645884?answer=53693864 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645922 |
| ANSWER_ID:53693859 |
| TITLE:怎么让sql查询的两个结果,对比只显示结果不同的。 |
| ANSWER: 最简单的方式,用except 或者用exists 或者用 in,上面有人贴了代码了 |
| LINK:https://ask.csdn.net/questions/7645922?answer=53693859 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645939 |
| ANSWER_ID:53693834 |
| TITLE:Oracle Function执行结果诡异现场,求解释 |
| ANSWER: 这个条件有歧义,建议把传入参数的名称改一下
|
| LINK:https://ask.csdn.net/questions/7645939?answer=53693834 |

| SOURCE:CSDN_ASK |
| ASK_ID:7645788 |
| ANSWER_ID:53693548 |
| TITLE:关于hive的一个小问题 |
| ANSWER: 差不多,不过我会选择先过滤数据再进行聚合 另外,我看你这个sql最后还是想查对应订单的原始记录?
|
| LINK:https://ask.csdn.net/questions/7645788?answer=53693548 |

| SOURCE:CSDN_ASK |
| ASK_ID:7645707 |
| ANSWER_ID:53693531 |
| TITLE:mysql开头替换的问题。 |
| ANSWER: 还可以用正则替换
有些mysql版本语法不一样,可能要改成
|
| LINK:https://ask.csdn.net/questions/7645707?answer=53693531 |


| SOURCE:CSDN_ASK |
| ASK_ID:7645608 |
| ANSWER_ID:53693335 |
| TITLE:vs code 不能输出中文, |
| ANSWER: 选gbk试试 |
| LINK:https://ask.csdn.net/questions/7645608?answer=53693335 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645655 |
| ANSWER_ID:53693327 |
| TITLE:mysql数据库导入 |
| ANSWER: 是一张表还是多张表? |
| LINK:https://ask.csdn.net/questions/7645655?answer=53693327 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645652 |
| ANSWER_ID:53693323 |
| TITLE:求一个sql语句同时满足条件 |
| ANSWER: 别把 and 条件 和 or条件写在同一级 另外,你题目里说的 既为空又不等于4, 这是矛盾的,不知道你是不是想表达下面这个意思 不管你使用等于或者不等于都会把空的去掉, 注意中间的 括号是要当成一个整体,去掉括号逻辑就错了 方法二 其实就是把空值变成不是空的,这样就可以判断了,但是这样就用不上索引了 |
| LINK:https://ask.csdn.net/questions/7645652?answer=53693323 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645657 |
| ANSWER_ID:53693311 |
| TITLE:sql server 写select有没有 像 oracle里的dual |
| ANSWER: 不需要from和后面的东西
|
| LINK:https://ask.csdn.net/questions/7645657?answer=53693311 |

| SOURCE:CSDN_ASK |
| ASK_ID:7645640 |
| ANSWER_ID:53693284 |
| TITLE:应为nunumber,但却获得char |
| ANSWER: degreetype和edutype 是数字,但是 degreetype || edutype 是字符串 ,所以有两种修改方式 2.全部定义成数字 |
| LINK:https://ask.csdn.net/questions/7645640?answer=53693284 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645338 |
| ANSWER_ID:53693097 |
| TITLE:mysql如何将拼接的字符串作为字段名进行查询 |
| ANSWER: sql中的字符串不能直接作为sql中的表名、列名、操作符等,它就只是一个值而已, |
| LINK:https://ask.csdn.net/questions/7645338?answer=53693097 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645391 |
| ANSWER_ID:53693084 |
| TITLE:DB多表查询,多个表结构一样,怎么一次查回 |
| ANSWER: 只用查询sql的话,你这个需求肯定只能用union all |
| LINK:https://ask.csdn.net/questions/7645391?answer=53693084 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645437 |
| ANSWER_ID:53693077 |
| TITLE:Python打包cx_Oracle模块后报错ORA-01804 |
| ANSWER: cx_Oracle是需要oracle的instantclient客户端的,在连接到数据库之前,会访问操作系统的环境变量,来获取oracle客户端所在路径,并加载相关的动态库文件。 |
| LINK:https://ask.csdn.net/questions/7645437?answer=53693077 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645470 |
| ANSWER_ID:53693053 |
| TITLE:之前mysql版本太低了,重装了一个新的8版本的,但是没办法正常启动 |
| ANSWER: 建议不要使用中文目录 |
| LINK:https://ask.csdn.net/questions/7645470?answer=53693053 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645523 |
| ANSWER_ID:53693048 |
| TITLE:Postgresql找不到服务的问题 |
| ANSWER: 检查操作系统日志,重点排查上次能连接到不能连接之间的所有日志,看看是否有执行过卸载软件或者删除服务的指令 |
| LINK:https://ask.csdn.net/questions/7645523?answer=53693048 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645527 |
| ANSWER_ID:53693046 |
| TITLE:oracle plsql developer执行代码后无法终止(break) |
| ANSWER: 查看下此会话的等待事件是什么,可能有阻塞。 |
| LINK:https://ask.csdn.net/questions/7645527?answer=53693046 |
| SOURCE:CSDN_ASK |
| ASK_ID:7645054 |
| ANSWER_ID:53692299 |
| TITLE:mysql 树状图数据 递归升级版问题 |
| ANSWER: mysql 树状图数据递归。升级版问题-大数据-CSDN问答 CSDN问答为您找到mysql 树状图数据递归。升级版问题相关问题答案,如果想了解更多关于mysql 树状图数据递归。升级版问题 mysql、sql、数据库 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7645060?spm=1005.2025.3001.5141 查询效果
|
| LINK:https://ask.csdn.net/questions/7645054?answer=53692299 |

| SOURCE:CSDN_ASK |
| ASK_ID:7645106 |
| ANSWER_ID:53692252 |
| TITLE:oracle怎么写函数把英文双引号转化成中文双引号? |
| ANSWER: 如果不要求成对的话,直接用replace就好了,英文双引号是不存在左右的,但中文双引号有左右之分 如果要求左右成对,可能就有点麻烦,因为不确定这个字符串中是否存在中英文双引号混用,以及是否存在多对双引号的情况,不能简单的按单数位置的双引号改成左双引号,双数位置的双引号改成右双引号,因此在不清楚数据到底有哪些可能性的情况下,这个可能都得靠机器学习来识别语义了。
|
| LINK:https://ask.csdn.net/questions/7645106?answer=53692252 |

| SOURCE:CSDN_ASK |
| ASK_ID:7644821 |
| ANSWER_ID:53692018 |
| TITLE:下载了Oracle VM virtualBox, |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7644821?answer=53692018 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644897 |
| ANSWER_ID:53692015 |
| TITLE:oracle数据库监听程序无法识别连接描述符中请求的服务 |
| ANSWER: 去windows的服务里启动oracle相关的服务,至少要把service和listener这两个启动了,如果启动不了,数据库就坏了,需要查看日志进行修复,对于初学者可能会比较麻烦 |
| LINK:https://ask.csdn.net/questions/7644897?answer=53692015 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644288 |
| ANSWER_ID:53691294 |
| TITLE:sql,给一个start时间和end时间,其中有m个断点时间,要踢出这m个月的时间,最后返回m+1条数据把区间返回 |
| ANSWER: 用的是什么数据库?
|
| LINK:https://ask.csdn.net/questions/7644288?answer=53691294 |

| SOURCE:CSDN_ASK |
| ASK_ID:7644464 |
| ANSWER_ID:53691288 |
| TITLE:电脑开机出现问题,按f1之后又说电脑有问题,重新启动,请问怎么解决 |
| ANSWER: 插在第四个口的硬盘有故障
这里已经说得很清楚了, BAD了,要么走售后,要么自己去买一块硬盘换上去 |
| LINK:https://ask.csdn.net/questions/7644464?answer=53691288 |

| SOURCE:CSDN_ASK |
| ASK_ID:7644424 |
| ANSWER_ID:53691272 |
| TITLE:sql表A里有1212212表B里1对应a,2对应b如何将表A里的数据统计个数并将1和2改成a与b |
| ANSWER: 你的意思是你有个A表,然后里面有一个字段,这个字段只有1或者2两种值,然后想把1更新成a,2更新成b,并统计出a有多少个和b有多少个? 如果1212212是一个字符串,要更新成ababbab,用translate函数即可 |
| LINK:https://ask.csdn.net/questions/7644424?answer=53691272 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644448 |
| ANSWER_ID:53691259 |
| TITLE:sql 做连接查询,表1单条数据必须对应表2多行数据 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7644448?answer=53691259 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644434 |
| ANSWER_ID:53691253 |
| TITLE:MySQL如何使用count(left()) |
| ANSWER: count是用来计数的,只要不是空值,每行都会记为1,left(code,7) 返回的是code的前7位,比如 left('AA001-11',7) 返回的是 'AA001-1', 如果是mysql8.0以上,可以用下面的sql |
| LINK:https://ask.csdn.net/questions/7644434?answer=53691253 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644148 |
| ANSWER_ID:53691006 |
| TITLE:遇到一个MYSQL错误 |
| ANSWER: sql语法错误,请把你的完整sql贴出来 |
| LINK:https://ask.csdn.net/questions/7644148?answer=53691006 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644257 |
| ANSWER_ID:53690999 |
| TITLE:oracle数据库表结构设计规范 |
| ANSWER: 别信什么通用的,楼上文章里第一条全小写就不对了,oracle里更常见的是全大写,很少有用小写。 |
| LINK:https://ask.csdn.net/questions/7644257?answer=53690999 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644322 |
| ANSWER_ID:53690984 |
| TITLE:sql请教,有点疑惑,不知道要怎么写 |
| ANSWER: 请说明是用的什么数据库。 以上sql在oracle、mysql8.0、sqlserver、hive、postgresql等等数据库里都是支持的 |
| LINK:https://ask.csdn.net/questions/7644322?answer=53690984 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644349 |
| ANSWER_ID:53690980 |
| TITLE:SQLCODE=-206, SQLSTATE=42703 |
| ANSWER: 你把你sql里面, as 后面的列名的双引号全部去掉,然后把那个 RATE_START_DATE 改成 RATESTARTDATE 。 |
| LINK:https://ask.csdn.net/questions/7644349?answer=53690980 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644050 |
| ANSWER_ID:53690435 |
| TITLE:python相关提问 |
| ANSWER: 必须网页本身具有PC端和移动端网页自适应的模式才行,这样只需要调整浏览器的分辨率及设备信息就行了。 |
| LINK:https://ask.csdn.net/questions/7644050?answer=53690435 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644060 |
| ANSWER_ID:53690428 |
| TITLE:VMware “用户在命令行上发出了 EULAS_AGREED=1,表示不接受许可协议。” |
| ANSWER: 能不能上个图看看? |
| LINK:https://ask.csdn.net/questions/7644060?answer=53690428 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644057 |
| ANSWER_ID:53690423 |
| TITLE:mysql查询出现查询条件影响查询字段值的诡异问题求解 |
| ANSWER: sql哪有你这么写的,套了十几层,不就left join 么,有必要加一个表就套一层么? |
| LINK:https://ask.csdn.net/questions/7644057?answer=53690423 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644098 |
| ANSWER_ID:53690412 |
| TITLE:关于#数据库#的问题,如何解决? |
| ANSWER: 题目没说如果不是年初第一天开始的情况,我先假设至少都是从年初第一天就开始有数据的吧。 假设要查所有账户代码的 |
| LINK:https://ask.csdn.net/questions/7644098?answer=53690412 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644054 |
| ANSWER_ID:53690395 |
| TITLE:关于#c##的问题:SqlDBA数据层_错误2为过程或函数 XWWL_UPDATE_USER_DATA_NEW指定了过多的参数 String_0 |
| ANSWER: 你去数据库里看一下 XWWL_UPDATE_USER_DATA_NEW有几个参数,然后调试的时候打印一下参数,看看传了几个参数进去 |
| LINK:https://ask.csdn.net/questions/7644054?answer=53690395 |
| SOURCE:CSDN_ASK |
| ASK_ID:7644004 |
| ANSWER_ID:53690225 |
| TITLE:对于数据之间有逗号的数据应该怎么进行表连接查询(SQL) |
| ANSWER: 是用的什么数据库? postgresql,可以用unnest结合string_to_array,将指定字符串按指定分隔符转成一列
然后再去join,最后再聚合就行了
|
| LINK:https://ask.csdn.net/questions/7644004?answer=53690225 |


| SOURCE:CSDN_ASK |
| ASK_ID:7644002 |
| ANSWER_ID:53690220 |
| TITLE:两条相同的数据 返回其中一条 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7644002?answer=53690220 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643931 |
| ANSWER_ID:53690131 |
| TITLE:根据身份证号获取年龄大于60岁的人 |
| ANSWER: 因为你标签写的是oracle,我先写了这个
实际上就是截取字符串,然后转成日期,oracle里的日期可以直接相减得到相差的天数,最后直接除以一年的天数就行了,但这里其实有个需求没有描述清楚,所谓的60岁,是指过了60岁生日之后才算60岁,还是只要当前年和出生年之间相差60年就算60岁?继续深究的话,每年的天数都不一样,这个问题会变得很复杂,所以我上面直接除了个每年天数的近似值 另外,DB2里虽然也可以to_date(substr('430123200010011234',7,8),'yyyymmdd') 这样写,但是由于它的单位不是天,因此直接相减不等于天,需要转成day再减
|
| LINK:https://ask.csdn.net/questions/7643931?answer=53690131 |


| SOURCE:CSDN_ASK |
| ASK_ID:7643928 |
| ANSWER_ID:53690115 |
| TITLE:python 读取数据库上亿级数据如何去重呢 |
| ANSWER: 上亿的数据量,读出来都很费时间了,不仅内存扛不住,网络带宽、磁盘io都会有压力。为什么不直接在源数据库里用sql去重呢? |
| LINK:https://ask.csdn.net/questions/7643928?answer=53690115 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643915 |
| ANSWER_ID:53690109 |
| TITLE:MySQL 触发器未实现功能 |
| ANSWER: 因为你触发器监视的是update 动作,而不是insert动作,因此插入并不会触发, |
| LINK:https://ask.csdn.net/questions/7643915?answer=53690109 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643871 |
| ANSWER_ID:53689989 |
| TITLE:这应该是哪里的问题呐 |
| ANSWER: 你在那个服务那里鼠标右键查看属性,就可以看到这个服务启动程序的路径,再去找这个路径下是不是有对应的这个文件 |
| LINK:https://ask.csdn.net/questions/7643871?answer=53689989 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643847 |
| ANSWER_ID:53689985 |
| TITLE:这是 我oracle数据库中的数据 |
| ANSWER: 首先,纯数字不能作为字段名,我会把你的1和2,改成D1,D2
|
| LINK:https://ask.csdn.net/questions/7643847?answer=53689985 |

| SOURCE:CSDN_ASK |
| ASK_ID:7643866 |
| ANSWER_ID:53689966 |
| TITLE:mysql 如何查询每个用户消费金额最大的记录? |
| ANSWER: "每个用户消费金额最大的记录" 当然是指的 这绝对没有任何问题,但是,原问题真的是这个么? 不过,开窗函数在mysql里,得8.0以上版本才支持 另外,你第二个sql,查的其实是每个用户最高金额的订单id,但这样查的话,同一个用户最高金额如果有两笔订单,也会一起展现出来 |
| LINK:https://ask.csdn.net/questions/7643866?answer=53689966 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643800 |
| ANSWER_ID:53689959 |
| TITLE:请问这道难题要怎么解,用mysql和oracle都行 |
ANSWER:
用的oracle,LISTAGG这个函数在最新的几个oracle版本里变更了好多次,上面这个sql有一点点缺陷,就是逗号多了,需要用listagg(distinct)来处理,但不清楚你的oracle的版本,所以我没加,或者直接用正则替换把两个以上的逗号替换成一个逗号,再去掉首尾的逗号也行。 |
| LINK:https://ask.csdn.net/questions/7643800?answer=53689959 |

| SOURCE:CSDN_ASK |
| ASK_ID:7643760 |
| ANSWER_ID:53689824 |
| TITLE:mysql条件查询 where条件的字段不判断默认是多少? |
| ANSWER: where后面的都是布尔型,非布尔型的值都是真true,也就是恒成立 |
| LINK:https://ask.csdn.net/questions/7643760?answer=53689824 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643768 |
| ANSWER_ID:53689823 |
| TITLE:按时间批量建表报了ORA-02264:名称已被一个现有约束条件占用 |
| ANSWER: oracle里面的约束在一个schema下的确不能重名,与是不是在同一张表里没关系 |
| LINK:https://ask.csdn.net/questions/7643768?answer=53689823 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643820 |
| ANSWER_ID:53689817 |
| TITLE:为什么select语句和join出来的记录数据一样(语言-开发语言) |
| ANSWER: join是把两个表左右横着放,union all是把两个表上下竖着放 |
| LINK:https://ask.csdn.net/questions/7643820?answer=53689817 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643391 |
| ANSWER_ID:53689299 |
| TITLE:资源管理器提示内存使用率100%,如何处理 |
| ANSWER: 如果开了虚拟化的话,你的主操作系统就和其他虚拟机环境是平级的,只能看到自己的内存使用情况,看不到其他虚拟化环境内存的使用情况 |
| LINK:https://ask.csdn.net/questions/7643391?answer=53689299 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643533 |
| ANSWER_ID:53689290 |
| TITLE:用什么语言或者什么库可以实现解析Json文件里的$符号 |
| ANSWER: 这玩意不能直接当成json格式用,建议直接用字符串的方式进行解析,从头开始遍历每一个字符,遇到"${"开始记录.遇到"}"保存一个元素 |
| LINK:https://ask.csdn.net/questions/7643533?answer=53689290 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643406 |
| ANSWER_ID:53689281 |
| TITLE:数据库中一列数据中带有括号,只求括号内的内容 |
| ANSWER: 用正则,但是得看是什么数据库,不同数据库的正则表达式有区别,比如postgresql的是
但同样的正则表达式在mysql和Oracle里是查不出来的,因为转义符及函数参数可能有区别。 另外,还有一种通用的思路,就是用instr函数来定位左括号和右括号出现的位置,再用substr来进行截取
|
| LINK:https://ask.csdn.net/questions/7643406?answer=53689281 |


| SOURCE:CSDN_ASK |
| ASK_ID:7643546 |
| ANSWER_ID:53689268 |
| TITLE:如何截取长度不一致的字符串? |
| ANSWER: charindex的位置是从左往右数的位置,charindex(',',notext) 这个返回的一直都是第一个逗号的位置,没有实际价值,因为你无法确定后面逗号出现的长度规律,既有两位数字也有一位数字。 |
| LINK:https://ask.csdn.net/questions/7643546?answer=53689268 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640481 |
| ANSWER_ID:53689241 |
| TITLE:关于软件开源的一些问题 |
| ANSWER: 其实这个要看你的开源协议是怎么写的。开源协议就相当于民事合同,什么能做什么不能做都写在里面了,如果有必要的话,还可以针对开源协议模板进行细节描述修改。 举个实际的例子,目前华为的GaussDB是闭源的,但openGauss是开源的,这两个数据库互相吸收另一个的代码,在声明中都有按照开源协议注明代码来源 |
| LINK:https://ask.csdn.net/questions/7640481?answer=53689241 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643161 |
| ANSWER_ID:53688851 |
| TITLE:请问SQL里怎样替换字段里类似“120115-”这样6位数加横线的字符串? |
| ANSWER: 这典型的正则替换嘛 实测截图
|
| LINK:https://ask.csdn.net/questions/7643161?answer=53688851 |

| SOURCE:CSDN_ASK |
| ASK_ID:7643209 |
| ANSWER_ID:53688819 |
| TITLE:MySQL 中用LIMIT获取最后5条数据 |
| ANSWER: 你这个语法其实对于标准sql来说是个错的, 如果存在group by ,那么未聚合的字段必须都接在group by 后面, |
| LINK:https://ask.csdn.net/questions/7643209?answer=53688819 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643262 |
| ANSWER_ID:53688810 |
| TITLE:MYSQL能否实现将字符串转换为表达式进行计算? |
| ANSWER: sql不能把字符串当成指令的,只能用存储过程,存储过程里可以把字符串当成动态sql执行,具体可以搜索一下 "mysql 动态sql" 进行了解 |
| LINK:https://ask.csdn.net/questions/7643262?answer=53688810 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643323 |
| ANSWER_ID:53688789 |
| TITLE:Pd 里面注释变成这样了…… |
| ANSWER: 到设置里把显示的字体改了,有些字体就是这样显示的 |
| LINK:https://ask.csdn.net/questions/7643323?answer=53688789 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643008 |
| ANSWER_ID:53688297 |
| TITLE:除了用 STRING_SPLIT重新排序 现在学习下面的函数,但是老数据没有更新,但不知道错误出现在哪里?特此提问请教 |
| ANSWER: 先不急着更新,尝试先select这个函数,传入某一条记录的字符串,看看查出来是什么东西 |
| LINK:https://ask.csdn.net/questions/7643008?answer=53688297 |
| SOURCE:CSDN_ASK |
| ASK_ID:7643034 |
| ANSWER_ID:53688296 |
| TITLE:请问爬虫里怎么自动爬取多个网页的数据汇总到一个表? |
| ANSWER: 只要能写一个,你就把链接做成参数, |
| LINK:https://ask.csdn.net/questions/7643034?answer=53688296 |
| SOURCE:CSDN_ASK |
| ASK_ID:7642931 |
| ANSWER_ID:53688040 |
| TITLE:PHP登录如何实现多个用户数据表的查询? |
| ANSWER: 哪里有你这么写的,如果用户数多了,难道每次登录都去把所有用户信息捞一次? |
| LINK:https://ask.csdn.net/questions/7642931?answer=53688040 |
| SOURCE:CSDN_ASK |
| ASK_ID:7642896 |
| ANSWER_ID:53687933 |
| TITLE:mysql数据库导入.sql文件显示乱码 |
| ANSWER: 在cmd里,先输入chcp 65001 并回车,然后再登录mysql查询数据 |
| LINK:https://ask.csdn.net/questions/7642896?answer=53687933 |
| SOURCE:CSDN_ASK |
| ASK_ID:7642525 |
| ANSWER_ID:53687495 |
| TITLE:WIN10安装UltraEdit软件如何解决乱码问题? |
| ANSWER: 你下载错了版本,这个是繁体中文版的,字符集是big5,你这简体中文系统打开当然乱码了
|
| LINK:https://ask.csdn.net/questions/7642525?answer=53687495 |

| SOURCE:CSDN_ASK |
| ASK_ID:7642608 |
| ANSWER_ID:53687454 |
| TITLE:正则表达式问题,帮个忙 |
| ANSWER: 你这个字符串里是没有回车的, ""这个符号表示一行拆开,但实际上还是一行,看下面这个例子
如果是要截取指定字符串后面的所有字符
如果是要截后面的分辨率
|
| LINK:https://ask.csdn.net/questions/7642608?answer=53687454 |



| SOURCE:CSDN_ASK |
| ASK_ID:7642258 |
| ANSWER_ID:53687123 |
| TITLE:数据库排序问题,麻烦了 |
| ANSWER: 建一个新表,有两个字段,id自增步长为2初始为2, 还有一个科目名称字段,然后 这样既更新了数据,又保留了id和科目名称的对应关系,如果直接更新的话,你就不知道数字是对应哪个科目了 |
| LINK:https://ask.csdn.net/questions/7642258?answer=53687123 |
| SOURCE:CSDN_ASK |
| ASK_ID:7642259 |
| ANSWER_ID:53687119 |
| TITLE:关于#sql#的问题:需要在mysql数据库对表进行排序 |
| ANSWER: 这个题其实有个矛盾点, 如果只是想随机取个序号,那就不一定语文非得是2,随便弄个序号乘以2就是了 |
| LINK:https://ask.csdn.net/questions/7642259?answer=53687119 |
| SOURCE:CSDN_ASK |
| ASK_ID:7642302 |
| ANSWER_ID:53687071 |
| TITLE:mid(tex1,instr(text1,"通信原理、")+5)这个+5是什么意思 |
| ANSWER: instr返回的是指定字符串所在的位置,返回值是个整数,当然可以进行加减运算 |
| LINK:https://ask.csdn.net/questions/7642302?answer=53687071 |
| SOURCE:CSDN_ASK |
| ASK_ID:7642186 |
| ANSWER_ID:53686775 |
| TITLE:uni-app怎样实现隐藏手机号中间位数,又能成功登录? |
| ANSWER: 定义一个样式,隐藏中间几位数,在页面对这个标签指定使用该样式,实际值和显示值就可以不一样了,这其实和密码处理的方式很类似 |
| LINK:https://ask.csdn.net/questions/7642186?answer=53686775 |
| SOURCE:CSDN_ASK |
| ASK_ID:7642209 |
| ANSWER_ID:53686772 |
| TITLE:excel表格数据怎么用SQL体现出来 |
| ANSWER: 看你使用的是什么数据库,不同数据库有不同的连接工具,当然也有通用的工具,比如navicat Premium 、dbeaver等,打开工具后,连接数据库,在数据库中建好目标表,然后选择导入功能导入数据即可。 |
| LINK:https://ask.csdn.net/questions/7642209?answer=53686772 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641741 |
| ANSWER_ID:53686309 |
| TITLE:postgreSQL 报错:portal "C_93" does not exist |
| ANSWER: 你使用其他工具运行这个sql并导出数据会不会报错? |
| LINK:https://ask.csdn.net/questions/7641741?answer=53686309 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641691 |
| ANSWER_ID:53685749 |
| TITLE:mysql中case语句返回的结果不是预期结果 |
| ANSWER: 你这个case when 的else null位置写错了,语法应该是 另外,你这问题说是mysql,标签又选个mssql,到底是哪个? |
| LINK:https://ask.csdn.net/questions/7641691?answer=53685749 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641660 |
| ANSWER_ID:53685748 |
| TITLE:SQL数据分析面试疑问? |
ANSWER:比例的话,除一下就是了 两个表不直接join的原因是,一个用户可能存在多次登陆记录,直接join会造成内存中的数据翻倍,可能会影响数据库中的其他业务,非得join的话,需要先把登陆表去个重,确保用户id唯一,再去join |
| LINK:https://ask.csdn.net/questions/7641660?answer=53685748 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641612 |
| ANSWER_ID:53685633 |
| TITLE:kafka消费者如何在Linux命令行后台执行 |
| ANSWER: Linux下使Shell 命令脱离终端在后台运行_Linux教程_Linux公社-Linux系统门户网站 你是否遇到过这样的情况:从终端软件登录远程的Linux主机,将一堆很大的文件压缩为一个.tar.gz文件,连续压缩了半个小时还没有完 https://www.linuxidc.com/Linux/2011-05/35723.htm |
| LINK:https://ask.csdn.net/questions/7641612?answer=53685633 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641558 |
| ANSWER_ID:53685630 |
| TITLE:Cause: java.sql.SQLSyntaxErrorException: ORA-00907: 缺失右括号 |
| ANSWER: 你这个写法应该是绑定变量,而不是拼字符串替换,因此需要进行参数拼接,比如 |
| LINK:https://ask.csdn.net/questions/7641558?answer=53685630 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641494 |
| ANSWER_ID:53685445 |
| TITLE:Excel如何在筛选数据源的同时实现数据透视表的同步更新? |
| ANSWER: 你筛选数据源这个动作是在excel里面手动点的?那这题貌似与python和sql没有任何关系了。。。 Excel多表同时筛选 - 知乎 VBA代码如下: Sub g() For Each wsh In Sheets wsh.Select wsh.UsedRange.AutoFilter field:=2, Criteria1:="男" Next wsh End Sub 释义: field:=2, Criteria1:="男" 释义:"2"代表第二列,"男"代表要筛选出男性。 可以根据自己实际情况进行调换 https://www.zhihu.com/zvideo/1241736739649466368 在这段代码的基础上,再做个输入框及按钮,点击时,将输入框的值传入vba,来触发该事件 |
| LINK:https://ask.csdn.net/questions/7641494?answer=53685445 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641347 |
| ANSWER_ID:53685203 |
| TITLE:excel怎么把数据单位化成亿,并且保留一位小数 |
| ANSWER: 直接把数据除以100000000,并round保留1位小数(或者设置单元格格式为保留一位小数) |
| LINK:https://ask.csdn.net/questions/7641347?answer=53685203 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641184 |
| ANSWER_ID:53685182 |
| TITLE:数据透视表显示报表筛选页如何只显示单个的数据 |
| ANSWER: 这题的难点看上去与数据透视表本身没有关系,只是想达到一个根据某列数据的值,自动把数据分到不同sheet的效果,每个sheet里的那个负责人筛选没有任何意义,反正每个sheet只有一个负责人,干啥还要给个筛选? 数据透视表中的显示报表筛选页只是自动复制了多个sheet页,并且自动完成了筛选显示,实际上未筛选的数据都是一样的,但只要用户不去操作筛选,每个sheet显示的数据就已经是分开的了,这看上去也没问题呀。如果不想让用户筛选,那就对每个分出来的表再复制选择性粘贴一次呗。 其实还是写个脚本来处理更方便一些,比如用python |
| LINK:https://ask.csdn.net/questions/7641184?answer=53685182 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641307 |
| ANSWER_ID:53685144 |
| TITLE:数据库ORA-12514:TNS:提示监听程序当前无法识别连接描述中的请求服务 |
| ANSWER: 先检查数据库监听是否正常开启,确认在数据库服务器上能通过sqlplus连接数据库 |
| LINK:https://ask.csdn.net/questions/7641307?answer=53685144 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641238 |
| ANSWER_ID:53685143 |
| TITLE:!监听程序无法识别链接描述符中请求的服务 |
| ANSWER: 先检查数据库监听是否正常开启,确认在数据库服务器上能通过sqlplus连接数据库 |
| LINK:https://ask.csdn.net/questions/7641238?answer=53685143 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641078 |
| ANSWER_ID:53685099 |
| TITLE:Oracle使用SQLloader提示sql*loader-406.导入没成功但也没报错 |
| ANSWER: 你把你写的loader命令和控制文件、还有表结构发出来看看 |
| LINK:https://ask.csdn.net/questions/7641078?answer=53685099 |
| SOURCE:CSDN_ASK |
| ASK_ID:7641001 |
| ANSWER_ID:53684580 |
| TITLE:MySql数据库查询的问题 |
| ANSWER: 这不就是正常join关联另外一个表就好了么? |
| LINK:https://ask.csdn.net/questions/7641001?answer=53684580 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640925 |
| ANSWER_ID:53684577 |
| TITLE:怎么把这条语句改成能够获取到表中最大月份并且往前面推5个月 加上最大月份一共六个月的数据 |
ANSWER:或者 |
| LINK:https://ask.csdn.net/questions/7640925?answer=53684577 |
| SOURCE:CSDN_ASK |
| ASK_ID:7469962 |
| ANSWER_ID:53684464 |
| TITLE:怎么能够在ARM架构的CentOS上安装Oracle数据库? |
| ANSWER: qemu能够仿真x86架构,但是,这个性能肯定比不上原生的x86 |
| LINK:https://ask.csdn.net/questions/7469962?answer=53684464 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640923 |
| ANSWER_ID:53684451 |
| TITLE:关于#数据库#的问题:数据库附加 |
| ANSWER: 你这是删除或者移动了数据库文件吧,先按这个提示去执行看看有些啥 |
| LINK:https://ask.csdn.net/questions/7640923?answer=53684451 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640845 |
| ANSWER_ID:53684376 |
| TITLE:关于数据库分表的作用 |
| ANSWER: 你这都插入数据进去了,咋还说子表不是真正存在? |
| LINK:https://ask.csdn.net/questions/7640845?answer=53684376 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640838 |
| ANSWER_ID:53684350 |
| TITLE:使用mysql语句获取表中最大时间的值条件语句应该怎么写 |
| ANSWER: 你这sql是oracle语法,咋问的是mysql?? |
| LINK:https://ask.csdn.net/questions/7640838?answer=53684350 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640717 |
| ANSWER_ID:53684345 |
| TITLE:行转列,需要公司近三十天的销售量(30列) |
| ANSWER: 在hive里,可以使用map和collect_list来实现pivot表格的效果 测试效果
这种写法比case when还是要简洁一点 |
| LINK:https://ask.csdn.net/questions/7640717?answer=53684345 |

| SOURCE:CSDN_ASK |
| ASK_ID:7640494 |
| ANSWER_ID:53684237 |
| TITLE:oracle 千万级数据group by或distinct如何优化 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7640494?answer=53684237 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640420 |
| ANSWER_ID:53683666 |
| TITLE:你好 请问下java.sql.SQLException: 列名无效 这个怎么解决 我的字段和数据库是一样的 |
| ANSWER: 你把你下面写的列名,全部改成大写的试试。 |
| LINK:https://ask.csdn.net/questions/7640420?answer=53683666 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640411 |
| ANSWER_ID:53683650 |
| TITLE:php以表格表格形式输出数据表中的内容,其中一个字段是blob图片。echo输出图片的部分变成满屏的乱码,该怎么办 |
| ANSWER: 这是直接把二进制数据流当成文本打开了吧,要定义一下流的格式为图片 |
| LINK:https://ask.csdn.net/questions/7640411?answer=53683650 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640270 |
| ANSWER_ID:53683314 |
| TITLE:ORACLE SQL表数据丢失 |
| ANSWER: 有列名说明sql正常执行了,没有数据那就是真的没有数据。 |
| LINK:https://ask.csdn.net/questions/7640270?answer=53683314 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640237 |
| ANSWER_ID:53683309 |
| TITLE:MYSQL出现菱形问号乱码 |
| ANSWER: 再看下代码文件本身的文本编码是ansi还是utf8,包括前端和后端 |
| LINK:https://ask.csdn.net/questions/7640237?answer=53683309 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640084 |
| ANSWER_ID:53683303 |
| TITLE:有个Oracle 问题 这怎么调用能输出两张表 |
| ANSWER: 你具体是想做什么? |
| LINK:https://ask.csdn.net/questions/7640084?answer=53683303 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640128 |
| ANSWER_ID:53683289 |
| TITLE:navicat导入csv数据 |
| ANSWER: 这肯定是因为你csv里有多的空行呀,不信你用记事本把csv文件打开看看,注意把自动换行关了 |
| LINK:https://ask.csdn.net/questions/7640128?answer=53683289 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640136 |
| ANSWER_ID:53683287 |
| TITLE:mysql和oracle学哪个? |
| ANSWER: 如果在全球范围内,按使用体量的总和来看,oracle甩mysql好远,你看上去mysql多,那只是坐井观天,是由于你所处环境的局限性而产生的错觉。 |
| LINK:https://ask.csdn.net/questions/7640136?answer=53683287 |
| SOURCE:CSDN_ASK |
| ASK_ID:7640236 |
| ANSWER_ID:53683254 |
| TITLE:pymssql控制SQL进行中文查询 |
| ANSWER: 大概率是字符集的问题,请确认文件编码及字符集的一致性。 |
| LINK:https://ask.csdn.net/questions/7640236?answer=53683254 |
| SOURCE:CSDN_ASK |
| ASK_ID:7639949 |
| ANSWER_ID:53682559 |
| TITLE:就是像某宝的一样的购物车。 |
| ANSWER: 如果用户不访问购物车的话,购物车里的数据不会动,这是为了节省后台服务的开销; |
| LINK:https://ask.csdn.net/questions/7639949?answer=53682559 |
| SOURCE:CSDN_ASK |
| ASK_ID:7639798 |
| ANSWER_ID:53682219 |
| TITLE:在oracle中查询kettle使用的表名 |
| ANSWER: 如果表名有特征,比如都包含某几个字符,那么可以使用类似下面的sql来查询所有与之有关的表名或job |
| LINK:https://ask.csdn.net/questions/7639798?answer=53682219 |
| SOURCE:CSDN_ASK |
| ASK_ID:7639760 |
| ANSWER_ID:53682073 |
| TITLE:有的教程把数据库安装在乌班图上面是为了不占电脑内存么? |
| ANSWER: 不管安装在哪,都会占磁盘空间,跑起来也都会占内存。乌班图和Windows同样都是操作系统,根据你的描述来看,你说的乌班图应该是Windows下的虚拟机里的操作系统,相当于是电脑里面又虚拟了一台电脑。乌班图是linux的发行版之一,实际上目前生产环境服务器大多都是用的linux,使用linux搭建环境更贴合实际。另外,环境搭虚拟机里想删就直接删,不会对你本地的系统造成任何影响;环境搭本地,想卸载都不一定能卸干净 |
| LINK:https://ask.csdn.net/questions/7639760?answer=53682073 |
| SOURCE:CSDN_ASK |
| ASK_ID:7639337 |
| ANSWER_ID:53681463 |
| TITLE:Python初学者的问题 |
| ANSWER: 你这是在学习,他当然要教你各种各样的语法,这个例子只是在教你可以在函数里可以掉用自己,来实现迭代的效果。如果是有复杂的逻辑,你自然会发现这种写法的好处,现阶段建议先把语法吃透 |
| LINK:https://ask.csdn.net/questions/7639337?answer=53681463 |
| SOURCE:CSDN_ASK |
| ASK_ID:7639419 |
| ANSWER_ID:53681446 |
| TITLE:vmware 虚拟机安装 |
| ANSWER: 你这几张图都不影响安装呀,只是一个打印机无法连接而已,如果不想要弹这个提示,虚拟机设置里把打印机关掉就是了。 |
| LINK:https://ask.csdn.net/questions/7639419?answer=53681446 |
| SOURCE:CSDN_ASK |
| ASK_ID:7639277 |
| ANSWER_ID:53681169 |
| TITLE:virtualbox在Mac m1中安装说找不到硬件架构怎么解决啊? |
| ANSWER: 没法解决,virtualbox本就不支持arm架构,而且也没有计划去支持,
所以,建议使用其他虚拟机,比如Parallels Desktop m1 mac 如何使用 linux 虚拟机? - 知乎 想到下面三个方案Parallel Desktop,要钱,不想花钱Docker ,残废,只是个容器不是虚拟机云主机,依赖网… https://www.zhihu.com/question/497461081 |
| LINK:https://ask.csdn.net/questions/7639277?answer=53681169 |


| SOURCE:CSDN_ASK |
| ASK_ID:7639234 |
| ANSWER_ID:53681164 |
| TITLE:搜索引擎--为什么要分词 |
| ANSWER: 用完整语句去搜索,很可能会什么都搜不到,因为搜索这个动作是用的绝对匹配,必须保证两个字符串完全相等才算匹配,比如你搜一句话
这样就能以很少的存储及较快的效率,来识别到较为准确的匹配,当然,这个肯定算不上精准,所以,就有了自然语义AI的诞生,更高阶的神经网络机器学习,能把模型训练得接近人类思维,这样匹配就更精准了,但不过每个人都会有自己的个性,AI也如此,在训练的时候还得植入性格,这往往会给人们带来不愿意看到的答案。 |
| LINK:https://ask.csdn.net/questions/7639234?answer=53681164 |
| SOURCE:CSDN_ASK |
| ASK_ID:7639129 |
| ANSWER_ID:53681087 |
| TITLE:python在txt文件中寻找相应字符串 |
| ANSWER: 用正则表达式匹配字符串
|
| LINK:https://ask.csdn.net/questions/7639129?answer=53681087 |

| SOURCE:CSDN_ASK |
| ASK_ID:7639116 |
| ANSWER_ID:53680868 |
| TITLE:MySQL的 如何使用 |
| ANSWER: 把报错展开看看 |
| LINK:https://ask.csdn.net/questions/7639116?answer=53680868 |
| SOURCE:CSDN_ASK |
| ASK_ID:7639047 |
| ANSWER_ID:53680687 |
| TITLE:如何使用域名访问局域网网站(标签-服务器) |
| ANSWER: 只有一台设备需要访问的话,最简单的就是在这台设备上配置host文件,将指定域名指向你要求的ip,比如windows的hosts文件路径为”C:\Windows\System32\drivers\etc\hosts,打开后在最下面添加一行 保存,这样,当你访问www.baidu.com时就会自动解析成192.168.1.2进行访问 如果是局域网内多台设备都要访问这个域名,那么就要在路由器里设置了,不同品牌的路由器设置方式不一样 |
| LINK:https://ask.csdn.net/questions/7639047?answer=53680687 |
| SOURCE:CSDN_ASK |
| ASK_ID:7638982 |
| ANSWER_ID:53680682 |
| TITLE:word xml格式的文件如何存入MySQL数据库 |
| ANSWER: XML格式没有规定行列,一般是不能自动解析成表格,把每个值对应到数据库字段的值里去的。 |
| LINK:https://ask.csdn.net/questions/7638982?answer=53680682 |
| SOURCE:CSDN_ASK |
| ASK_ID:7638945 |
| ANSWER_ID:53680467 |
| TITLE:在数据库的select里面遇到了一个常见的问题 |
| ANSWER: 你第一个查询sql用了子查询,从这一段"group by app_id_c) APP LEFT JOIN client_t C“,可以看出,”APP“已经不是指的你数据库里的”APP“表了,而是指的你前面这个子查询,而这个子查询里,没有select ”done_status_c“这个字段,当然会报这个字段不存在了 |
| LINK:https://ask.csdn.net/questions/7638945?answer=53680467 |
| SOURCE:CSDN_ASK |
| ASK_ID:7638742 |
| ANSWER_ID:53680172 |
| TITLE:Python pandas读取excel文件时异常报错(某一worksheet有图片) |
| ANSWER: 那个不是图片,excel里的sheet分很多种,有的放数据,有的放图表,不同类型的sheet对象支持不同的方法, |
| LINK:https://ask.csdn.net/questions/7638742?answer=53680172 |
| SOURCE:CSDN_ASK |
| ASK_ID:7638729 |
| ANSWER_ID:53680158 |
| TITLE:windows sever2019如何搭建网盘 |
| ANSWER: 用nextcloud吧,有windows版本的,支持多账号管理,有网站页面,支持文件版本管理,支持webdav协议,还支持手机、pc文件自动同步至网盘(需对应设备安装客户端) |
| LINK:https://ask.csdn.net/questions/7638729?answer=53680158 |
| SOURCE:CSDN_ASK |
| ASK_ID:7638753 |
| ANSWER_ID:53680155 |
| TITLE:问一下这是什么加密方式,很长的一段 |
| ANSWER: 看上去像是base64编码,至于有没有加密就不确定了 |
| LINK:https://ask.csdn.net/questions/7638753?answer=53680155 |
| SOURCE:CSDN_ASK |
| ASK_ID:7638646 |
| ANSWER_ID:53680046 |
| TITLE:优化代码批量查询得到结果,请专家答疑解惑 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7638646?answer=53680046 |

| SOURCE:CSDN_ASK |
| ASK_ID:7638680 |
| ANSWER_ID:53680038 |
| TITLE:如果数据库中没有某天的订单信息,则用python插入数据,否则不插入。请教该怎么写code |
| ANSWER: 你确定是按日期插入?有没有可能某天的订单拆成两次给了? |
| LINK:https://ask.csdn.net/questions/7638680?answer=53680038 |
| SOURCE:CSDN_ASK |
| ASK_ID:7638338 |
| ANSWER_ID:53679439 |
| TITLE:docker top 命令执行结果第4列 C代表什么意思 |
| ANSWER: 和linux命令的top里显示的cpu是一个含义 |
| LINK:https://ask.csdn.net/questions/7638338?answer=53679439 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637883 |
| ANSWER_ID:53678848 |
| TITLE:关于从字符串集合中提取数据并且转置sql |
| ANSWER: 关于数据从集合中提取转置-大数据-CSDN问答 CSDN问答为您找到关于数据从集合中提取转置相关问题答案,如果想了解更多关于关于数据从集合中提取转置 mysql、sql 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7637882?spm=1005.2025.3001.5141 |
| LINK:https://ask.csdn.net/questions/7637883?answer=53678848 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637882 |
| ANSWER_ID:53678847 |
| TITLE:关于数据从集合中提取转置 |
| ANSWER: 你这个组成明显真长这样?确定不是这样? 如果是json的话,可以直接用json相关的函数进行解析,如果是你题目里这种格式,就只能先转成json再读了。
|
| LINK:https://ask.csdn.net/questions/7637882?answer=53678847 |

| SOURCE:CSDN_ASK |
| ASK_ID:7637817 |
| ANSWER_ID:53678625 |
| TITLE:SQL Server中A列对应2个或2个以上的B列值,根据C列值的大小,取最大值对应的B列值更新到D列 |
| ANSWER: 先用开窗函数,按始发城市分组,取出货量最大的一行,得到对应的目的城市,然后用始发城市关联到原表上即可 |
| LINK:https://ask.csdn.net/questions/7637817?answer=53678625 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637627 |
| ANSWER_ID:53678370 |
| TITLE:处理时间线问题,将拿出时间与放回时间最匹配 |
| ANSWER: 你这上一题还没采纳,改了个表结构又来问了?
|
| LINK:https://ask.csdn.net/questions/7637627?answer=53678370 |

| SOURCE:CSDN_ASK |
| ASK_ID:7637654 |
| ANSWER_ID:53678356 |
| TITLE:Mysql三个表怎么全局查询一个字段 |
| ANSWER: 麻烦把你的表结构、最终需要的格式、以及逻辑关系描述清楚 |
| LINK:https://ask.csdn.net/questions/7637654?answer=53678356 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637376 |
| ANSWER_ID:53678073 |
| TITLE:这是什么情况,win7开机就这样了,四个进入选项(安全模式)一类的都是这样 |
| ANSWER: 这个大概率可能是硬盘有损坏,当然还有可能是启动配置文件损坏 参考文章 https://jingyan.baidu.com/article/f0e83a25717e1922e4910151.html How to Fix An Unmountable Boot Volume in Windows 10? From this paper, you can know how to effectively fix “UNMOUNTABLE BOOT VOLUME” in Windows 10, which usually keeps you from getting into Windows 10. https://www.diskpart.com/windows-10/fix-unmountable-boot-volume-error-in-windows-10-4125.html UNMOUNTABLE_BOOT_VOLUME问题解决方案_donghustone的专栏-CSDN博客_boot volume 症状:本本跑着跑着突然重启,之后无法正常进入系统,出现蓝屏,报错:UNMOUNTABLE_BOOT_VOLUME(其他不相关英文单词略),进入安全模式报同样的错。解决方法:没见过这个问题,于是赶紧google了一下"UNMOUNTABLE_BOOT_VOLUME",发现是磁盘扇区被破坏导致。将硬盘拆下来,用移动硬盘盒装好放在台式机上一看,果然是硬盘有坏扇区,C盘和E盘都无法正常检测到。于是用w https://blog.csdn.net/donghustone/article/details/7705115 |
| LINK:https://ask.csdn.net/questions/7637376?answer=53678073 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637480 |
| ANSWER_ID:53678063 |
| TITLE:在Edge和chrome访问CSDN的时候提示说安全性配置已过期,但是用360安全浏览器或者微信的浏览器却没有这样的问题,然后我在CSDN里写文章也上传不了图片 |
| ANSWER:
我用edge访问没问题,可能是CSDN的某个CDN节点有问题吧,刷新下DNS再试,没准就能分配到正确的节点了 |
| LINK:https://ask.csdn.net/questions/7637480?answer=53678063 |

| SOURCE:CSDN_ASK |
| ASK_ID:7637384 |
| ANSWER_ID:53677968 |
| TITLE:rang和rows的区别 |
| ANSWER: range不是指的数据记录的范围,而是字段值的范围。
加上order by 后的输出结果是这样的
注意结果中id为4、num1为-3的行,由于等于“current row”的值有两行,因此求和的结果为-6 另外,你既然只是取当前行,何必写个开窗函数呢?如果你是想统计多行,用 “between 1 preceding and current row”这样的写法,也要注意rows和range的区别,当用rows时,"1 preceding"表示往前一行,当用range时,“1 preceding”表示当前值减1的结果对应的所有行。我这篇文章中对此有个举例说明 【ORACLE】21c版本中分析函数的加强(window、exclude、groups)_DarkAthena的博客-CSDN博客 前言在21c版本中,分析窗口得到了增强,支持了WINDOW子句,并且在窗口中增加支持EXCLUDE及GROUPS。以下以HR Schema Demo为例,可以在墨天轮在线实训环境进行验证Oracle 21c 实训环境1.window在21c之前,如果我们要对同一个窗口进行多次统计分析,一般是像下面这么写sqlselect EMPLOYEE_ID, FIRST_NAME, LAST_NAME, salary, sum(salary) ove https://darkathena.blog.csdn.net/article/details/122580517?spm=1001.2014.3001.5502 |
| LINK:https://ask.csdn.net/questions/7637384?answer=53677968 |


| SOURCE:CSDN_ASK |
| ASK_ID:7637347 |
| ANSWER_ID:53677880 |
| TITLE:having 能调用selectz中的别名吗 |
| ANSWER: 窗口函数只能存在于查询的字段中,不能作为数据过滤条件。 |
| LINK:https://ask.csdn.net/questions/7637347?answer=53677880 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637175 |
| ANSWER_ID:53677786 |
| TITLE:如何获取运单表中每类货物的最新5条运单 |
| ANSWER: 把 create table 命令发一下,另外说明一下使用的数据库版本 |
| LINK:https://ask.csdn.net/questions/7637175?answer=53677786 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637296 |
| ANSWER_ID:53677758 |
| TITLE:SQL View 如何引用存储过程内容 |
| ANSWER: 你这个其实就是一个拼接sql字符串,并执行的过程,“@sql”这个变量里就是放的要执行的sql,因此,如果要创建视图,只需要在这个sql前面再拼上一段" create view 视图名称 as "就好了,比如 |
| LINK:https://ask.csdn.net/questions/7637296?answer=53677758 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637215 |
| ANSWER_ID:53677749 |
| TITLE:You have an error in your SQL syntax; |
| ANSWER: 两个问题,
修改成下面这个样子后,创建成功,注意那玩意不是单引号,是你键盘左上角数字1左边的那个点
|
| LINK:https://ask.csdn.net/questions/7637215?answer=53677749 |

| SOURCE:CSDN_ASK |
| ASK_ID:7637224 |
| ANSWER_ID:53677744 |
| TITLE:vb.net 无法insert数据进去 |
| ANSWER: 你说无法insert数据进去,请问具体是报什么错? |
| LINK:https://ask.csdn.net/questions/7637224?answer=53677744 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637282 |
| ANSWER_ID:53677738 |
| TITLE:Mysql怎么将将分组聚合的查询结果写入另一个表 |
| ANSWER: 通用方法一般是用case when 来处理行列转换的问题 可惜mysql不支持pivot,否则也不用写得这么麻烦 |
| LINK:https://ask.csdn.net/questions/7637282?answer=53677738 |
| SOURCE:CSDN_ASK |
| ASK_ID:7637008 |
| ANSWER_ID:53677275 |
| TITLE:夹子拿出与放入都会记录一条数据,现在将数据进行合并 |
| ANSWER: 这里主要的问题是需要一个序号,以便能每2行一组进行合并,如果是mysql8.0版本,则可以用下面的方式
两个时间都在一行上了,你就可以去进行计算了 |
| LINK:https://ask.csdn.net/questions/7637008?answer=53677275 |

| SOURCE:CSDN_ASK |
| ASK_ID:7636981 |
| ANSWER_ID:53677228 |
| TITLE:csv文本按照特定格式转换成txt文本 |
| ANSWER: 你把命令改成这样试试 可能由于你原文本是DOS的,有回车加换行,awk只按换行识别行,结果就把回车给留下了,所以其实你也可以先把这个文本转成UNIX的再处理 |
| LINK:https://ask.csdn.net/questions/7636981?answer=53677228 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636989 |
| ANSWER_ID:53677225 |
| TITLE:python爬虫遇到的编码问题 |
| ANSWER: 从你的第一段内容是不可能解析出第3段的内容的. |
| LINK:https://ask.csdn.net/questions/7636989?answer=53677225 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636990 |
| ANSWER_ID:53677207 |
| TITLE:请问现在win11操作系统值得升级吗?(操作系统-windows) |
| ANSWER: 做任何事都是要有目的的,想好你升级是为了什么?目前win10并未放弃支持,一直还在提供补丁更新。 |
| LINK:https://ask.csdn.net/questions/7636990?answer=53677207 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636964 |
| ANSWER_ID:53677187 |
| TITLE:关于#mysql#的问题:需将表2的字段C在表1字段A进行模糊匹配,并将匹配出结果的数据在表1新字段B返回表2字段D的结果 |
| ANSWER: 举几行数据的例子看看,模糊匹配肯定是like,但是如果数据是有规则的,那么会有更高效的处理方式, |
| LINK:https://ask.csdn.net/questions/7636964?answer=53677187 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636758 |
| ANSWER_ID:53677182 |
| TITLE:oracle老是忘记commit,有没有timeout呀 |
| ANSWER: 建议规范开发代码,老老实实承认错误并改正错误,多写写就熟练了 |
| LINK:https://ask.csdn.net/questions/7636758?answer=53677182 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636789 |
| ANSWER_ID:53677180 |
| TITLE:hive中row_number() 中partition过多会导致报错么 |
| ANSWER: OOM是个综合性的问题。就算OOM也不会是由于你这个x单方面的影响,数据量、sql复杂度等都对此有影响,甚至这个与你硬件的配置、数据库的参数都有关系 |
| LINK:https://ask.csdn.net/questions/7636789?answer=53677180 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636821 |
| ANSWER_ID:53677173 |
| TITLE:sql的cast转换遇到null怎么办 |
| ANSWER: 用concat_ws函数 第一个参数是分隔符,直接传空字符串,后面几个参数就算有部分参数为空,结果也不会为空 GBase 8a多个字符串拼接一起的函数concat,concat_ws语法和用例 – 老紫竹的家 GBase 8a数据库集群提供了2种字符串拼接的方法,一个是双竖线的符号,另一个是concat函数和concat_ws指定分隔符的函数,本文介绍2种方法的使用。 https://www.gbase8.cn/2869 |
| LINK:https://ask.csdn.net/questions/7636821?answer=53677173 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636913 |
| ANSWER_ID:53677163 |
| TITLE:mysql存储过程在循环里写用字符串拼接的sql语句 |
| ANSWER: 你拼的这段sql少了空格,导致关键词都连到一起去了,所以提示语法错误 建议在执行动态sql前,先打印出你拼接好的sql字符串,确认无误后再加上执行此动态sql的命令 |
| LINK:https://ask.csdn.net/questions/7636913?answer=53677163 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636581 |
| ANSWER_ID:53676517 |
| TITLE:oracle null相关问题 |
| ANSWER: 你把那个b字段,用lengthb函数看一下字节长度为多少,是不是真的为空,可能只是你看不到而已,并不代表它就是null 【ORACLE】字符串处理小技巧之字符串不可见字符的识别与处理_DarkAthena的博客-CSDN博客 背景有些开发人员在做跨系统传输数据时,偶尔会遇到字符串中包含不可见字符的情况,导致无法在sql的where条件里精确检索这条数据,只能用like模糊查找,比如下面这个数据分析两行中,A列的值看上去是一样的,但是下面这条sql,却只能查出一条记录对比下字符串长度,发现长度不一致稍微有点经验的会说,这不就一个空格、回车或者换行嘛。但是当你用光标上下左右移动去数能移动几次时,发现的确只能数出来3个,多的那个字符是真的"不可见"!它既不是回车也不是换行!用trim函数也无法去除!这个时候,如果 https://darkathena.blog.csdn.net/article/details/122421264?spm=1001.2014.3001.5502 |
| LINK:https://ask.csdn.net/questions/7636581?answer=53676517 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636516 |
| ANSWER_ID:53676378 |
| TITLE:Oracle数据库,表里现在有七百万数据,现在再插入一万都插不进去是什么原因? |
| ANSWER: 查看下会话的等待事件是什么,如果存在锁表,就先解锁 |
| LINK:https://ask.csdn.net/questions/7636516?answer=53676378 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636493 |
| ANSWER_ID:53676326 |
| TITLE:之前写的一个python去直接写入MySQL的代码,之前用着还好好的,现在就不行了,这是哪出问题了? |
| ANSWER: 兄弟,你说不行,至少要说个咋的不行嘛,比如报什么错之类的 |
| LINK:https://ask.csdn.net/questions/7636493?answer=53676326 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636453 |
| ANSWER_ID:53676301 |
| TITLE:19年数据默认为0但是表里只有20年跟21年数据 |
| ANSWER: 如果是oracle可以用递归来构造一个完整的时间列;
或者
如果是mysql8.0以下,要么建个表存所有的时间,要么用union all把所有时间做成一个子查询 如果是mysql8.0以上,也可以使用递归来构造
|
| LINK:https://ask.csdn.net/questions/7636453?answer=53676301 |



| SOURCE:CSDN_ASK |
| ASK_ID:7636461 |
| ANSWER_ID:53676277 |
| TITLE:oracle正则表达式 清洗字符串,只留下数字 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7636461?answer=53676277 |

| SOURCE:CSDN_ASK |
| ASK_ID:7636364 |
| ANSWER_ID:53676048 |
| TITLE:成绩与总分数据对不上 |
| ANSWER: 永远不要写出 "select *,sum() from"这个样子的sql! 如果是老版本的话,则只能先算出每人的最高分,再根据姓名和最高分两个条件去匹配原表中的数据,当然,如果出现最高分同分的情况,你还得再给个规则取某一条 |
| LINK:https://ask.csdn.net/questions/7636364?answer=53676048 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635918 |
| ANSWER_ID:53675593 |
| TITLE:有無讓網誌寫的文章,在搜尋引擎(seo)前三頁的CSS呢? |
| ANSWER: 按重点关键词写SEO信息。
|
| LINK:https://ask.csdn.net/questions/7635918?answer=53675593 |

| SOURCE:CSDN_ASK |
| ASK_ID:7635994 |
| ANSWER_ID:53675582 |
| TITLE:bin文件转成图片格式 |
| ANSWER: 你发一个.bin文件过来看看,我分析下它实际是什么文件,“bin”不过是个后缀而已,不具有任何含义。 |
| LINK:https://ask.csdn.net/questions/7635994?answer=53675582 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636070 |
| ANSWER_ID:53675572 |
| TITLE:MySql统计库下面所有表的数据量 |
| ANSWER: 这个表的里的数据是静态的,不是实时的,需要执行统计信息收集后才会刷新。 |
| LINK:https://ask.csdn.net/questions/7636070?answer=53675572 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636045 |
| ANSWER_ID:53675553 |
| TITLE:java中登录界面改mysql数据 |
| ANSWER: 如果你想自行管理id这个字段的值,那么在建表的时候,不要把这个字段设为自增,就让它是个普通字段,这样你想怎么处理就怎么处理; |
| LINK:https://ask.csdn.net/questions/7636045?answer=53675553 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636072 |
| ANSWER_ID:53675552 |
| TITLE:Sql优化日期范围查询 |
| ANSWER: 你查询条件怎么写的?不会是把这个字段给to_date再去查的吧? 或者 注意,既然查询的字段是个字符串,那么查询条件的另一边也要是字符串,不能是数字类型 当然,楼上说的建函数索引也是一种方式,但是,一个日期里的数据太多的话,一般还是建议使用分区,而非索引 |
| LINK:https://ask.csdn.net/questions/7636072?answer=53675552 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636019 |
| ANSWER_ID:53675474 |
| TITLE:idea database 解析不了oracle 的blob 文本? |
| ANSWER: BLOB是二进制数据,要转换成CLOB类型才能显示文本信息 TO_CLOB (bfile|blob) https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/TO_CLOB-bfile-blob.html#GUID-FD7D58FE-B97C-4B75-85A9-5F82FB1DE96A
如果是11g及以前的版本,只能自建函数进行转换了 |
| LINK:https://ask.csdn.net/questions/7636019?answer=53675474 |
| SOURCE:CSDN_ASK |
| ASK_ID:7636046 |
| ANSWER_ID:53675465 |
| TITLE:oracle日期位数转换问题 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7636046?answer=53675465 |

| SOURCE:CSDN_ASK |
| ASK_ID:7636000 |
| ANSWER_ID:53675363 |
| TITLE:oracle 12c 服务器 sql语句执行结束 但是 sql 会话一直存在 |
| ANSWER: 你这个问题第6点就已经错了,对于第4点
这个只是你应用认为超时了,主动结束连接,而且并没有把结束指令发给数据库,数据库当然还是在执行这个sql |
| LINK:https://ask.csdn.net/questions/7636000?answer=53675363 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635980 |
| ANSWER_ID:53675357 |
| TITLE:分组统计相同项目不同范围统计 |
| ANSWER: 两个项目分别统计作为两个子查询,然后再用项目关联两个子查询. 这里要注意的是,可能会存在T1有但T2没有或者T2有但TI没有的项目,因此需要使用FULL JOIN ,否则你还需要另一个记录了完整项目的表作为主表,来左连接这两个子查询 |
| LINK:https://ask.csdn.net/questions/7635980?answer=53675357 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635993 |
| ANSWER_ID:53675341 |
| TITLE:我想要读取本地所有视频 |
| ANSWER: 有获取全盘文件访问权限么?没授权的情况下,应用的数据是不能互相访问的 |
| LINK:https://ask.csdn.net/questions/7635993?answer=53675341 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635941 |
| ANSWER_ID:53675283 |
| TITLE:PHP 和 mysql是怎么连接的 |
| ANSWER: php使用mysql客户端连接mysql服务端, |
| LINK:https://ask.csdn.net/questions/7635941?answer=53675283 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635669 |
| ANSWER_ID:53675178 |
| TITLE:oracle循环计算 |
| ANSWER: 楼上说得真详细哈,直接把题主没说清楚的场景进行了分类讨论。
如果是个报表,那么请提供你最终需要的报表格式,因为从题目上看,没有使用循环的必要 |
| LINK:https://ask.csdn.net/questions/7635669?answer=53675178 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635773 |
| ANSWER_ID:53675152 |
| TITLE:欧盟CSE心电数据库如何购买 |
| ANSWER: CSE(Common Standards for Electrocardiography)数据库由欧盟建立,包含了五个数据集。数据集1和2是三通道同时采集得到,数据集3、4和5是多通道采集得到(12导联ECG + 3导联VCG)。 数据集3和4一般用于波形测量的验证,即P波、QRS波和T波特征点的测量,包含125组10秒钟的静态心电数据。在心电图机性能要求YY 0782-2010中,数据集3中的100个数据用于验证算法在模拟真实人体采集情况下的波形测量准确性。 数据集5(也称诊断数据库)一般用于软件算法诊断结论的验证,包含1220个数据,类型包含了正常、心室肥大、心肌梗死等。该数据集由人工结合临床给出诊断结论,但不对外公开,如果需要验证算法的话,需要将自己算法的结论按CSE规定的方法映射为相应的编码,由CSE进行比对最后返回算法诊断的准确率等信息。 CSE数据库需要购买获得,其中数据集3和4价格1500美元,数据集5价格3500美元,购买数据集5后,CSE可免费进行算法诊断结论判断的验证(三次内免费,超过三次600美元一次)。如果是学校或是科研院所,以上的价格有一些优惠,具体可联系咨询。 CSE数据库可联系:prubel.lyon@gmail.com或Paul.Rubel@insa-lyon.fr获取相关的信息。 浅谈心电信号处理(2)--心电数据库_m0_48184290的博客-CSDN博客_心电数据库 所谓“工欲善其事,必先利其器“,我们在完成软件算法的设计后,必须通过数据进行验证,否则再好的算法也只能是空中楼阁,水中月镜中花。只有通过大量的数据验证后,才能说设计的算法是合格的,当然这并不是说算法一定是完美的,实际的应用中还可能碰到各种问题。究其原因,算法设计并不是一蹴而就,需要通过大量数据不断修正,最后才能达到理想的效果。 在实际的工作中,你和客户说你的产品算法有多好多好,都不如上几个图,几个表有说服力。通过公认的数据库进行算法测试,就是一个很好的手段。GE的产品为什么... https://blog.csdn.net/m0_48184290/article/details/106450918 |
| LINK:https://ask.csdn.net/questions/7635773?answer=53675152 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635806 |
| ANSWER_ID:53675143 |
| TITLE:求sql developer 4.2.0.17.089.1709 32位的官方安装包 |
| ANSWER: 免费注册一个账号即可下载 历史指定版本,可按照链接规则自行组装,虽然官网页面下架了,但是文件没有删 注意该链接无法直接下载,要使用迅雷等支持p2p的下载工具来进行下载
|
| LINK:https://ask.csdn.net/questions/7635806?answer=53675143 |

| SOURCE:CSDN_ASK |
| ASK_ID:7635839 |
| ANSWER_ID:53675128 |
| TITLE:只有一条简单的select * from tablea 这么一张表,但莫名报错 |
| ANSWER: 从这个报错上来看,与sql语句没有任何关系,因为这个错不是数据库报出来的,而是在应用连接到数据库的时候就已经失败了,根本就还没向数据库发送sql指令。 |
| LINK:https://ask.csdn.net/questions/7635839?answer=53675128 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635840 |
| ANSWER_ID:53675125 |
| TITLE:sql 多行合并为一行 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7635840?answer=53675125 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635875 |
| ANSWER_ID:53675123 |
| TITLE:同一列分段求最大值怎么求 |
| ANSWER: 数据库表里面的行,其实是没有顺序的,不存在什么第1行第2行,在不加order by的时候,每次去查同一个表,顺序是有可能会变化的。 |
| LINK:https://ask.csdn.net/questions/7635875?answer=53675123 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635442 |
| ANSWER_ID:53674721 |
| TITLE:mysql中不同环境下如果复制表 |
| ANSWER: 在同一个库里,从模式A下复制一张表的数据到模式B下,假设表名为test_table,并且模式B下已经创建好了这个表,那么在模式B下,执行 同理,如果模式B下没有建表,也可以使用下面的sql 当然前提是你登录的账号拥有这两个模式的权限 |
| LINK:https://ask.csdn.net/questions/7635442?answer=53674721 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635580 |
| ANSWER_ID:53674602 |
| TITLE:该怎么办啊?(标签-SQL |
| ANSWER: 你的学生表里有外键指向Grade表,使用的字段是GradeId,也就是说,你插入学生表的时候,对于GradeId这个字段的值,必须存在于Grade表中,否则禁止添加。 |
| LINK:https://ask.csdn.net/questions/7635580?answer=53674602 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635492 |
| ANSWER_ID:53674598 |
| TITLE:postgres 数据库 中想按照时间进行行转列 |
| ANSWER: 首先,数字开头的字符串是不能作为字段名的,而且“-”这个符号也不能包含在字段名内,因为可能会被认为是减号,因此目前无法实现你问题中要求的这个效果。 另外,官方文档中提供了一个crosstabN的用法,除了N为2/3/4以外,更多的列需要你自行定义一个type,在type中去定义有哪些字段以及字段类型,这样在查询的时候就不用去传那一串东西了 |
| LINK:https://ask.csdn.net/questions/7635492?answer=53674598 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635511 |
| ANSWER_ID:53674556 |
| TITLE:MySQL对所有字段进行sum,不是sum所有字段,是每个字段分别单独sum,不想一个一个写的 |
| ANSWER: 在sql标准中,一个select函数只能返回一列,你希望是一个函数能返回多列,这是不符合sql标准的。 |
| LINK:https://ask.csdn.net/questions/7635511?answer=53674556 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635474 |
| ANSWER_ID:53674431 |
| TITLE:Oracle连表1对多的关系 导致sql查询出来的数据 有其他列重复 如何 把重复列合并,这2个不一样数据的字段 拼在一列里呢 |
| ANSWER: 如果oracle版本是11g,可以用wm_concat或者listagg函数进行聚合,12c以上就只能用listagg函数了,注意其他不聚合的字段都要在最后 group by 【ORACLE】收集一些较为少见但很有用的SQL函数及写法.part1_DarkAthena的博客-CSDN博客 前言sql作为传统关系型数据一种常见语言,广泛使用在各种程序项目中。随着数据库厂商不断地更新迭代版本,sql的功能越来越丰富和强大,已经不局限于关系型查询,甚至对递归、数组、对象等都有支持。但是实际开发中,大多数开发人员对sql研究并不深,不清楚sql能支持到何种程度。虽然近几年网络上已经开始有一些技术分析文了,但总感觉受众还是不够广,所以我就开一个专题系列,分享一些sql的写法,主要针对oracle数据库,每篇根据复杂度大概介绍不超过10种,下面开始第一篇,先来点简单的1.cast作用:强制或者指 https://darkathena.blog.csdn.net/article/details/120598359 |
| LINK:https://ask.csdn.net/questions/7635474?answer=53674431 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635214 |
| ANSWER_ID:53674396 |
| TITLE:sql语句 某单位最早出现某规格的日期作为新列 |
| ANSWER: mysql 8.0以上支持开窗函数 |
| LINK:https://ask.csdn.net/questions/7635214?answer=53674396 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635275 |
| ANSWER_ID:53674387 |
| TITLE:这种联动的MYSQL语句怎么写? |
| ANSWER: 你这个不像是mysql的sql语句,sql长下面这样 你对照着你的语法改吧 |
| LINK:https://ask.csdn.net/questions/7635275?answer=53674387 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635279 |
| ANSWER_ID:53674379 |
| TITLE:把一个字段中的值改为其他值,并比较 |
| ANSWER: 请把原始数据表格长啥样,以及你最终想要的表格长啥样贴出来 |
| LINK:https://ask.csdn.net/questions/7635279?answer=53674379 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635291 |
| ANSWER_ID:53674373 |
| TITLE:怎么把文本文件里面的数据插入到数据库 |
| ANSWER: 你现在使用什么工具连接的mysql?如果是navicat或者dbeaver这样的图形化工具的话,都是支持从文本导入数据的,而且你这数据也不多,导入很快的。 |
| LINK:https://ask.csdn.net/questions/7635291?answer=53674373 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635383 |
| ANSWER_ID:53674328 |
| TITLE:用wpf做的一个类似管理系统,数据库内容改了,程序里的内容却没改,这是什么原因 |
| ANSWER: 你在数据库里进行的修改操作,是不是没有commit? |
| LINK:https://ask.csdn.net/questions/7635383?answer=53674328 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635172 |
| ANSWER_ID:53673720 |
| TITLE:如何把 mysql合并数据 并把重复的值更新再写入 |
| ANSWER: 你这问题太模糊了。。。 |
| LINK:https://ask.csdn.net/questions/7635172?answer=53673720 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635125 |
| ANSWER_ID:53673703 |
| TITLE:Ubuntu下安装的sqlite browser的图标显示的是齿轮,请问如何解决? |
| ANSWER: 因为它的图标就是长这个样子 |
| LINK:https://ask.csdn.net/questions/7635125?answer=53673703 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635073 |
| ANSWER_ID:53673702 |
| TITLE:sql中如何多查一列出来 |
| ANSWER: 你既然要查这个表里的多个字段,为什么不直接关联,非得写到字段的子查询里去? 当然前提是 plat.pf45这个表里的数据是全的,如果不全,改为左连接就行了 |
| LINK:https://ask.csdn.net/questions/7635073?answer=53673702 |
| SOURCE:CSDN_ASK |
| ASK_ID:7635013 |
| ANSWER_ID:53673699 |
| TITLE:请问现在程序员用的最多的浏览器是什么? |
| ANSWER: 其实,所谓的兼容性,主要是看浏览器内核,你说的EDGE和谷歌chrome这两个浏览器,其实内核都是开源的谷歌Chromium,在兼容性方面上几乎没有区别。 |
| LINK:https://ask.csdn.net/questions/7635013?answer=53673699 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634986 |
| ANSWER_ID:53673521 |
| TITLE:mysql8.0.27(最新版)安装过程中遇到的一些错误 |
ANSWER:
这是说数据目录不能用,让你删文件 |
| LINK:https://ask.csdn.net/questions/7634986?answer=53673521 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634987 |
| ANSWER_ID:53673517 |
| TITLE:把select的结果插入数据库 |
| ANSWER: 你既然是insert报错,那么就应该把insert命令发出来呀。 你都能用sql查出数据了,为什么不直接用查询sql去插,还导出成值再插? |
| LINK:https://ask.csdn.net/questions/7634987?answer=53673517 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634916 |
| ANSWER_ID:53673515 |
| TITLE:用python输出的csv文件格式不统一怎么回事呀 |
| ANSWER: csv本身是不带格式的纯文本文件,你这个显示效果是excel打开后自动处理的 |
| LINK:https://ask.csdn.net/questions/7634916?answer=53673515 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634968 |
| ANSWER_ID:53673512 |
| TITLE:关于计算两个日期之间的每个月天数的问题 |
| ANSWER: 你确定是用r语言?而不是用sql?? |
| LINK:https://ask.csdn.net/questions/7634968?answer=53673512 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634961 |
| ANSWER_ID:53673503 |
| TITLE:sql:最晚一个会议的时间(按当地时间(时区问题)推算,凌晨5:00前的最晚一个的时间,5点后算作新一天) |
| ANSWER: 最简单的,你直接把数据里的时间减掉5个小时,再去识别是哪一天不就好了? 然后你说的日期格式不一样,是因为你数据库里那个叫"UNIX_TIMESTAMP",转换一下就好了 如果是要把UNIX_TIMESTAMP转回成日期时间,用下面这个 注意位数,一般有10位数和13位数两种,你原数据是13位数就先除以1000再用 from_unixtime |
| LINK:https://ask.csdn.net/questions/7634961?answer=53673503 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634921 |
| ANSWER_ID:53673450 |
| TITLE:使用mysql命令导表失败 |
| ANSWER: 你第一张图,导出来那个东西,其实是告诉你这个命令调用的语法不对 注意参数赋值这里不是用的等号,而是个空格
|
| LINK:https://ask.csdn.net/questions/7634921?answer=53673450 |

| SOURCE:CSDN_ASK |
| ASK_ID:7634911 |
| ANSWER_ID:53673444 |
| TITLE:MySQL 时间条件筛选-今天之前7个月 |
ANSWER:或者 |
| LINK:https://ask.csdn.net/questions/7634911?answer=53673444 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634840 |
| ANSWER_ID:53673366 |
| TITLE:安装MongoDB出现问题 |
| ANSWER: 在安装程序上鼠标右键,以管理员方式运行 |
| LINK:https://ask.csdn.net/questions/7634840?answer=53673366 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634848 |
| ANSWER_ID:53673365 |
| TITLE:安装navicat 时出现以下截图问题 |
| ANSWER: 你这是打补丁,它提示你打了但又没完全打,先去用用程序,看看补丁是不是已经打上了,如果没打上,再来看看是不是哪个东西没改,对照教程再打一次 |
| LINK:https://ask.csdn.net/questions/7634848?answer=53673365 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634600 |
| ANSWER_ID:53673079 |
| TITLE:sql怎么改成中文啊 |
| ANSWER: 软件设置里是不能修改语言的。如果你是下载的所谓中文版,那么你下载的页面里一般会有教程教你怎么替换语言文件。 |
| LINK:https://ask.csdn.net/questions/7634600?answer=53673079 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634529 |
| ANSWER_ID:53672972 |
| TITLE:mysql 分区表,添加数据报错,99娃子吧 |
| ANSWER: 你看一下你分区表的定义, list columns 里面限定了哪些值放到哪个分区,然后你新插入的数据中对应字段的值,如果不在这个分区定义里面,就会报这个错 |
| LINK:https://ask.csdn.net/questions/7634529?answer=53672972 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634523 |
| ANSWER_ID:53672956 |
| TITLE:Navicat for Oracle 字段前后插入问题 |
| ANSWER: 这个其实与工具没有关系。 oracle 调整字段顺序_mxw976235955的专栏-CSDN博客_oracle调整字段顺序 不像mysql可以直接一条sql搞定(alter table 表名 change 字段名 新字段名 字段类型 默认值 after 字段名(跳到哪个字段之后)),oracle 必须另辟蹊径,曲线救国。 场景描述:假设我们有一张表名为test,该表有三个字段,依次为col1、col2、col3,现在我们想新增一个字段col4,并把col4放到最前面,即我们希望调整后的字段顺序为col4、col1、c https://blog.csdn.net/mxw976235955/article/details/75269138 |
| LINK:https://ask.csdn.net/questions/7634523?answer=53672956 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634344 |
| ANSWER_ID:53672951 |
| TITLE:如何取得工作管理員中處理程序的每支程式的CPU%值 |
| ANSWER: 图一中的应该是对一个程序的多个process进行的聚合,比如"LINE",图一左边显示有箭头,展开后,你会发现有多个Process,对应的就是你图二中的多条记录,需要对其进行求和。 但是如果有多层子进程的话,这个会比较麻烦,需要用到递归,比如查到CreatingProcessID=1924 的所有进程,假设有123和456两个IDProcess,则需要继续向下查CreatingProcessID in (123,456),就这么一直查下去,直到查不出数据,再对前面所有查到的进程进行统计。 sql server - How Do You Monitor The CPU Utilization of a Process Using PowerShell? - Stack Overflow https://stackoverflow.com/questions/11523150/how-do-you-monitor-the-cpu-utilization-of-a-process-using-powershell |
| LINK:https://ask.csdn.net/questions/7634344?answer=53672951 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634298 |
| ANSWER_ID:53672865 |
| TITLE:MySQL中的日期运算问题 |
| ANSWER: 情况一和情况二不一样的原因是,你没有把这几个或者条件用括号括起来,导致了它每一个条件都和and前面的变成了并列条件,正确的sql应该长这样 上下结果不一致,是因为你符号本就写得不一样,上面是大于1997年(不含1997年),下面是大于或者等于1997年 |
| LINK:https://ask.csdn.net/questions/7634298?answer=53672865 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634391 |
| ANSWER_ID:53672855 |
| TITLE:安装Oracle12c的时候出现了这个错误怎么解决 |
ANSWER:
你这是监听没配置好 |
| LINK:https://ask.csdn.net/questions/7634391?answer=53672855 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634387 |
| ANSWER_ID:53672851 |
| TITLE:oracle数据库亿级数据量中查询 |
| ANSWER: 只在查询上加速的话,目前看上去只能加个并行试试了 还有,可以让对方刷新一下这个表的统计信息。 |
| LINK:https://ask.csdn.net/questions/7634387?answer=53672851 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634353 |
| ANSWER_ID:53672844 |
| TITLE:在工厂内使用无线通讯模块,能否确保数据传输安全性、稳定性? |
| ANSWER: 无线通讯肯定不如有线通讯稳定,但是就算用有线,同样也可能存在掉包的情况。 |
| LINK:https://ask.csdn.net/questions/7634353?answer=53672844 |
| SOURCE:CSDN_ASK |
| ASK_ID:7634075 |
| ANSWER_ID:53672323 |
| TITLE:ora-02000 缺失always关键字怎么解决 |
| ANSWER: 你oracle是什么版本?你这个建表语句,我在21c上测试没有报错
CREATE TABLE https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/CREATE-TABLE.html#GUID-F9CE0CC3-13AE-4744-A43C-EAC7A71AAAB6 |
| LINK:https://ask.csdn.net/questions/7634075?answer=53672323 |

| SOURCE:CSDN_ASK |
| ASK_ID:7634021 |
| ANSWER_ID:53672201 |
| TITLE:各位靓仔我遇到一个问题,很困扰,茶饭不思,终日惶惶不得,难受难受 |
| ANSWER: 这么大个报错没看到么?
由于触发器执行失败,你这个事务都是执行不成功的,相当于你啥都没执行。 |
| LINK:https://ask.csdn.net/questions/7634021?answer=53672201 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633999 |
| ANSWER_ID:53672179 |
| TITLE:SQL中如何根据相同条件求和数量,并把数量更新到新列 |
| ANSWER: 先说是什么数据库?以及数据库的版本?如果是支持开窗函数的数据库的话,这个就很好写 |
| LINK:https://ask.csdn.net/questions/7633999?answer=53672179 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633985 |
| ANSWER_ID:53672143 |
| TITLE:ORACLE 截取函数,从右侧开始,往左侧截取如何写? |
| ANSWER: substr的第三个参数都是从第二个参数的位置从左往右数,因此你这个需求应该进行转化,截取的逻辑应该为从左起第一位,截到倒数第3位,即字符串总长度减2的长度
|
| LINK:https://ask.csdn.net/questions/7633985?answer=53672143 |

| SOURCE:CSDN_ASK |
| ASK_ID:7633977 |
| ANSWER_ID:53672130 |
| TITLE:orcal 存储过程 怎么用变量表示列值和判断 |
| ANSWER: 最简单的方式是用动态sql,把sql的字符串拼出来,再用execute immediate去执行这个SQL字符串。 |
| LINK:https://ask.csdn.net/questions/7633977?answer=53672130 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633930 |
| ANSWER_ID:53672057 |
| TITLE:如何让执行结果里不出现重复的数,请专家答疑解惑 |
| ANSWER: 整个查询结果中的所有数字,都不允许重复? |
| LINK:https://ask.csdn.net/questions/7633930?answer=53672057 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633907 |
| ANSWER_ID:53672046 |
| TITLE:如何使用分组聚合函数统计数据 |
| ANSWER: 你这逻辑明显不对嘛,你查的数据是dept_id为2和3的行(限定了长度等于3),但又想要统计其他行的数据。 如果是节点随机,那就得用递归sql(with RECURSIVE as )来处理了,但递归sql只有8.0版本以上才支持 |
| LINK:https://ask.csdn.net/questions/7633907?answer=53672046 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633808 |
| ANSWER_ID:53672008 |
| TITLE:PostgreSql的PROCEDURE在Java中如何调用?(问的是PROCEDURE而不是function,PostgreSql使用的是12) |
| ANSWER: java里调用postgresql的procedure这个问题,在以前的确有人讨论过,当时给出的解决方式是,把数据库里的这个procedure对象改成function对象,并在function的最后随便返回一个值就行了。 此文章中的方法的确可以正常调用procedure,但是他之前的报错和你的不一样,你的是提示没有找到该函数,他的报错提示这是一个过程。 |
| LINK:https://ask.csdn.net/questions/7633808?answer=53672008 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633825 |
| ANSWER_ID:53671979 |
| TITLE:Navicat for Oracle 如何快速回退回滚 |
| ANSWER: Oracle闪回技术详解 - dreamcatcher-cx - 博客园 概述: 闪回技术是Oracle强大数据库备份恢复机制的一部分,在数据库发生逻辑错误的时候,闪回技术能提供快速且最小损失的恢复(多数闪回功能都能在数据库联机状态下完成)。需要注意的是,闪回技术旨在快速恢 https://www.cnblogs.com/chengxiao/p/5860823.html |
| LINK:https://ask.csdn.net/questions/7633825?answer=53671979 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633850 |
| ANSWER_ID:53671975 |
| TITLE:pyhton操作数据库无法往表中插入数据 |
ANSWER:
这句翻译就是 ,无效的字段名 "零基础学py"。 在SQL里,双引号中间的代表字段名、表名等,单引号中间的代表字符串。 |
| LINK:https://ask.csdn.net/questions/7633850?answer=53671975 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633895 |
| ANSWER_ID:53671962 |
| TITLE:sql对词进行重复统计 |
| ANSWER: 试试这样 |
| LINK:https://ask.csdn.net/questions/7633895?answer=53671962 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633747 |
| ANSWER_ID:53671764 |
| TITLE:请问mysql查询多表时一个表没有对应数据怎么办 |
| ANSWER: 改动最小的
|
| LINK:https://ask.csdn.net/questions/7633747?answer=53671764 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633077 |
| ANSWER_ID:53671550 |
| TITLE:SQL SERVER 用多条件如何进行批量查询?请专家答疑解惑 |
| ANSWER: 没那么复杂,多个字段把它变成一个字段就是了 等下,我好像看漏了,你这查询条件是可以乱序的?想随机满足任意字段都行?这问题这太离谱了吧。。。究竟是怎样的程序需要这样来设计数据库呀?我太好奇了。。。 |
| LINK:https://ask.csdn.net/questions/7633077?answer=53671550 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633609 |
| ANSWER_ID:53671442 |
| TITLE:Python连接SQLSever |
| ANSWER: pymysql只能连mysql数据库,不能连接sqlserver数据库 |
| LINK:https://ask.csdn.net/questions/7633609?answer=53671442 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633601 |
| ANSWER_ID:53671441 |
| TITLE:mysql插入不重复的记录 |
| ANSWER: from DUAL是oracle的,mysql里不需要接这个东西,只需要select 对应的字段即可 。然后"NOT EXISTS"这个写法是标准sql,基本所有的关系型数据库都支持。 |
| LINK:https://ask.csdn.net/questions/7633601?answer=53671441 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633519 |
| ANSWER_ID:53671394 |
| TITLE:数据库多表联合查询时,一次sql join连接查询和多次单表查询哪个性能更高? |
| ANSWER: 你知道分两次查询再组合时,发生了一些什么吗? |
| LINK:https://ask.csdn.net/questions/7633519?answer=53671394 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633472 |
| ANSWER_ID:53671258 |
| TITLE:sql对查询出来的结果进行隐藏处理 |
| ANSWER: 最直白的方法当然就是上面说的用substr截,再拼星号。但这看上去不是太优雅哈,我给个正则的方式吧
|
| LINK:https://ask.csdn.net/questions/7633472?answer=53671258 |

| SOURCE:CSDN_ASK |
| ASK_ID:7633439 |
| ANSWER_ID:53671171 |
| TITLE:sql数据库,查询每个学生数学成绩时间最新的那一笔记录,求帮助! |
| ANSWER: SQL Server 2012 起,开始支持开窗函数, 但sqlserver2008不支持开窗函数,所以这个写起来会比较麻烦 |
| LINK:https://ask.csdn.net/questions/7633439?answer=53671171 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633389 |
| ANSWER_ID:53671148 |
| TITLE:创建表空间size和maxsize一样的值,又设置了自动增长 |
| ANSWER: 这里的maxsize是限制自动增长最多能增长到多少。像你这初始大小和最大大小一样了,那它当然不会再自动增长了。如果不手动调整大小的话,到了满了的时候就会报表空间不足了 |
| LINK:https://ask.csdn.net/questions/7633389?answer=53671148 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633388 |
| ANSWER_ID:53671113 |
| TITLE:编写程序查询Oracle数据库每个月最后一天的数据 |
| ANSWER: 如果你能够确保每个月末都有数据的话,用这个 如果是要按照数据里,按月分组取最后一条数据,比如10月最后一条是28号,没有31号的数据,用这个 或者 |
| LINK:https://ask.csdn.net/questions/7633388?answer=53671113 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633393 |
| ANSWER_ID:53671053 |
| TITLE:使用dapper,在mysql调用存储过程时,提示在数据库中找不到存储过程或函数 |
| ANSWER: 看下是不是用的同一个用户连接的同一个数据库 |
| LINK:https://ask.csdn.net/questions/7633393?answer=53671053 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633361 |
| ANSWER_ID:53671016 |
| TITLE:命令批量执行drop table |
| ANSWER: 可以在存储过程里执行动态sql,以oracle数据库为例 其他数据库也有类似的动态sql执行方式 |
| LINK:https://ask.csdn.net/questions/7633361?answer=53671016 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633140 |
| ANSWER_ID:53670939 |
| TITLE:SQL SERVER,两个表关联,在第一个条件关联不上的,就用第二个条件关联 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7633140?answer=53670939 |
| SOURCE:CSDN_ASK |
| ASK_ID:7633256 |
| ANSWER_ID:53670932 |
| TITLE:权限控制,每笔数据里面保存当前用户的ID,条件搜索只显示当前用户的数据 |
| ANSWER: 查询的sql里多加一个where条件,让表里面记录了用户ID的字段等于当前登录的用户ID |
| LINK:https://ask.csdn.net/questions/7633256?answer=53670932 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632962 |
| ANSWER_ID:53670409 |
| TITLE:什么是大数据索引技术? |
| ANSWER: 给你个关键词 "Elasticsearch",去了解它是个啥,然后怎么用,怎么优化,还要去了解它的同类 |
| LINK:https://ask.csdn.net/questions/7632962?answer=53670409 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632991 |
| ANSWER_ID:53670383 |
| TITLE:ORACLE条件判断相关问题 |
| ANSWER: 按你这个思路,会涉及到一个分摊问题,把问题搞复杂了,因为你这个表里面没有唯一键,无法排序,不能确定哪一行发生在前哪一行发生在后;就算有个时间排序,假设第三行和第四行数据一样,都可以作为临界线,这样随便挑一行出来都能作为超标,那样强行按顺序分摊没有任何意义。 |
| LINK:https://ask.csdn.net/questions/7632991?answer=53670383 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632945 |
| ANSWER_ID:53670335 |
| TITLE:触发器里的update偶尔不成功 |
| ANSWER: 一、监视不了有很多种方式可以绕过去。
二、查问题的话,从你这个sql里看,如果INVT这个表里本就没有记录,当然更新是更新不到的;还有如果where条件里的6个值,有任何一个值为空,也是查不到的,再就是你更新的值,如果有某个值为空,做四则运算的结果也是会为空。 三、另外,如果数据很难跟踪的话,你完全可以再加个日志表,每插一笔,就把用到的这些值都记录到日志表里去,当你发现数据对不上的时候,回头去查日志表,是不是有数据为空的情况。 |
| LINK:https://ask.csdn.net/questions/7632945?answer=53670335 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632939 |
| ANSWER_ID:53670325 |
| TITLE:有个sql语句想分子分母相除的结果,请教下如何写呢? |
| ANSWER: 楼上这个答案有点敷衍。。。 |
| LINK:https://ask.csdn.net/questions/7632939?answer=53670325 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632775 |
| ANSWER_ID:53670128 |
| TITLE:企业微信后台怎么查看配置了回调域名呢?? |
| ANSWER: 应用管理,点击你的自建应用,设置可信域名
|
| LINK:https://ask.csdn.net/questions/7632775?answer=53670128 |

| SOURCE:CSDN_ASK |
| ASK_ID:7632800 |
| ANSWER_ID:53670046 |
| TITLE:SSRS 水晶报表项目如何实现以下效果,存储过程为两条数据,在报表上只体现为一行。 |
| ANSWER: 这个在sql查询层面上就可以解决呀,用case when或者用pivot都行 |
| LINK:https://ask.csdn.net/questions/7632800?answer=53670046 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632802 |
| ANSWER_ID:53670043 |
| TITLE:数据库运行时候出现代码后闪退 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7632802?answer=53670043 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632756 |
| ANSWER_ID:53670039 |
| TITLE:【SQL】怎么在对已分组数据进行总合计并在列中展示 |
| ANSWER: 这典型的要用开窗函数呀 |
| LINK:https://ask.csdn.net/questions/7632756?answer=53670039 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632714 |
| ANSWER_ID:53670028 |
| TITLE:关于行列转置,求一个简单的方法,sql或者excel都行 |
| ANSWER: 首先,日期不能作为字段名,我假设你1号是A1,2号是A2,以此类推。 实测截图
|
| LINK:https://ask.csdn.net/questions/7632714?answer=53670028 |

| SOURCE:CSDN_ASK |
| ASK_ID:7632566 |
| ANSWER_ID:53669999 |
| TITLE:case when 语句 为什么第一句无论正确与否 都会跟随第二语句判断 |
| ANSWER: 这sql让人血压升高。。。case when 哪有你这样用的,我按你这个逻辑改了下 你可以先把中间这个子查询弄出来,看看有没有数据 稍微改了下,以后测试数据请提供建表sql及insert语句,要不然回答问题的人还得替你去造数据测试sql |
| LINK:https://ask.csdn.net/questions/7632566?answer=53669999 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632666 |
| ANSWER_ID:53669969 |
| TITLE:oracle sum()over()问题 |
| ANSWER: 这个问题其实很简单,在你分析函数中的order by 后面,再接一个每一行都有不同值的列就是了,比如员工id,甚至直接用个rownum也行, 你这个是想对分组窗口的每一行,累计从第一行到当前行的值,但是你这个排序却没有进行绝对的排序,只根据deptno 和sal排序 ,可能每次排序的结果都会不一样。 另外,其实还有更加精准的统计分组窗口的第一行到当前行的方式 【ORACLE】21c版本中分析函数的加强(window、exclude、groups)_DarkAthena的博客-CSDN博客 前言在21c版本中,分析窗口得到了增强,支持了WINDOW子句,并且在窗口中增加支持EXCLUDE及GROUPS。以下以HR Schema Demo为例,可以在墨天轮在线实训环境进行验证Oracle 21c 实训环境1.window在21c之前,如果我们要对同一个窗口进行多次统计分析,一般是像下面这么写sqlselect EMPLOYEE_ID, FIRST_NAME, LAST_NAME, salary, sum(salary) ove https://darkathena.blog.csdn.net/article/details/122580517 |
| LINK:https://ask.csdn.net/questions/7632666?answer=53669969 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632670 |
| ANSWER_ID:53669932 |
| TITLE:mysql utf8中文排序 |
| ANSWER: mysql8.0支持函数索引 |
| LINK:https://ask.csdn.net/questions/7632670?answer=53669932 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632730 |
| ANSWER_ID:53669921 |
| TITLE:python读写大型csv速度太慢应该如何解决? |
| ANSWER: 建议导入到数据库中再进行处理 |
| LINK:https://ask.csdn.net/questions/7632730?answer=53669921 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632479 |
| ANSWER_ID:53669458 |
| TITLE:关于#c##的问题:在运行下面这一串代码时,不管row[0]中的数据和combobox1里的数据相等还是不相等,j1都是为false |
| ANSWER: 你有没有尝试过,在这段代码里面,把 row2[0].ToString().Trim() 和comboBox1.Text.ToString().Trim() 打印出来,看看实际取到的值是个啥? |
| LINK:https://ask.csdn.net/questions/7632479?answer=53669458 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632450 |
| ANSWER_ID:53669448 |
| TITLE:SQL server语句went |
| ANSWER: 返回的那个值表示受影响的行数,你插入一列当然是影响一行,返回的是1 SqlCommand.ExecuteNonQuery 方法 (System.Data.SqlClient) | Microsoft Docs 对连接执行 Transact-SQL 语句并返回受影响的行数。Executes a Transact-SQL statement against the connection and returns the number of rows affected. https://docs.microsoft.com/zh-cn/dotnet/api/system.data.sqlclient.sqlcommand.executenonquery?view=dotnet-plat-ext-6.0 |
| LINK:https://ask.csdn.net/questions/7632450?answer=53669448 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632437 |
| ANSWER_ID:53669446 |
| TITLE:spark sql数据如何求交集? |
| ANSWER: spark sql中可以使用except来获得两组数据的交集 你如果是某一行中的某一列是个数组,把它展开成多行后再用上面这个方法一样可以得出交集,即explode +except +collect_list 当然,也可以直接用数组函数得到交集
参考 |
| LINK:https://ask.csdn.net/questions/7632437?answer=53669446 |

| SOURCE:CSDN_ASK |
| ASK_ID:7632420 |
| ANSWER_ID:53669438 |
| TITLE:SQL server语句问题 |
| ANSWER: 基本概念要搞清楚,对于某一行记录中的某些字段进行变更,那叫更新,不叫插入,插入都是指的插入行。 查 更新 |
| LINK:https://ask.csdn.net/questions/7632420?answer=53669438 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632414 |
| ANSWER_ID:53669437 |
| TITLE:oracle left join子查询外加group by报错 |
| ANSWER: INFO_T 和PARAM_T 是表还是视图?这两个东西单独查会不会报错? |
| LINK:https://ask.csdn.net/questions/7632414?answer=53669437 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632401 |
| ANSWER_ID:53669435 |
| TITLE:请问是什么问题 为什么附加不了 之前还可以 |
| ANSWER: 你确定这个路径下有mdf文件? |
| LINK:https://ask.csdn.net/questions/7632401?answer=53669435 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632389 |
| ANSWER_ID:53669433 |
| TITLE:安装MySQL时在lnitializing database出错。 |
| ANSWER: 这个日志说,你可能碰到了个bug
|
| LINK:https://ask.csdn.net/questions/7632389?answer=53669433 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632360 |
| ANSWER_ID:53669429 |
| TITLE:关于数据库编码的提问 |
| ANSWER: 从前端到后端到数据库,要求全部统一字符集,要么全gbk,要么全utf8 |
| LINK:https://ask.csdn.net/questions/7632360?answer=53669429 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632336 |
| ANSWER_ID:53669427 |
| TITLE:通过设置变量实现将表中每个身份证号及身份证号重复数罗列出来,你有更好的办法吗? |
| ANSWER: 为什么要用变量?直接count不就出来了? 如果要去掉没重复的 |
| LINK:https://ask.csdn.net/questions/7632336?answer=53669427 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632313 |
| ANSWER_ID:53669421 |
| TITLE:navicate15无法打开postgresql中表的对象信息,且经常报错unknown function:pg_get_ruledef()是什么原因呢 |
| ANSWER: pg_get_ruledef这个函数是postgresql中都自带的一个函数,用于获取
参考 http://postgres.cn/docs/14/functions-info.html 很明显,navicat针对postgresql来查看ddl时,调用了这个函数。 而你点击ddl,却报了错,这说明navicat没找到这个函数,请尝试切换管理员用户再试,另外请检查数据库安装的完整性, |
| LINK:https://ask.csdn.net/questions/7632313?answer=53669421 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632236 |
| ANSWER_ID:53669204 |
| TITLE:sql中用max取温度字段的最大值和最小值,结果发现最大值9度,而最小值10度 |
| ANSWER: 按字符串比较的话,是从左至右去比较,9当然比1大。 上面专家说的int类型肯定是不行的,温度当然会有小数。 |
| LINK:https://ask.csdn.net/questions/7632236?answer=53669204 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632220 |
| ANSWER_ID:53669196 |
| TITLE:像计算累加占比前80%的产品 应该怎么添加语句 |
| ANSWER: MYSQL8.0以上版本,使用开窗函数中的CUME_DIST,返回累计占比 而且你这题和上一题都犯了个毛病,明明查询结果中不需要客户信息,产品明细和销量明细也不需要通过客户信息关联,为什么非得把客户明细带上去啊 为什么要加到你那个语句里去啊?你不是要查累计占比前80%的产品么,这个sql查出来就是了,如果你要同时显示单个占比,多查一个字段就好了 |
| LINK:https://ask.csdn.net/questions/7632220?answer=53669196 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632196 |
| ANSWER_ID:53669045 |
| TITLE:java解析excel |
| ANSWER: 130是指的字符个数,不是字节个数,一个汉字在GBK字符集里占两个字节,在UTF8字符集里占三个字节,因此你这个字符串的总长度会超过字符个数,你只能去把这个字段加长了
根据我这个测试,你这字符集是GBK吧 |
| LINK:https://ask.csdn.net/questions/7632196?answer=53669045 |

| SOURCE:CSDN_ASK |
| ASK_ID:7632057 |
| ANSWER_ID:53668965 |
| TITLE:请教,帮我看看为什么sql在分组的时候会报错 |
| ANSWER: 你先把totalmoney这一个列注释掉试试, |
| LINK:https://ask.csdn.net/questions/7632057?answer=53668965 |
| SOURCE:CSDN_ASK |
| ASK_ID:7632100 |
| ANSWER_ID:53668930 |
| TITLE:请问一下 我想求取单个金额占比总额大于10%的产品名称,该怎么写SQL呢 |
| ANSWER: 是什么类型的数据库?数据库版本是多少?并请提供表结构,你这SQL明显有问题,没有group by ,也没使用开窗函数,也没使用子查询,这样是算不了占比的。占比先要算出个单独的汇总值 至于要过滤出10%的,再包一层写个where条件就行了 |
| LINK:https://ask.csdn.net/questions/7632100?answer=53668930 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631793 |
| ANSWER_ID:53668503 |
| TITLE:sql语句怎么将求和查询结果横向连接 |
| ANSWER: 楼上专家的right join 有问题,这些月份中,并不能确定哪个月份的类型是全的,所以应该使用full join mysql 的话,可以通过 left join ...union ... right join 来实现full join 的效果。 |
| LINK:https://ask.csdn.net/questions/7631793?answer=53668503 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631851 |
| ANSWER_ID:53668499 |
| TITLE:mysql根据出生日期计算年龄并且插入到已有记录中 |
| ANSWER: 这种数据库的插入一般都是指的插入行,就算只指定一个字段,它也是插入一整行,没有指定的字段就全为空。 |
| LINK:https://ask.csdn.net/questions/7631851?answer=53668499 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631861 |
| ANSWER_ID:53668496 |
| TITLE:SQL sever 多条件计数问题? |
| ANSWER: 问这种sql问题时,请提供建表sql及测试数据sql,方便回答者进行测试,要不然就会像上面专家那样写了个语法都不对的sql(中间少了where) |
| LINK:https://ask.csdn.net/questions/7631861?answer=53668496 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631901 |
| ANSWER_ID:53668494 |
| TITLE:执行systemctl enable mysqld报错:Failed to enable unit: Unit file mysqld.service does not exist. |
| ANSWER: mysql没安装或者没装好,启动当然会提示不存在了 |
| LINK:https://ask.csdn.net/questions/7631901?answer=53668494 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631911 |
| ANSWER_ID:53668493 |
| TITLE:mysql赋值报错,可以解释一下吗 |
| ANSWER: 你是不是在哪里复制了不完整的代码 |
| LINK:https://ask.csdn.net/questions/7631911?answer=53668493 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631567 |
| ANSWER_ID:53668361 |
| TITLE:mac m1 怎么安装red hat8 |
| ANSWER: 你下载系统镜像文件的时候,注意选择带"ARM"(或者"aarch")标识的版本进行下载,不要下带"x86"的 |
| LINK:https://ask.csdn.net/questions/7631567?answer=53668361 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631455 |
| ANSWER_ID:53668152 |
| TITLE:Oracle 存储过程如何实现对表的更新 |
| ANSWER: 用基于日志的物化视图就好了,可以实现针对变化数据的快速刷新。 如果原表上没有可以用于增量识别的字段,比如单进程产生的序号、单进程产生的时间戳等(存在多进程同时更新数据时,无法准确捕获增量),光用存储过程是无法识别到数据变化的情况的。必须在变更表数据的时候有所记录。而且创建物化视图,你也可以让他不自动更新,而是让存储过程去执行刷新。何必非纠结于用什么方式呢?其实创建触发器记录日志,然后使用存储过程去读取日志来进行更新处理,这也是个方法。反正一点,无论使用什么方式,重点就是看有没有增量标识。 |
| LINK:https://ask.csdn.net/questions/7631455?answer=53668152 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631476 |
| ANSWER_ID:53668142 |
| TITLE:mysql中不建立放假时间表的情况下使用sql查询两个日期之间的小时数并剔除其中的周六周日 |
| ANSWER: 这个可以实现的,而且不是很复杂,用递归sql生成传入两个日期间的每一天,然后对星期六和星期日的天数进行统计,并从总天数里减去这个数,最后再乘以24小时即可。
|
| LINK:https://ask.csdn.net/questions/7631476?answer=53668142 |

| SOURCE:CSDN_ASK |
| ASK_ID:7631498 |
| ANSWER_ID:53668123 |
| TITLE:什么是触发器。入库,和出库操作是不是用到了触发器功能,如果没有用的话,请问用什么方式可以实现。 |
| ANSWER: 触发器是当你执行某个命令时,系统自动连带执行的另一个或一组命令所构成的一个程序过程。触发器只是为了让程序代码更简单的一种方式,不用触发器一样可以实现同样的逻辑,就是相同的代码要写得到处都是了。 |
| LINK:https://ask.csdn.net/questions/7631498?answer=53668123 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631491 |
| ANSWER_ID:53668097 |
| TITLE:oracle数据库修改某列值值中部分值前缀语句 |
| ANSWER: 你这个不就是个简单的字符串拼接么?直接管道符拼一下就完事了,没看明白你问题难点在哪 |
| LINK:https://ask.csdn.net/questions/7631491?answer=53668097 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631165 |
| ANSWER_ID:53667583 |
| TITLE:mysql非等值连接,为什么所有结果重复出现了一遍 |
| ANSWER: 麻烦你把你的建表sql、数据生成sql,以及你执行的查询sql发出来,你就这么一张图,没人能查问题的 |
| LINK:https://ask.csdn.net/questions/7631165?answer=53667583 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631284 |
| ANSWER_ID:53667580 |
| TITLE:Ubuntu下的Navicat |
| ANSWER: 因为你系统里少了对应的组件,安装一下就行了 |
| LINK:https://ask.csdn.net/questions/7631284?answer=53667580 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631224 |
| ANSWER_ID:53667578 |
| TITLE:mysql无法插入数据 mac |
| ANSWER: 你这是改了字符集是吧? |
| LINK:https://ask.csdn.net/questions/7631224?answer=53667578 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631278 |
| ANSWER_ID:53667574 |
| TITLE:关于#mysql#的问题,如何解决? |
| ANSWER: "每天的入住状态"、"指定期间内" |
| LINK:https://ask.csdn.net/questions/7631278?answer=53667574 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631377 |
| ANSWER_ID:53667563 |
| TITLE:如果实现 部分行标签 转置为列名 |
| ANSWER: 最简单的方式,你最后这个sql稍微改下 |
| LINK:https://ask.csdn.net/questions/7631377?answer=53667563 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631245 |
| ANSWER_ID:53667429 |
| TITLE:汇总不同工作簿中的数据列表 |
| ANSWER: 请提供相关截图及代码,你这问题描述完全看不懂你在用什么工具操作什么东西 |
| LINK:https://ask.csdn.net/questions/7631245?answer=53667429 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631186 |
| ANSWER_ID:53667356 |
| TITLE:sql查询能否固定行数,无结果显示空 |
| ANSWER: 你没说数据库类型和版本,我以oracle举例
这个开窗函数,有一部分数据库是不支持的。 |
| LINK:https://ask.csdn.net/questions/7631186?answer=53667356 |

| SOURCE:CSDN_ASK |
| ASK_ID:7631164 |
| ANSWER_ID:53667330 |
| TITLE:这行代码换成for循环是怎么实现的呀 |
| ANSWER: 直接换成for循环应该是这样的, 可以和你之前的代码对应 ,"[0] * n"是每次循环里要执行的,"for i in range(n)"是表示要循环执行多少次 |
| LINK:https://ask.csdn.net/questions/7631164?answer=53667330 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631166 |
| ANSWER_ID:53667324 |
| TITLE:Python用的vscode,但是一直提示找不到文件 |
| ANSWER: 你这个截图里没有任何报错呀,这个py也正常执行了,打印了5 |
| LINK:https://ask.csdn.net/questions/7631166?answer=53667324 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631132 |
| ANSWER_ID:53667319 |
| TITLE:不知道如何理解该问题,请解答 |
| ANSWER: 这个题目描述已经很清晰了, |
| LINK:https://ask.csdn.net/questions/7631132?answer=53667319 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631119 |
| ANSWER_ID:53667262 |
| TITLE:springboot + JDBC 我想从数据库拿到我想要的值。我已经可以拿到全部值了,但是我只想获得其中的userpwd |
| ANSWER: 你直接登录进去数据库去查,会发现密码就是这个东西。 |
| LINK:https://ask.csdn.net/questions/7631119?answer=53667262 |
| SOURCE:CSDN_ASK |
| ASK_ID:7631106 |
| ANSWER_ID:53667261 |
| TITLE:Oracle数据库中怎么赋予一个用户创建另一个用户下表的权限 |
| ANSWER: oracle没有提供这种授权方式,但是有两个方法可以实现类似的效果,假设是A用户要在B用户下建表
grant create tables in another schema — oracle-mosc Hi,I have a driver schema that need to be able to create a table and a package in another schema.  https://community.oracle.com/mosc/discussion/3187729/grant-create-tables-in-another-schema |
| LINK:https://ask.csdn.net/questions/7631106?answer=53667261 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630960 |
| ANSWER_ID:53667031 |
| TITLE:按照执行顺序聚合函数和窗口函数都在group by 后面为什么 不能在 GROUP BY子句中使用窗口函数可以使用聚合函数 |
| ANSWER: 这与sql解析执行顺序有关, |
| LINK:https://ask.csdn.net/questions/7630960?answer=53667031 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630938 |
| ANSWER_ID:53667021 |
| TITLE:python字典中关于键和值? |
| ANSWER: 你取这个列表的第一个值就好了
|
| LINK:https://ask.csdn.net/questions/7630938?answer=53667021 |

| SOURCE:CSDN_ASK |
| ASK_ID:7630941 |
| ANSWER_ID:53667017 |
| TITLE:centos7 为什么进不到安装文件目录(语言-python) |
| ANSWER: 由于文件目录带空格,linux会以为后面的是参数,请使用英文的双引号把整个路径引起来 |
| LINK:https://ask.csdn.net/questions/7630941?answer=53667017 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630942 |
| ANSWER_ID:53667008 |
| TITLE:为什么x=(y=z+1)是非法语句? |
| ANSWER: 哪有这么写的。。。 |
| LINK:https://ask.csdn.net/questions/7630942?answer=53667008 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630946 |
| ANSWER_ID:53667004 |
| TITLE:Kali和vmware tools |
| ANSWER: 这个报错已经告诉你要怎么做了
"请使用超级管理员重新运行" 其实就是在root下运行,或者前面加sudo运行 |
| LINK:https://ask.csdn.net/questions/7630946?answer=53667004 |

| SOURCE:CSDN_ASK |
| ASK_ID:7630921 |
| ANSWER_ID:53666975 |
| TITLE:python把图片中的字符转换成可编译的文件 |
| ANSWER: 在图片中识别字符的这项技术叫OCR,支持这项技术的有很多软件,而且还有不少API服务支持解析。 |
| LINK:https://ask.csdn.net/questions/7630921?answer=53666975 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630934 |
| ANSWER_ID:53666966 |
| TITLE:复杂代码至Python |
| ANSWER: 外面复制好,到idle里鼠标右键粘贴 |
| LINK:https://ask.csdn.net/questions/7630934?answer=53666966 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630897 |
| ANSWER_ID:53666958 |
| TITLE:VBA 使用”adodb“在SQL数据库中查询数据问题 |
| ANSWER: 你可以取这个数据的行数,然后去判断这个行数是否等于0,如果等于0,则弹窗确认,确认里直接退出正在运行的代码 |
| LINK:https://ask.csdn.net/questions/7630897?answer=53666958 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630788 |
| ANSWER_ID:53666921 |
| TITLE:可以讲一下这个怎么解决吗? |
| ANSWER: 你点报错提示的这个链接进去,他会告诉你有两个方案,而且网页下面有具体要怎么操作
推荐使用方案一 |
| LINK:https://ask.csdn.net/questions/7630788?answer=53666921 |


| SOURCE:CSDN_ASK |
| ASK_ID:7630791 |
| ANSWER_ID:53666917 |
| TITLE:vmware15 启动虚拟机电脑自动重启 |
| ANSWER: 这说明你电脑已经有问题了,但目前无法确定是硬件问题还是操作系统的问题,得分析电脑的日志 |
| LINK:https://ask.csdn.net/questions/7630791?answer=53666917 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630828 |
| ANSWER_ID:53666916 |
| TITLE:docker进入mongo容器报错 |
| ANSWER: 此容器当前处于restarting(重启中),当然不能进去,下面这句英文已经告诉你原因了,让你等到容器处于running(运行)状态。 |
| LINK:https://ask.csdn.net/questions/7630828?answer=53666916 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630780 |
| ANSWER_ID:53666842 |
| TITLE:sql语句在sqlserver执行1秒,在应用程序执行慢几十秒 |
| ANSWER: 你说在应用程序里需要10秒,是怎么计的时?从查询到数据展示到页面上? |
| LINK:https://ask.csdn.net/questions/7630780?answer=53666842 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630723 |
| ANSWER_ID:53666836 |
| TITLE:hive sql 填充数据的问题 |
| ANSWER: 建议在excel里提前处理好。处理方法为
不在HIVE里做的原因是,你这个表里面没有排序id,无法定位上一行和下一行,如果有id的话,倒是可以通过开窗函数中的lag来查询上一个值 |
| LINK:https://ask.csdn.net/questions/7630723?answer=53666836 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630658 |
| ANSWER_ID:53666701 |
| TITLE:dbeaver查看视图 |
| ANSWER: 你想怎么编辑视图?navicat里也没有可视化的编辑视图的方式,点设计视图进去就一个创建视图的sql而已。在dbeaver里一样也是鼠标右键视图
|
| LINK:https://ask.csdn.net/questions/7630658?answer=53666701 |

| SOURCE:CSDN_ASK |
| ASK_ID:7630604 |
| ANSWER_ID:53666687 |
| TITLE:虚拟机Hadoop出现了问题打开不了了 |
| ANSWER: 中间那句英文的意思是 请你尝试重装virtualbox |
| LINK:https://ask.csdn.net/questions/7630604?answer=53666687 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630628 |
| ANSWER_ID:53666681 |
| TITLE:未安装oracle数据库的Linux服务器运行Python程序,远程连接另一台服务器上的oracle库,出现cx_Oracle.DatabaseError: DPI-1047,如何解决 |
| ANSWER: 你用cx_Oracle,必须要配置oracle客户端环境(注意这不是数据库环境),去官网下载一个吧,这个包不大 Oracle Instant Client Downloads | Oracle 中国  https://www.oracle.com/cn/database/technologies/instant-client/downloads.html |
| LINK:https://ask.csdn.net/questions/7630628?answer=53666681 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630667 |
| ANSWER_ID:53666670 |
| TITLE:hive sql 行列转置问题 |
| ANSWER: 右边的6个列每2个列一组,加一个静态的职位字段,一共三个列,用union all拼接起来,再用字符串聚合把职位拼起来。这个方法应该是可用的。 弄出来了 实测截图
|
| LINK:https://ask.csdn.net/questions/7630667?answer=53666670 |

| SOURCE:CSDN_ASK |
| ASK_ID:7630683 |
| ANSWER_ID:53666662 |
| TITLE:非数据库字段随数据一起导出 |
| ANSWER: 什么数据库?什么开发语言?你排序是用的什么方式?这些都不说怎么回答?既然要序号,直接sql查询里写个序号字段不就好了? |
| LINK:https://ask.csdn.net/questions/7630683?answer=53666662 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630685 |
| ANSWER_ID:53666661 |
| TITLE:将两个金额相除取百分比报错 |
| ANSWER: 建议你把完整的sql打印出来,不一定就是这一段的问题 |
| LINK:https://ask.csdn.net/questions/7630685?answer=53666661 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630295 |
| ANSWER_ID:53666431 |
| TITLE:这个代码到底哪里不对啊 |
| ANSWER: sql没截全,大概率是这里表关联条件写少了 你这4个表,才两个where条件,相当于分成了两组毫不相关的查询,sc和tc一组,course和room一组,其中一组关联的结果有5行,另一组一行,5乘以1得你最后输出的就是5行。至少要有第3个关联条件把你分开关联的这两组表关联起来 |
| LINK:https://ask.csdn.net/questions/7630295?answer=53666431 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630279 |
| ANSWER_ID:53666363 |
| TITLE:Oracle如何实现字段加密后长度小于或等于原始数据长度? |
| ANSWER: 你原始数据长度为多少?如果原始数据很长的话,可以使用utl_compress压缩一次,然后用DBMS_CRYPTO加密,再转base64。 |
| LINK:https://ask.csdn.net/questions/7630279?answer=53666363 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630247 |
| ANSWER_ID:53666156 |
| TITLE:求一个php中pdo连接数据库中charset的问题 |
| ANSWER: MySQL字符集 GBK、GB2312、UTF8区别 解决 MYSQL中文乱码问题以及error 1406:data too long for column 'name' at row 1_zsm653983的专栏-CSDN博客_gbk字符集与gb2312字符集不兼容对吗 MySQL中涉及的几个字符集 character-set-server/default-character-set:服务器字符集,默认情况下所采用的。character-set-database:数据库字符集。character-set-table:数据库表字符集。优先级依次增加。所以一般情况下只需要设置character-set-server,而在创建数据库和表时不特别指定字符集 https://blog.csdn.net/zsm653983/article/details/7970179 既然你是作为客户端来连接,那么影响的字符集自然就有客户端和连接的字符集了 |
| LINK:https://ask.csdn.net/questions/7630247?answer=53666156 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630246 |
| ANSWER_ID:53666144 |
| TITLE:excel怎么批量计算不同名称很多公式的和 |
| ANSWER: 贴个样表吧,你这问题描述不是很清楚 |
| LINK:https://ask.csdn.net/questions/7630246?answer=53666144 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629909 |
| ANSWER_ID:53666131 |
| TITLE:mysql导入几亿数据磁盘IO读写过大? |
| ANSWER: 把主键索引删了再导。 |
| LINK:https://ask.csdn.net/questions/7629909?answer=53666131 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629936 |
| ANSWER_ID:53666126 |
| TITLE:请问一下ORACLE如果A列的值是相同的,但B列的值是不同的数据行中,怎么优先取B列指定的值 |
| ANSWER: 题主这ABC只是举例,实际应该存在不同值,且无法直接用最大或者最小排序。 或者 然后使用fetch first 1 row only 取第一行即可,如果是12c以下的版本,就用开窗函数来排序再取排序为第一的 同理,使用decode或者case when 以后,就可以使用max/min来获取对应的值了,只是还得转换回去 |
| LINK:https://ask.csdn.net/questions/7629936?answer=53666126 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629977 |
| ANSWER_ID:53666111 |
| TITLE:sqlldr新增首列默认值 |
| ANSWER: ctl文件里定义的字段顺序,是解析你数据文件的顺序,不是数据库中字段的顺序。你数据文件里没这个字段,当然这个字段就不能放在ctl文件的最前面,只能放在最后面 |
| LINK:https://ask.csdn.net/questions/7629977?answer=53666111 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629993 |
| ANSWER_ID:53666107 |
| TITLE:your MySQL server version for the right syntax to use near 'where) from 表 where 条件 |
| ANSWER: 根据上面的讨论,看上去其实你也不知道完整的sql是什么,因为你是用工具自动产生的sql去查的,建议跟踪数据库日志,看看完整的sql到底是啥样的,然后去排查工具的使用方法有什么问题 |
| LINK:https://ask.csdn.net/questions/7629993?answer=53666107 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630085 |
| ANSWER_ID:53666086 |
| TITLE:Oracle 想问一下这种情况正则表达式应该如何编写 |
| ANSWER: 你题目没有提供关键信息,两个"以下"的下面都没有东西,请补充完整 |
| LINK:https://ask.csdn.net/questions/7630085?answer=53666086 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630102 |
| ANSWER_ID:53666081 |
| TITLE:SQL触发器中insert触发器查询到数据,写入变成了'0' |
| ANSWER: 你去找找执行insert im_stock_serial这个表的程序,看看当时插入的到底是什么。因为不排除它是先插入的0,再去更新成非0的情况。你触发器只监视了insert ,没有管update |
| LINK:https://ask.csdn.net/questions/7630102?answer=53666081 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630160 |
| ANSWER_ID:53666075 |
| TITLE:数据合并,在进行数据透视 |
| ANSWER: 你得举个数据的例子,处理前后的数据分别长什么样,并说明使用的数据库类型、数据库版本,可以使用的相关工具等等,要不然这题没法答。 |
| LINK:https://ask.csdn.net/questions/7630160?answer=53666075 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630166 |
| ANSWER_ID:53666057 |
| TITLE:关于#SQL#的问题,按年龄分开统计有什么好的方法? |
| ANSWER: 你最终要的输出数据格式长啥样? |
| LINK:https://ask.csdn.net/questions/7630166?answer=53666057 |
| SOURCE:CSDN_ASK |
| ASK_ID:7630019 |
| ANSWER_ID:53666051 |
| TITLE:oracle12c存入的表数据存在乱码情况,各项编码配置都已是utf-8,请问是什么情况? |
| ANSWER: 不是改UTF8就解决乱码了,重要的是字符集环境和数据要匹配,你先试下查询的时候转码,看看能不能解析出来,看看这个数据的字符集到底是个啥 查一下这个,把其中一行的数据发出来,我分析下看看是什么字符集 |
| LINK:https://ask.csdn.net/questions/7630019?answer=53666051 |
| SOURCE:CSDN_ASK |
| ASK_ID:751537 |
| ANSWER_ID:53666043 |
| TITLE:大数据量Mysql查询后经过循环使用python分片 |
| ANSWER: 三年前的问题。。。 |
| LINK:https://ask.csdn.net/questions/751537?answer=53666043 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629867 |
| ANSWER_ID:53665423 |
| TITLE:sql sever查询按时就餐率 |
| ANSWER: 把你建表sql和测试数据的sql发出来,并说明你查询结果长什么样,查询结果中每个字段的计算公式 |
| LINK:https://ask.csdn.net/questions/7629867?answer=53665423 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629685 |
| ANSWER_ID:53665387 |
| TITLE:在触发器中用游标执行存储过程,发生重复执行的情况 |
| ANSWER: 如果我没看错的话,你这个触发器里写了两次 |
| LINK:https://ask.csdn.net/questions/7629685?answer=53665387 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629807 |
| ANSWER_ID:53665379 |
| TITLE:如何判断Sqlite数据库某一列中是否含有特定的内容 |
| ANSWER: 你这个问题是想问数据库什么查还是问C#代码怎么写? 由于你选的是大数据频道问答区,所以只能给出以下建议。 查出来后,判断这个值是否大于0. 至于c#怎么查数据库以及怎么赋值,这个随便搜搜都有例子 |
| LINK:https://ask.csdn.net/questions/7629807?answer=53665379 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629746 |
| ANSWER_ID:53665373 |
| TITLE:access怎么用得到这个呀 |
| ANSWER: 楼上说得对,这玩意要用VBA编程, |
| LINK:https://ask.csdn.net/questions/7629746?answer=53665373 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629383 |
| ANSWER_ID:53665166 |
| TITLE:dbms_output.put_line只能在存储过程中使用吗? |
| ANSWER: dbms_output.put_line本身就是个procedure,不带return,所以不能在sql中使用,只能在plsql块中使用 |
| LINK:https://ask.csdn.net/questions/7629383?answer=53665166 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629483 |
| ANSWER_ID:53665155 |
| TITLE:关于mysql触发器问题 |
| ANSWER: 表上控制了你这个字段不能为空,那为啥你硬是要塞个空值进去呢?这不违背逻辑了么?不是应该去看这里为什么会传空值进来么? |
| LINK:https://ask.csdn.net/questions/7629483?answer=53665155 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629492 |
| ANSWER_ID:53665152 |
| TITLE:来看看我的问题些,哎。 |
| ANSWER: 你这是面试题吧,如果不会的话,一条一条网上搜呀,都是些基础知识,又不是什么疑难问题。如果这些都不会,那就回炉重造吧 |
| LINK:https://ask.csdn.net/questions/7629492?answer=53665152 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629544 |
| ANSWER_ID:53665149 |
| TITLE:给出多个区间,sql怎么判断字段值是否满足参数列表的其中之一? |
| ANSWER: 最简单通用的方法还是动态拼接条件。 |
| LINK:https://ask.csdn.net/questions/7629544?answer=53665149 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629613 |
| ANSWER_ID:53665133 |
| TITLE:如何设置触发器删除或修改某个字段 |
| ANSWER: 楼上"不太完美的程序猿"已给出正确代码 |
| LINK:https://ask.csdn.net/questions/7629613?answer=53665133 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629611 |
| ANSWER_ID:53665130 |
| TITLE:You can't specify target table '表' for update in FROM clause |
| ANSWER: mysql不能在查自己的时候同时更新自己,再包一层就好了,修改后的sql,楼上"倚竹醉酒剑轻吟 "已经给了,我就不贴了 |
| LINK:https://ask.csdn.net/questions/7629611?answer=53665130 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629627 |
| ANSWER_ID:53665120 |
| TITLE:怎么找出读库被限制查询速度的证据哇? |
| ANSWER: 生产库对应的实时读库本来就不会有很高的性能,慢当然不是问题。 |
| LINK:https://ask.csdn.net/questions/7629627?answer=53665120 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629387 |
| ANSWER_ID:53665109 |
| TITLE:mysql数据库配置环境完成还是不能初始化 |
| ANSWER: Windows下安装MySQL详细教程 - m1racle - 博客园 Windows下安装MySQL详细教程 1、安装包下载 2、安装教程 (1)配置环境变量 (2)生成data文件 (3)安装MySQL (4)启动服务 (5)登录MySQL (6)查询用户密码 (7) https://www.cnblogs.com/zhangkanghui/p/9613844.html |
| LINK:https://ask.csdn.net/questions/7629387?answer=53665109 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629314 |
| ANSWER_ID:53664441 |
| TITLE:windows环境,跑200G不到的数据,如何实现高效运作? |
| ANSWER: 数据初始化的时候,表上先不要加索引,等数据导完再加索引。 |
| LINK:https://ask.csdn.net/questions/7629314?answer=53664441 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629287 |
| ANSWER_ID:53664439 |
| TITLE:Sql,需要取a表中每天作品的pv数据,jion联合查找主要是为了区分作品制作平台,不知道哪里出了问题,哪位有时间可以帮我看下么~ |
| ANSWER: 你先说遇到什么问题了呀? |
| LINK:https://ask.csdn.net/questions/7629287?answer=53664439 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628969 |
| ANSWER_ID:53664266 |
| TITLE:决策报表中两个报表快的联动 |
| ANSWER: 用的啥工具都不说。建议去翻下你所使用的工具的官方教程 |
| LINK:https://ask.csdn.net/questions/7628969?answer=53664266 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629046 |
| ANSWER_ID:53664265 |
| TITLE:友友们,这种情况应该怎么处理。 |
| ANSWER: 这报错不是已经告诉你哪里有问题了么?
|
| LINK:https://ask.csdn.net/questions/7629046?answer=53664265 |

| SOURCE:CSDN_ASK |
| ASK_ID:7629048 |
| ANSWER_ID:53664264 |
| TITLE:用PyODBC连接excel数据库使用sum over partition by的语法报错 |
| ANSWER: excel数据库怎么可能支持这种高级函数,就连mysql也是到8.0才开始支持的。excel数据库只能用最原始最基本的sql语法,像这分组求和只能先求和作为子查询再去关联了 |
| LINK:https://ask.csdn.net/questions/7629048?answer=53664264 |
| SOURCE:CSDN_ASK |
| ASK_ID:7629080 |
| ANSWER_ID:53664261 |
| TITLE:excel中特殊字符导入数据库不识别 |
| ANSWER: 楼上是不是搞错了,UTF-8也是支持法语的,中文字符集应该是GBK。 |
| LINK:https://ask.csdn.net/questions/7629080?answer=53664261 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628956 |
| ANSWER_ID:53664008 |
| TITLE:sql语句根据编码规则查出统一级别层级的数据 |
| ANSWER: 你最后要查出来的数据格式是啥样的?请举例说明 |
| LINK:https://ask.csdn.net/questions/7628956?answer=53664008 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628966 |
| ANSWER_ID:53664005 |
| TITLE:一年内连续三天过户的车辆怎么求 |
| ANSWER: 请说明数据库类型和版本。 sql server数据库,在一个月中,相同的ID,连续三天数据。这个要怎么写?-大数据-CSDN问答 CSDN问答为您找到sql server数据库,在一个月中,相同的ID,连续三天数据。这个要怎么写?相关问题答案,如果想了解更多关于sql server数据库,在一个月中,相同的ID,连续三天数据。这个要怎么写? sql、数据库 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7627710?answer=53662243 |
| LINK:https://ask.csdn.net/questions/7628966?answer=53664005 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628604 |
| ANSWER_ID:53663814 |
| TITLE:查询学生成绩表中700分一下总分最高的学生,怎么用嵌套查询查出 |
| ANSWER: 楼上这个专家的sql错的地方太多了。 但特么谁这么写我就跟谁急。 然后,在12c以上,甚至都不需要使用嵌套 |
| LINK:https://ask.csdn.net/questions/7628604?answer=53663814 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628609 |
| ANSWER_ID:53663796 |
| TITLE:Endnote 12031错误怎么解决? |
| ANSWER: 服务器连接被重置, |
| LINK:https://ask.csdn.net/questions/7628609?answer=53663796 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628636 |
| ANSWER_ID:53663793 |
| TITLE:MySQL的中间表、临时表、虚拟表都是什么意思? |
| ANSWER: 这些名词其实是约定俗成的几个非标准说法,在不同的场景下其实有不同的含义,无法给定一个完整的标准定义。 |
| LINK:https://ask.csdn.net/questions/7628636?answer=53663793 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628649 |
| ANSWER_ID:53663785 |
| TITLE:MySQL8.0.26安装 |
| ANSWER: 使用管理员方式打开cmd,粘贴下列命令并回车确定 然后继续在cmd窗口中输入下列命令并回车确定 接下来再尝试安装mysql |
| LINK:https://ask.csdn.net/questions/7628649?answer=53663785 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628673 |
| ANSWER_ID:53663781 |
| TITLE:Sql server 2019 数据库的累计大小将超出每 数据库 为 10240 MB 的许可限制值 |
| ANSWER: 把许可协议修改成专业版或者开发版。 SQL server 2008 附加数据库时出现累计大小超过使用许可限制的解决办法(亲测有效)_努力变得不菜的菜鸡的博客-CSDN博客_sql2008数据库大小限制 问题来源大概是要去还原mdf文件网上的很多帖子说采用附加数据库的方式打开SSM,选中“数据库”三个字,右击,选择“附加”即可要解决的任务添加的数据大小是20g,很明显软件支撑不了问题就来了,当添加的文件1g时,就报错,出现的信息大概是下面这样的也就是数据库的累积大小超过许可限制。网上的很多方法都是说:直接将epress版本升级到专业版就好但是。。。。。。因为我太懒了 所以就有了下... https://blog.csdn.net/qq_43584847/article/details/103980767 |
| LINK:https://ask.csdn.net/questions/7628673?answer=53663781 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628756 |
| ANSWER_ID:53663777 |
| TITLE:sql里如何统计一段文章中输入了多少个汉字、英文单词、字母、数字和符号。 |
| ANSWER: 先说数据库类型,以及用什么工具。 |
| LINK:https://ask.csdn.net/questions/7628756?answer=53663777 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628765 |
| ANSWER_ID:53663774 |
| TITLE:正则表达式:oracle数据库中表名统计,存在备份末尾为下划线加数字的表名,例:(_01),如何去掉? |
| ANSWER: oracle里使用正则表达式请使用对应的正则函数 |
| LINK:https://ask.csdn.net/questions/7628765?answer=53663774 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628573 |
| ANSWER_ID:53663321 |
| TITLE:学海无涯如何从中调用学过的知识 |
| ANSWER: 多思考、多用。 |
| LINK:https://ask.csdn.net/questions/7628573?answer=53663321 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628506 |
| ANSWER_ID:53663260 |
| TITLE:利用cmd无法退出mysql |
| ANSWER: 退出mysql, 请输入 可以输入help;查看帮助
|
| LINK:https://ask.csdn.net/questions/7628506?answer=53663260 |

| SOURCE:CSDN_ASK |
| ASK_ID:7628133 |
| ANSWER_ID:53663169 |
| TITLE:全量和增量时间点关联 |
| ANSWER: 你这明显要改跑批的程序啊,内部没开发人员么?软件服务提供商呢? |
| LINK:https://ask.csdn.net/questions/7628133?answer=53663169 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628149 |
| ANSWER_ID:53663165 |
| TITLE:外网 ip 和 localhost 连接本服务器数据库 速度一样吗 |
| ANSWER: 你这个指的是同一台机,在连接本地数据库的时候,使用这个数据库的外网ip和localhost的速度区别吧? |
| LINK:https://ask.csdn.net/questions/7628149?answer=53663165 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628152 |
| ANSWER_ID:53663152 |
| TITLE:为什么数据库日期格式格式化之后少了一天? |
| ANSWER: 时区不一样,你上面是东八区,下面是默认时区 |
| LINK:https://ask.csdn.net/questions/7628152?answer=53663152 |
| SOURCE:CSDN_ASK |
| ASK_ID:7628170 |
| ANSWER_ID:53663151 |
| TITLE:MySQL跳过密码登录失效 |
| ANSWER:
这个不是报错了么,找不到数据目录,数据目录初始化失败 |
| LINK:https://ask.csdn.net/questions/7628170?answer=53663151 |

| SOURCE:CSDN_ASK |
| ASK_ID:7628298 |
| ANSWER_ID:53663137 |
| TITLE:MySQL 查询加引号问题 |
| ANSWER: 你数据库版本是多少?我用最新版mariadb测试没有复现你这个场景
如果是老版本的mysql,会有精度丢失的问题
|
| LINK:https://ask.csdn.net/questions/7628298?answer=53663137 |


| SOURCE:CSDN_ASK |
| ASK_ID:7628311 |
| ANSWER_ID:53663123 |
| TITLE:求一个sql中查询一段时间内缺失的哪些天 |
| ANSWER: 什么类型的数据库?数据库版本是多少?
然后再去判断你的数据是否exists于这个日期中就行了 |
| LINK:https://ask.csdn.net/questions/7628311?answer=53663123 |

| SOURCE:CSDN_ASK |
| ASK_ID:7628362 |
| ANSWER_ID:53663102 |
| TITLE:请问这个SQL怎么写 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7628362?answer=53663102 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627882 |
| ANSWER_ID:53662298 |
| TITLE:提问,mysql workbanch连接遇到这个问题怎么解决? |
| ANSWER: 你配置登录信息的那个地方,把ssl改成不用就行了
这里改设置
|
| LINK:https://ask.csdn.net/questions/7627882?answer=53662298 |


| SOURCE:CSDN_ASK |
| ASK_ID:7627847 |
| ANSWER_ID:53662251 |
| TITLE:用CMD加密文件夹失败 |
| ANSWER: "MD E:\JM.." 这个命令不是创建文件,而是创建一个名称叫"JM.."的文件夹, 我刚刚测试了一把,这个漏洞在win10上已经没有了,执行 "MD E:\JM.."生成的文件夹实际上是"JM",没有".."了,达不到你想要的加密效果,如果你要进入这个文件夹,直接cd JM就行了 |
| LINK:https://ask.csdn.net/questions/7627847?answer=53662251 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627802 |
| ANSWER_ID:53662249 |
| TITLE:java怎么获取当前年份的前两个月前日期(年份保持不变) |
| ANSWER: 用greatest函数取你取出来的这个日期和当前的一月一日之间的最大值即可 |
| LINK:https://ask.csdn.net/questions/7627802?answer=53662249 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627823 |
| ANSWER_ID:53662246 |
| TITLE:引发类型为System.OutOfMemoryException的异常 |
| ANSWER: OutOfMemory就是内存不够,溢出了,请检查你机器的内存大小,以及程序中是否有占用大量内存未回收的情况 |
| LINK:https://ask.csdn.net/questions/7627823?answer=53662246 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627837 |
| ANSWER_ID:53662245 |
| TITLE:sql链接oracle.错误7303,敢问谁能解惑! |
| ANSWER: 这个报错已经很明显了
请检查你的tns名称是否配置正确 |
| LINK:https://ask.csdn.net/questions/7627837?answer=53662245 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627710 |
| ANSWER_ID:53662243 |
| TITLE:sql server数据库,在一个月中,相同的ID,连续三天数据。这个要怎么写? |
| ANSWER: 先用递归sql准备个完整的日期列,然后取出机器和日期去重,外关联,再用开窗函数,按照完整日期列排序,根据机器分组,以当前行的上一行到下一行作为移动窗口,统计移动窗口内的非空值个数,然后取出统计值为3的记录,以此作为查询条件再去查源数据 以下为实测截图
|
| LINK:https://ask.csdn.net/questions/7627710?answer=53662243 |

| SOURCE:CSDN_ASK |
| ASK_ID:7627803 |
| ANSWER_ID:53662162 |
| TITLE:mimiciv数据库根据相同ID提取不同表格中的数据 |
| ANSWER: 字段前面要加上表名或者表的别名,否则你两个表有同名字段时,它不知道你是想用哪个 |
| LINK:https://ask.csdn.net/questions/7627803?answer=53662162 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627778 |
| ANSWER_ID:53662153 |
| TITLE:换了手机,现在要将旧手机的资料传到新手机上 |
| ANSWER: 各大手机品牌基本都有对应的换机app,只要在老手机里安装好,启动,连接上新手机,就会自动传数据到新手机了。如果是同品牌手机,甚至连你的桌面图标排列和系统设置都能传过去 |
| LINK:https://ask.csdn.net/questions/7627778?answer=53662153 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627736 |
| ANSWER_ID:53662071 |
| TITLE:oracle inner join 链接 多对多 效率优化 |
| ANSWER: 这哪里多对多了?你的prod里,难道prod_id不是主键?会有重复值? 如果这个sql效率慢,那就说明你这两个表上的索引没建或者建得不对,另外,还要查看下prod_price是否存在高水位的情况 |
| LINK:https://ask.csdn.net/questions/7627736?answer=53662071 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627653 |
| ANSWER_ID:53661852 |
| TITLE:各位专家,想问一个问题,我的navicat premium 创建数据库设置utf8字符集之后默认给我改成utf8mb3了,怎么改都是utf8mb3 |
| ANSWER: mysql中的utf8,就是最大3字节的unicode字符,也就是mysql中的utf8mb3,显示utf8mb3才是真正表示以前的utf8,新的utf8会显示成utf8mb4,只显示utf8会引起歧义,现在在mysql里面不会有"utf8"这个字符集了,取而代之的是"utf8mb3"和"utf8mb4" |
| LINK:https://ask.csdn.net/questions/7627653?answer=53661852 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627627 |
| ANSWER_ID:53661848 |
| TITLE:PostgreSQL连接不上数据库? |
| ANSWER: 你这安装的路径和命令的路径不一样啊,文件浏览器里的中间有个program files,但是cmd里面没有 |
| LINK:https://ask.csdn.net/questions/7627627?answer=53661848 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627607 |
| ANSWER_ID:53661846 |
| TITLE:mysql 安装出现红叉,求解决 |
| ANSWER: 本来这个安装包会自动帮你安装相关依赖,但看上去是安装失败了,所以你得手动安装vc++2019 |
| LINK:https://ask.csdn.net/questions/7627607?answer=53661846 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627535 |
| ANSWER_ID:53661841 |
| TITLE:请问这个意思是只支持sql server数据库吗? |
| ANSWER: 那个只是针对sql server提供了SDE而已,另外,这个ARCGIS是收费的,可以尝试使用开源的postgis,这个对postgresql的兼容性更好,因为它就是基于postgresql的扩展 PostGIS — Spatial and Geographic Objects for PostgreSQL PostGIS provides spatial objects for the PostgreSQL database, allowing storage and query of information about location and mapping.  https://postgis.net/ |
| LINK:https://ask.csdn.net/questions/7627535?answer=53661841 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627500 |
| ANSWER_ID:53661824 |
| TITLE:PL/SQL连接oracle数据库后,数据正常显示,但是查看字段注释乱码 |
| ANSWER: 查下字段注释的静态视图 如果你这里也显示问号,那么有两种可能: |
| LINK:https://ask.csdn.net/questions/7627500?answer=53661824 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627465 |
| ANSWER_ID:53661809 |
| TITLE:大数据如何进行数据阶段的验证 |
| ANSWER: 对于源端和目标端,分别对所有行列的数据用同一种hash算法得出一个值,比如计算md5,再比较这个值是否一致,这是在验证阶段最减少数据输出的方式了 |
| LINK:https://ask.csdn.net/questions/7627465?answer=53661809 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627461 |
| ANSWER_ID:53661804 |
| TITLE:MySQL有一条空记录 |
| ANSWER: 你建个空表去查,也是这样的效果,无法根据截图所示来判断是空行还是无数据。建议你把这个sql改成count,看看是1行还是0行 |
| LINK:https://ask.csdn.net/questions/7627461?answer=53661804 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627365 |
| ANSWER_ID:53661286 |
| TITLE:关于#华为#的问题,请各位专家解答! |
| ANSWER: 你想问啥,麻烦说明问题,这图就一个简单的网络拓扑图而已 |
| LINK:https://ask.csdn.net/questions/7627365?answer=53661286 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627371 |
| ANSWER_ID:53661285 |
| TITLE:这个是什么问题? 该怎么操作啊 |
| ANSWER: 不能将字符串转换成浮点数。从这个报错上看,是有个值为空值'',经测试,空值的确不能转换成浮点
你可以把z1到z5都打印出来看看哪个为空了 |
| LINK:https://ask.csdn.net/questions/7627371?answer=53661285 |

| SOURCE:CSDN_ASK |
| ASK_ID:7627366 |
| ANSWER_ID:53661283 |
| TITLE:下术编码中eval ( plt [ i ]. split (':')[1])不理解 |
| ANSWER: 你这代码都乱掉了,请把代码放到代码块里
|
| LINK:https://ask.csdn.net/questions/7627366?answer=53661283 |

| SOURCE:CSDN_ASK |
| ASK_ID:7627369 |
| ANSWER_ID:53661275 |
| TITLE:eclipse 上安装weblogic插件,无法正确使用如图: |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7627369?answer=53661275 |

| SOURCE:CSDN_ASK |
| ASK_ID:7627294 |
| ANSWER_ID:53661264 |
| TITLE:请问安装git出现如下错误什么原因,如何解决? |
| ANSWER: bash - unable to run post-install scripts - Stack Overflow https://stackoverflow.com/questions/52675052/unable-to-run-post-install-scripts |
| LINK:https://ask.csdn.net/questions/7627294?answer=53661264 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627350 |
| ANSWER_ID:53661245 |
| TITLE:对列表使用pop()函数,列表里面有10个字符串内容,用for循环只能打印5个结果,代码如图,问题在哪里 |
| ANSWER: 你在循环里,把i打印出来看看就知道了。 |
| LINK:https://ask.csdn.net/questions/7627350?answer=53661245 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627347 |
| ANSWER_ID:53661238 |
| TITLE:无法连接PostgreSQL数据库? |
| ANSWER: 你先确认一下你的PostgreSQL安装在哪个路径下了,找到psql.exe这个文件在哪。 |
| LINK:https://ask.csdn.net/questions/7627347?answer=53661238 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627295 |
| ANSWER_ID:53661235 |
| TITLE:根据表中2个字段的值判断表中其余2个字段的值 |
| ANSWER: 问题说得有点绕,但看上去就是以A表做主表去关联另外两个表而已,只是A表的关联字段可能为空,由于不清楚你数据的主键关系,以及是否存在重复的情况,你可以先这样试试 另外,如果A表中的a,b两个字段的值不会出现重复的话,完全可以把这个两个字段合成一个字段来处理,这样就可以只用A表来left join另外两个表了。 |
| LINK:https://ask.csdn.net/questions/7627295?answer=53661235 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627276 |
| ANSWER_ID:53661227 |
| TITLE:PLSQL导入数据后,感觉数据量不对。 |
| ANSWER: 这与导入本身没关系,是因为你的excel表本身下面就一堆空行,你要先在excel里删掉这些空行,保存,再导入。而且,你保存完后,会发现文件神奇的变小了好多。。。 |
| LINK:https://ask.csdn.net/questions/7627276?answer=53661227 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627238 |
| ANSWER_ID:53661150 |
| TITLE:MYSQL 在做批量更新的时候需要多个函数,怎么做 |
| ANSWER: 先上一张图
然后嵌套函数更新,没有报错
查询结果,已经被正常更新
所以,请提供你的报错信息看看,应该不是嵌套函数的问题 |
| LINK:https://ask.csdn.net/questions/7627238?answer=53661150 |



| SOURCE:CSDN_ASK |
| ASK_ID:7627219 |
| ANSWER_ID:53661144 |
| TITLE:数值模拟,如何获取2021年国外洪灾数据? |
| ANSWER: 你用洪灾数据的英语在国外搜索引擎搜一下就能看到很多了,比如earthdata.nasa之类的,不过要注册 下面这个链接是漂亮国公开的数据 |
| LINK:https://ask.csdn.net/questions/7627219?answer=53661144 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627227 |
| ANSWER_ID:53661132 |
| TITLE:sql安装 出现服务器运行失败错误 |
| ANSWER: 打开你电脑的windows update 服务再试
|
| LINK:https://ask.csdn.net/questions/7627227?answer=53661132 |

| SOURCE:CSDN_ASK |
| ASK_ID:7627222 |
| ANSWER_ID:53661127 |
| TITLE:想问一下各位程序员,C语言能写浏览器吗? |
| ANSWER: 当然可以,Windows操作系统的大部分内核都是用C语言写的,而且现在很多开发语言的底层都是基于C语言 |
| LINK:https://ask.csdn.net/questions/7627222?answer=53661127 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626300 |
| ANSWER_ID:53661126 |
| TITLE:从第三方API获取信息,获取成功扣除余额1,实际执行余额扣除混乱 |
| ANSWER: 你把数据交互想得太简单了,楼上已经有很多方法了。 |
| LINK:https://ask.csdn.net/questions/7626300?answer=53661126 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626958 |
| ANSWER_ID:53661124 |
| TITLE:请问pgsql可以存储要素类吗?具体怎么创建才能存储呀? |
| ANSWER: ArcGIS Desktop连接postgresql并创建sde数据库_我爱吃榴莲的博客-CSDN博客 ArcGIS Desktop连接postgresql并创建sde数据库环境:ArcGIS 10.8;postgresql 11.2;操作步骤:安装postgresql 11.2 ,安装方法简单,在这里不进行描述。链接:https://pan.baidu.com/s/1ELvGtNeT19GAOK9pDPzH9A提取码:ot30打开postgresql 安装目录下data文件夹,打开pg_hba.conf 文件,在最后一行添加,host all all https://blog.csdn.net/weixin_45573664/article/details/108821790 其实官网上有教程的,可惜被GFW了
|
| LINK:https://ask.csdn.net/questions/7626958?answer=53661124 |

| SOURCE:CSDN_ASK |
| ASK_ID:7627106 |
| ANSWER_ID:53661072 |
| TITLE:PLSQL可以导入xls文件,但无法选择xlsx文件。 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7627106?answer=53661072 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627156 |
| ANSWER_ID:53661055 |
| TITLE:mysql如何查找某值在未来30天内是否重复 |
| ANSWER: 这题问法有问题,搞得好像是要用机器学习算法预测未来一样。。。 |
| LINK:https://ask.csdn.net/questions/7627156?answer=53661055 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627161 |
| ANSWER_ID:53661049 |
| TITLE:mysql 某字段内容 为另一个表的 select 结果,怎么弄? |
| ANSWER: 你多个商品是想分行显示还是在一行显示? 如果是要求一个客户只显示一行,那么你需要确定下怎么显示多个商品,是直接逗号分隔还是用jsonlist,另外你还要说明一下你的数据库版本。 |
| LINK:https://ask.csdn.net/questions/7627161?answer=53661049 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627069 |
| ANSWER_ID:53660996 |
| TITLE:navicat设计视图报错 1191-unknown system variable ‘datadir’ |
| ANSWER: 上操作步骤截图,这是你哪里填错了 |
| LINK:https://ask.csdn.net/questions/7627069?answer=53660996 |
| SOURCE:CSDN_ASK |
| ASK_ID:7627086 |
| ANSWER_ID:53660995 |
| TITLE:数据可视化(power bl) |
| ANSWER: 定位不一样,其实你自己的问题里已经对这几种工具做了区分。 |
| LINK:https://ask.csdn.net/questions/7627086?answer=53660995 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626713 |
| ANSWER_ID:53660571 |
| TITLE:m1安装Oracle |
| ANSWER: 我缺一台m1 的电脑,所以没办法测试能不能装。 |
| LINK:https://ask.csdn.net/questions/7626713?answer=53660571 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626716 |
| ANSWER_ID:53660567 |
| TITLE:Mac m1芯片安装Oracle11g |
| ANSWER: oracle11g已经太老了,十多年了,如果还想使用的话,建议用docker版本,干净又卫生 |
| LINK:https://ask.csdn.net/questions/7626716?answer=53660567 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626744 |
| ANSWER_ID:53660564 |
| TITLE:怎么解决golang中的未配置sql方言 |
| ANSWER: 你这个截图都已经提供给你两个操作选项了,点一点不就好了么 |
| LINK:https://ask.csdn.net/questions/7626744?answer=53660564 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626765 |
| ANSWER_ID:53660563 |
| TITLE:有关使用JdbcTemplate查询的问题:sql语句直接运行可正常查出,但用代码查就出现不同结果 |
| ANSWER: 主要代码不是在这里,而是应该在你的emp这个class里,你去瞅瞅是不是对应错了 |
| LINK:https://ask.csdn.net/questions/7626765?answer=53660563 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626784 |
| ANSWER_ID:53660558 |
| TITLE:数据库的基本设计,如何设计规范的表 |
| ANSWER: 在大数据时代之前,传统的关系型数据库设计会尽可能的减少重复冗余数据的存储,像你这么设计表,要浪费不少磁盘空间。并且,还可能会出现在你的班级表里,同一个课程id会对应多个课程名,除非程序设计得特别完善,课程名自动强制从课程表里联动获取且禁止直接修改班级表里的课程名,写这些代码又要浪费多少脑力。 |
| LINK:https://ask.csdn.net/questions/7626784?answer=53660558 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626797 |
| ANSWER_ID:53660544 |
| TITLE:postgrepsql如何保留小数点后面的0 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7626797?answer=53660544 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626272 |
| ANSWER_ID:53660315 |
| TITLE:postgrep要求数字最后一位补0怎么处理 |
| ANSWER: 乍一看以为是精度问题,但细看,这不对呀,这问题描述是不是有问题? 其实吧,对于数字而言,小数点后面末尾的0没有任何意义,你现在要求的是显示成你想要的格式,那么这个时候,它其实是按照你要求显示的字符串了,应该用to_char去格式化它
像这个sql,小数点后面接多少个0,它就会保留小数点后多少位进行显示。 |
| LINK:https://ask.csdn.net/questions/7626272?answer=53660315 |

| SOURCE:CSDN_ASK |
| ASK_ID:7626283 |
| ANSWER_ID:53660309 |
| TITLE:spark数据查询前6个字符相同的字段的个数并从多到少排序 |
| ANSWER: 你这自己不是已经用文字描述了逻辑了么?截取前6位,聚合计数 |
| LINK:https://ask.csdn.net/questions/7626283?answer=53660309 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626600 |
| ANSWER_ID:53660298 |
| TITLE:如何在SQL语句中修改,实现数据中间添加小数点 |
| ANSWER: 你意思是314048变成314.048? |
| LINK:https://ask.csdn.net/questions/7626600?answer=53660298 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626443 |
| ANSWER_ID:53660293 |
| TITLE:Oracle 查询时报无效号码 |
| ANSWER: 麻烦报错信息截个图,从来没有听说过有"无效号码"这个报错,接近一点的只有"无效数字" |
| LINK:https://ask.csdn.net/questions/7626443?answer=53660293 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626499 |
| ANSWER_ID:53660286 |
| TITLE:with as性能调优 |
| ANSWER: with as 只能放在最前面,你这条sql要求和的话,没必要再套一层 |
| LINK:https://ask.csdn.net/questions/7626499?answer=53660286 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626183 |
| ANSWER_ID:53659717 |
| TITLE:为什么DBeaver不能导出excel哇? |
| ANSWER: 连mysql官方的免费工具workbench都不支持导出excel,你有没有想过是不是免费的工具都不支持导出成xlsx? |
| LINK:https://ask.csdn.net/questions/7626183?answer=53659717 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625973 |
| ANSWER_ID:53659692 |
| TITLE:SqlServer判断两个日期时间是否有交叉 |
| ANSWER: 楼上神仙漏了场景,这个只判断了查询点是否都在数据区间内,实际要求的应该是任意一秒有重叠就算满足 |
| LINK:https://ask.csdn.net/questions/7625973?answer=53659692 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626123 |
| ANSWER_ID:53659675 |
| TITLE:postgrep怎么支持 日期在前的格式 |
| ANSWER: 日期数据本身是没有格式的,日期的显示格式是由客户端环境变量控制的,你这日期转字符串再转日期没有任何意义,就下面这样就行了
|
| LINK:https://ask.csdn.net/questions/7626123?answer=53659675 |

| SOURCE:CSDN_ASK |
| ASK_ID:7625986 |
| ANSWER_ID:53659549 |
| TITLE:请问如何获取数据库文件的密码? |
| ANSWER: mdb的密码是可以直接破解的呀,我十年前用soft_VAP这个软件破解过mdb的密码 |
| LINK:https://ask.csdn.net/questions/7625986?answer=53659549 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626033 |
| ANSWER_ID:53659524 |
| TITLE:明细数据不全时如何取舍 |
| ANSWER: 一般对于时间跨度比较长的数据分析,最低时间分析维度也就是按天,这样业务系统也不用做过度的开发,而且占用存储空间也不大。 |
| LINK:https://ask.csdn.net/questions/7626033?answer=53659524 |
| SOURCE:CSDN_ASK |
| ASK_ID:7626012 |
| ANSWER_ID:53659463 |
| TITLE:sql server 将一列n行数据转换成一行n列 怎么转化呢? |
| ANSWER: 你新表的abcd是哪里来的? |
| LINK:https://ask.csdn.net/questions/7626012?answer=53659463 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625843 |
| ANSWER_ID:53659271 |
| TITLE:关于Linux shell处理两个文件实现两个文件按照要求合并 |
| ANSWER: 一定要用linux么?这玩意放数据库里分分钟搞定。。。 |
| LINK:https://ask.csdn.net/questions/7625843?answer=53659271 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625924 |
| ANSWER_ID:53659255 |
| TITLE:springboot操作Oracle |
| ANSWER: 你设置的这个自动提交只是会话级的,只表示你当前窗口自动提交。建议代码里显式commit,这样比较安全。或者连接池每个会话启动后都自动运行一次自动提交 |
| LINK:https://ask.csdn.net/questions/7625924?answer=53659255 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625554 |
| ANSWER_ID:53659229 |
| TITLE:SQL-請問我這個程式碼要怎麼改 |
| ANSWER: 说一下你想要的数据结果有哪些字段,每个字段的取值规则。 |
| LINK:https://ask.csdn.net/questions/7625554?answer=53659229 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625868 |
| ANSWER_ID:53659194 |
| TITLE:Pgsql: ERROR: cache lookup failed for operator family 0 |
| ANSWER: st_intersects是postgis组件的一个函数, |
| LINK:https://ask.csdn.net/questions/7625868?answer=53659194 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625401 |
| ANSWER_ID:53658230 |
| TITLE:python 如何处理一列数据以一定的步长滚动累加 |
| ANSWER: 你是想用python还是sql? |
| LINK:https://ask.csdn.net/questions/7625401?answer=53658230 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625306 |
| ANSWER_ID:53658221 |
| TITLE:查询选课门数等于课程总数的学生学号 |
| ANSWER: 没必要再套一层 |
| LINK:https://ask.csdn.net/questions/7625306?answer=53658221 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625366 |
| ANSWER_ID:53658213 |
| TITLE:oracle数据库金额抵扣问题 |
| ANSWER: 经典的批次分摊哈,在分摊时,关键点在于已分摊金额,这个金额需要累加,并且每次分摊前还要判断是否有剩余的金额进行分摊。我之前是把这个临时分摊金额保存到了表里。至于顺序,游标的sql里写order by就好了 |
| LINK:https://ask.csdn.net/questions/7625366?answer=53658213 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625351 |
| ANSWER_ID:53658203 |
| TITLE:superset 链接oracle数据库报错 |
| ANSWER: 你去看一下oracle客户端文件夹里有没有这个文件libclntsh.so,如果没有,把这个文件名带数字的那个文件复制一个出来,命令为libclntsh.so,或者直接使用最新的21版本客户端 |
| LINK:https://ask.csdn.net/questions/7625351?answer=53658203 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625300 |
| ANSWER_ID:53658020 |
| TITLE:MySql如何将时间差00:10:36 转换为分钟 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7625300?answer=53658020 |

| SOURCE:CSDN_ASK |
| ASK_ID:7625289 |
| ANSWER_ID:53658001 |
| TITLE:sql语句判断字符串长度为64 |
| ANSWER: 这是要查表结构还是表里面的数据? |
| LINK:https://ask.csdn.net/questions/7625289?answer=53658001 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624801 |
| ANSWER_ID:53657992 |
| TITLE:将下面的语句转为hive能运行的 |
| ANSWER: index改成instr |
| LINK:https://ask.csdn.net/questions/7624801?answer=53657992 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625015 |
| ANSWER_ID:53657990 |
| TITLE:数据库主键一直重复,导致新的数据插入不进去 |
| ANSWER: 这个其实与懂不懂数据库没有关系,你得搞清楚以下几个问题, 如果每次都是新增,那么就要找数据提供方,告诉他数据有问题。 |
| LINK:https://ask.csdn.net/questions/7625015?answer=53657990 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625143 |
| ANSWER_ID:53657969 |
| TITLE:数据库求第N高薪水left join问题 |
| ANSWER: 用分析函数 |
| LINK:https://ask.csdn.net/questions/7625143?answer=53657969 |
| SOURCE:CSDN_ASK |
| ASK_ID:7625220 |
| ANSWER_ID:53657946 |
| TITLE:SQL怎么实现这个要求? |
ANSWER:
截图来自https://modern-sql.com/feature/listagg |
| LINK:https://ask.csdn.net/questions/7625220?answer=53657946 |

| SOURCE:CSDN_ASK |
| ASK_ID:7625013 |
| ANSWER_ID:53657912 |
| TITLE:统计相同流水号下的某类数据 |
| ANSWER: 没必要套子查询,无非就是查no去重有多少个 |
| LINK:https://ask.csdn.net/questions/7625013?answer=53657912 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624798 |
| ANSWER_ID:53657136 |
| TITLE:mysql数据库插入的数据中文部分出现问号,怎么办 |
| ANSWER: 为什么非得用GBK呢?你有没有考虑过,现在大部分数据传输都用utf-8了,gbk里少了很多字符,未来出现一串文字里有个别几个字无法保存怎么办?全部都统一用UTF-8才是正解. MySQL字符集 GBK、GB2312、UTF8区别 解决 MYSQL中文乱码问题以及error 1406:data too long for column 'name' at row 1_zsm653983的专栏-CSDN博客_gbk字符集与gb2312字符集不兼容对吗 MySQL中涉及的几个字符集 character-set-server/default-character-set:服务器字符集,默认情况下所采用的。character-set-database:数据库字符集。character-set-table:数据库表字符集。优先级依次增加。所以一般情况下只需要设置character-set-server,而在创建数据库和表时不特别指定字符集 https://blog.csdn.net/zsm653983/article/details/7970179 |
| LINK:https://ask.csdn.net/questions/7624798?answer=53657136 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624825 |
| ANSWER_ID:53657127 |
| TITLE:mysql安装失败,命令安装时无法成功创建date文件夹,安照网上的方法修改了my.ini文件也不行 |
| ANSWER: 不要使用包含有中文的文件夹 |
| LINK:https://ask.csdn.net/questions/7624825?answer=53657127 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624740 |
| ANSWER_ID:53657039 |
| TITLE:!!navicat for mysql 5.7 |
| ANSWER: 你自己新建一个连接,填好要连的数据库信息就好了 |
| LINK:https://ask.csdn.net/questions/7624740?answer=53657039 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624449 |
| ANSWER_ID:53657032 |
| TITLE:Mysql并发操作同一个表同一个字段问题 |
| ANSWER: 很多情况下,程序代码去锁数据,不仅仅是为了不让别的会话修改,更多情况下是一种判断,判断这个数据是否正在被别的会话修改,这种操作一般放在一个事务操作的比较靠前的位置,根据加锁是否成功这个步骤,来决定是否需要继续向下执行正常逻辑还是去执行异常逻辑或者等待。 |
| LINK:https://ask.csdn.net/questions/7624449?answer=53657032 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624542 |
| ANSWER_ID:53657022 |
| TITLE:两表一对多查询多字段展示 |
| ANSWER: 是mysql还是oracle?数据库版本?数据要求的及时性有多高?每次只查一个还是查全部? |
| LINK:https://ask.csdn.net/questions/7624542?answer=53657022 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624590 |
| ANSWER_ID:53657004 |
| TITLE:PLSQL 上写的存储过程可以正常使用,但是转到oracle sql develper上就报错 |
| ANSWER: 能不能跑存储过程,与是plsql developer还是oracle sql developer无关,要么都不能跑,要么都能跑。当然如果你存储过程里要是做了什么ddl操作导致执行一次后过程就失效,那就是另一说了 建议重新下载一个完整版的oracle sql developer(内置jdk的那个包)和最新版的ORACLE客户端,我怀疑是你这个oracle sql developer丢了文件或者环境有问题 |
| LINK:https://ask.csdn.net/questions/7624590?answer=53657004 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624708 |
| ANSWER_ID:53656984 |
| TITLE:数据库sql语句,请问这个什么问题,怎么解决,球 |
| ANSWER: 你那个sum变量为啥要限制decimal(4,1)?直接一个int不就好了,你count还能count出小数来? |
| LINK:https://ask.csdn.net/questions/7624708?answer=53656984 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624389 |
| ANSWER_ID:53656550 |
| TITLE:mysql查询sql语句实现 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7624389?answer=53656550 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624371 |
| ANSWER_ID:53656543 |
| TITLE:sql中如何使用union将三行字符型的数据整合放在一行上? |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7624371?answer=53656543 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624193 |
| ANSWER_ID:53656537 |
| TITLE:sql中如何将下列三行合并成一行? |
ANSWER:在确定只有一个值非空的时候,用max聚合就能取到那个值了 |
| LINK:https://ask.csdn.net/questions/7624193?answer=53656537 |
| SOURCE:CSDN_ASK |
| ASK_ID:7624187 |
| ANSWER_ID:53656535 |
| TITLE:Oracle转postgreSQL update语句中怎么用row_number() over() |
| ANSWER: 这个表有没有主键?如果有的话,建议用row_number() over()取到前50行的主键后,再in这些主键去update |
| LINK:https://ask.csdn.net/questions/7624187?answer=53656535 |
| SOURCE:CSDN_ASK |
| ASK_ID:7623882 |
| ANSWER_ID:53655856 |
| TITLE:新华三“1+x”大数据运维中级证书去哪里查 |
| ANSWER: 点中间的获取与验证证书 |
| LINK:https://ask.csdn.net/questions/7623882?answer=53655856 |

| SOURCE:CSDN_ASK |
| ASK_ID:7623704 |
| ANSWER_ID:53655703 |
| TITLE:hive sql 使用问题 |
| ANSWER: 你第一个sql只是拼出一个字符串,并不是表名,当然不能直接代替表使用。 |
| LINK:https://ask.csdn.net/questions/7623704?answer=53655703 |
| SOURCE:CSDN_ASK |
| ASK_ID:7623486 |
| ANSWER_ID:53655687 |
| TITLE:mysql在第一次登陆时的unknown variable 'DATABASES={'如何解决 |
| ANSWER: 安装数据库的时候就装错了,让你填数据库名称的地方,你把'DATABASES={.......}'这一串都加进去了,把库删了重新建库吧 |
| LINK:https://ask.csdn.net/questions/7623486?answer=53655687 |
| SOURCE:CSDN_ASK |
| ASK_ID:7623817 |
| ANSWER_ID:53655681 |
| TITLE:sql查询全部关联表的各表数据量 |
| ANSWER: 写个过程,按表清单循环,一张一张表count,并将表名和记录数插入一张表,之后再查这张表就行了 |
| LINK:https://ask.csdn.net/questions/7623817?answer=53655681 |
| SOURCE:CSDN_ASK |
| ASK_ID:7623600 |
| ANSWER_ID:53655678 |
| TITLE:Oracle数据库查询语句 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7623600?answer=53655678 |
| SOURCE:CSDN_ASK |
| ASK_ID:7622933 |
| ANSWER_ID:53654572 |
| TITLE:为啥这个答案是FALSE的呢? |
ANSWER:你跑一下这段就知道了 |
| LINK:https://ask.csdn.net/questions/7622933?answer=53654572 |
| SOURCE:CSDN_ASK |
| ASK_ID:7623160 |
| ANSWER_ID:53654560 |
| TITLE:vmware 10 进不去 一直重复代码 |
| ANSWER: 你没有设置系统安装镜像,它找不到可以引导的系统,当然这样了 |
| LINK:https://ask.csdn.net/questions/7623160?answer=53654560 |
| SOURCE:CSDN_ASK |
| ASK_ID:7623203 |
| ANSWER_ID:53654556 |
| TITLE:如何引入pandas库 |
| ANSWER: 先确保已经安装pandas,如果没安装,就执行 然后你写python代码的时候,前面加上 import pandas ,这个import就叫引入 现在这课怎么教的,基本概念都还没会,都已经开始做数据分析了 |
| LINK:https://ask.csdn.net/questions/7623203?answer=53654556 |
| SOURCE:CSDN_ASK |
| ASK_ID:7623167 |
| ANSWER_ID:53654553 |
| TITLE:如何提升自己文章的阅读量? |
| ANSWER: 咋选到数据库开发标签了。。。你目前这才一篇,在这里要多活跃,才会被站点推荐给其他用户 |
| LINK:https://ask.csdn.net/questions/7623167?answer=53654553 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612722 |
| ANSWER_ID:53654470 |
| TITLE:阿里云数据库建库问题 |
| ANSWER: 在阿里提交工单,有专人服务,还能帮你看日志 |
| LINK:https://ask.csdn.net/questions/7612722?answer=53654470 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620383 |
| ANSWER_ID:53654466 |
| TITLE:oss-能实现一次性上传多个文件 和 一次性下载文件夹下面的所有文件的功能 |
| ANSWER: 你多个文件对应一个url?是个目录么? |
| LINK:https://ask.csdn.net/questions/7620383?answer=53654466 |
| SOURCE:CSDN_ASK |
| ASK_ID:7623091 |
| ANSWER_ID:53654461 |
| TITLE:这怎么解决啊,根本不知道怎么办 |
| ANSWER:
由于该目录下已经有文件,初始化失败 |
| LINK:https://ask.csdn.net/questions/7623091?answer=53654461 |

| SOURCE:CSDN_ASK |
| ASK_ID:7623080 |
| ANSWER_ID:53654456 |
| TITLE:请教个入门级的问题? |
| ANSWER: 对,如果这些用户下有些表禁止让AA访问,那么你这80张表每张表都要授权,但是授权命令可以用sql或者excel批量拼接生成 |
| LINK:https://ask.csdn.net/questions/7623080?answer=53654456 |
| SOURCE:CSDN_ASK |
| ASK_ID:7622609 |
| ANSWER_ID:53654034 |
| TITLE:update时,只对新引入的数据进行百分比计算,如何不影响前面已有的数据 |
| ANSWER: 所有的update sheet_sk后面加上限制条件,比如 |
| LINK:https://ask.csdn.net/questions/7622609?answer=53654034 |
| SOURCE:CSDN_ASK |
| ASK_ID:7622628 |
| ANSWER_ID:53654028 |
| TITLE:如何依次分别取 表#tb1里MID=1、2、3时的数字,然后再随机取10位数一次,请专家答疑解惑 |
| ANSWER: 你取 #tb1的时候,没带where过滤条件,它当然3行记录都出来了,既然声明了@GroupID这个变量,为啥不用上去呢? 其实大概就这个意思,子查询要不要加别名你自己去试, 我看到问题了,你order by newid()这玩意,把顺序都搞乱了
这是我第一次看sqlserver的过程代码,有点脑壳大,现在是跑第一行出来了,我再看看怎么随机 随机的出来了 要实现你这个目的,应该有更好的方法,不过这sqlserver的sql看得有点难受,不整了 |
| LINK:https://ask.csdn.net/questions/7622628?answer=53654028 |

| SOURCE:CSDN_ASK |
| ASK_ID:7622706 |
| ANSWER_ID:53654023 |
| TITLE:数据库没有学通,做一个查询报表给俺整不会了。。 |
| ANSWER: 你想问什么?麻烦把问题描述一下 |
| LINK:https://ask.csdn.net/questions/7622706?answer=53654023 |
| SOURCE:CSDN_ASK |
| ASK_ID:7622699 |
| ANSWER_ID:53654022 |
| TITLE:请问order by和limit一起用有什么错误吗 |
| ANSWER: oracle 不能使用 limit,正确的语法如下 以上语法是在oracle12c新增的,如果是更老的版本,建议结合row_number() over(order by )使用,常规的rownum容易出现分页数据重复或者遗漏的问题 |
| LINK:https://ask.csdn.net/questions/7622699?answer=53654022 |
| SOURCE:CSDN_ASK |
| ASK_ID:7622617 |
| ANSWER_ID:53654013 |
| TITLE:关于数据库中账号的登陆设备管理问题 |
| ANSWER: 不是微信的开发人员,怎么可能知道微信后台是怎么设计的,你加把油去腾讯应聘试试吧,没准就能看到微信源码了 |
| LINK:https://ask.csdn.net/questions/7622617?answer=53654013 |
| SOURCE:CSDN_ASK |
| ASK_ID:7622532 |
| ANSWER_ID:53653791 |
| TITLE:Excel用时间函数提取日期中的年月日(月日用两位数表示) |
| ANSWER: 用text格式化日期后,用left/right/mid去截取就行了,比如年就是截左边起4个字符 |
| LINK:https://ask.csdn.net/questions/7622532?answer=53653791 |
| SOURCE:CSDN_ASK |
| ASK_ID:7622537 |
| ANSWER_ID:53653790 |
| TITLE:Data Studio这个软件有没有人知道能不能连win10本地的Mysql8.0 |
| ANSWER: openGauss 的Data Studio是专门为openGauss数据库开发的,肯定不能连mysql,这个软件名称起得太没有特点了,一堆名字类似的软件. |
| LINK:https://ask.csdn.net/questions/7622537?answer=53653790 |
| SOURCE:CSDN_ASK |
| ASK_ID:7622460 |
| ANSWER_ID:53653784 |
| TITLE:oracle多列合并为一列问题 |
ANSWER:
下面这个sql就是获取上面那个sql的所有非空值。 你咋这么多奇奇怪怪的想法 |
| LINK:https://ask.csdn.net/questions/7622460?answer=53653784 |

| SOURCE:CSDN_ASK |
| ASK_ID:7621643 |
| ANSWER_ID:53652902 |
| TITLE:sql更改表数据类型有哪些限制? |
| ANSWER: 首先,定义varchar2类型的字段时,是要加上长度的,不加会报错。
在有数据的情况下,修改字段类型为其他类型都是不行的,只有同种类型可以把短的改成长的或者更精确的 ,比如timestamp其实是更精确的date |
| LINK:https://ask.csdn.net/questions/7621643?answer=53652902 |


| SOURCE:CSDN_ASK |
| ASK_ID:7621728 |
| ANSWER_ID:53652894 |
| TITLE:Sql语句查询 出现以下问题 |
| ANSWER: 把最后一行的 group by s.Sno 删掉就能查出数据来了。 |
| LINK:https://ask.csdn.net/questions/7621728?answer=53652894 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621659 |
| ANSWER_ID:53652565 |
| TITLE:ALTER TABLE TABLE_NAME SHRINK SPACE执行时间很长正常吗? |
| ANSWER: 经常delete的表,一般delete越多,执行SHRINK SPACE时间就越长。这属于正常现象。 |
| LINK:https://ask.csdn.net/questions/7621659?answer=53652565 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621605 |
| ANSWER_ID:53652476 |
| TITLE:oracle输出临时表所有列名 |
| ANSWER: 你这个语句如果查出来为空,说明你当前登录的用户下没有建立任何表,请尝试切换到你要查询的表的用户,或者把查询的这个视图换成 DBA_TAB_COLUMNS或 ALL_TAB_COLUMNS,并加上OWNER条件 你这个sql明显不对啊,你TABLE_NAME='A' ,意思就是查名字为'A'这一个字母的表, with as 不是临时表,它只是个子查询,没有创建实体对象,因此无法在静态视图中查询相关信息,如果要尝试获取任意查询sql的字段,可以使用以下sql
以上sql就是针对下面这个sql获取字段名 原理就是取一行数据转游标转xml,获取xml的根标签。 另外,还可以通过调用dbms_sql包来获取sql中的字段名称 题主有点离谱了,字段名里怎么会带逗号括号这种东西,这种保留符号会导致各种异常,一般都用下划线。
这个自定义函数"unistr_xml"我就不贴代码了,原理就是解析字符串,正则匹配、替换、解码 这题还没采纳呀?今天我在复刻数据库内置程序的时候发现了个好玩意,可以解决xml修改符号的问题
|
| LINK:https://ask.csdn.net/questions/7621605?answer=53652476 |



| SOURCE:CSDN_ASK |
| ASK_ID:7621596 |
| ANSWER_ID:53652473 |
| TITLE:oracle最大连接数是各个用户共用吗? |
| ANSWER: 如果你说的是processes,这个的确是总进程数,但不要忘了数据库自己也是有后台进程的,你可以观察一下v$process这个视图,建议自己动手在测试环境模拟一下看看效果,注意先提前预留好足够多数量,别让后台进程都起不来了 |
| LINK:https://ask.csdn.net/questions/7621596?answer=53652473 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621485 |
| ANSWER_ID:53652465 |
| TITLE:oracle存储过程列转行问题 |
| ANSWER: 为啥要用存储过程去创建个视图呢?直接用pivot和unpivot不就好了么? 转回去 |
| LINK:https://ask.csdn.net/questions/7621485?answer=53652465 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621430 |
| ANSWER_ID:53652207 |
| TITLE:关于Mysql8 FULL_GROUP_BY的问题 |
| ANSWER: 像你上面这个语句,正确的写法应该是 另外这个报错"ERROR 1046 (3D000): No database selected"是没有选择数据库 |
| LINK:https://ask.csdn.net/questions/7621430?answer=53652207 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621354 |
| ANSWER_ID:53652204 |
| TITLE:MySQL server is running with the --secure-file-priv option so it cannot execute this statement |
| ANSWER: 改成这样试试 或者 注意等号前后有空格 |
| LINK:https://ask.csdn.net/questions/7621354?answer=53652204 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621410 |
| ANSWER_ID:53652187 |
| TITLE:原数据每行的数字大小顺序混乱,通过行专列VOL升序,转回行 数据出错,请专家看看 |
| ANSWER: 这题我一看就感觉不对劲,你unpivot转一次又pivot转回去,真能得到这个样子的数据? Using PIVOT and UNPIVOT - SQL Server | Microsoft Docs Transact-SQL reference for PIVOT and UNPIVOT relational operators. Use these operators on SELECT statements to change a table-valued expression into another table. https://docs.microsoft.com/en-us/sql/t-sql/queries/from-using-pivot-and-unpivot?view=sql-server-ver15 对于sqlserver来说,pivot里in的值是要打中括号的 下面是实测截图
你用原列,怎么转都会转回去,我把你的sql 的for 改了,重新定义列 实测截图
|
| LINK:https://ask.csdn.net/questions/7621410?answer=53652187 |


| SOURCE:CSDN_ASK |
| ASK_ID:7621289 |
| ANSWER_ID:53652159 |
| TITLE:怎么清空表结构并且保留日志 |
| ANSWER: 你说的保留日志是什么日志? |
| LINK:https://ask.csdn.net/questions/7621289?answer=53652159 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621281 |
| ANSWER_ID:53652156 |
| TITLE:Oracle如何处理复杂不规范的时间字符串 |
| ANSWER: 写个函数函数,使用to_date穷举所有能看到的日期格式,函数处理中,对于某一种格式转换正常就return,否则就尝试下一种格式,直到所有格式找完都无法转化,就return个空 |
| LINK:https://ask.csdn.net/questions/7621281?answer=53652156 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621161 |
| ANSWER_ID:53651833 |
| TITLE:pl/sql两个窗口显示不一 |
| ANSWER: 没遇到过这种情况,能不能在两个窗口执行后,分别把程序整个界面截一下图看看, |
| LINK:https://ask.csdn.net/questions/7621161?answer=53651833 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620960 |
| ANSWER_ID:53651805 |
| TITLE:前台传一个字符串后台转为sql语句 |
| ANSWER: 为啥直接传字符串啊,传对应的参数不好么。 |
| LINK:https://ask.csdn.net/questions/7620960?answer=53651805 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621065 |
| ANSWER_ID:53651793 |
| TITLE:写mysql语句时报错 有人看看问题出在哪里吗 |
| ANSWER: "今天"这个字段是什么类型? |
| LINK:https://ask.csdn.net/questions/7621065?answer=53651793 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621186 |
| ANSWER_ID:53651786 |
| TITLE:已经安装成功了tushare,但是还是出现了No module named 'tushare' |
| ANSWER: 检查下本地是不是有多个python环境,比如Anaconda |
| LINK:https://ask.csdn.net/questions/7621186?answer=53651786 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620869 |
| ANSWER_ID:53651767 |
| TITLE:Sqlserver触发器语句转换成MySql语句 |
| ANSWER: 第一个触发器改成before,用old.sclno 来删Stu_Scl和Scl_Maj就好了 |
| LINK:https://ask.csdn.net/questions/7620869?answer=53651767 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620872 |
| ANSWER_ID:53651751 |
| TITLE:安装数据库遇到这种问题怎么解决? |
| ANSWER: 安装器只能同时打开一个,你去任务管理器看下是不是安装程序没退出,没退出就关闭进程; |
| LINK:https://ask.csdn.net/questions/7620872?answer=53651751 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620931 |
| ANSWER_ID:53651744 |
| TITLE:数据库用子查询查出生产部刘姓员工的详细工资情况 |
| ANSWER: 这题貌似重复了 就这?为啥要用子查询?把部门和员工放子查询先检索出id?? |
| LINK:https://ask.csdn.net/questions/7620931?answer=53651744 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620953 |
| ANSWER_ID:53651738 |
| TITLE:关于#数据库#的问题,如何解决? |
ANSWER:就这?为啥要用子查询?把部门和员工放子查询先检索出id?? |
| LINK:https://ask.csdn.net/questions/7620953?answer=53651738 |
| SOURCE:CSDN_ASK |
| ASK_ID:7621009 |
| ANSWER_ID:53651724 |
| TITLE:MYSQL把两个字段组合成对象数组 |
| ANSWER: 以下sql在mysql8.0测试通过,mysql是支持json处理的,使用原生json效率会比字符串拼接要高,而且可以避免字符串中存在json保留符号导致生成的json字符串无法被解析的问题
|
| LINK:https://ask.csdn.net/questions/7621009?answer=53651724 |

| SOURCE:CSDN_ASK |
| ASK_ID:7620898 |
| ANSWER_ID:53651700 |
| TITLE:sql TIME_ZONE与DBTIMEZONE分别代表什么? |
| ANSWER: LOCALTIMESTAMP返回会话时区中的当前日期和时间TIMESTAMP LOCALTIMESTAMP https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/LOCALTIMESTAMP.html ALTER SESSION https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/ALTER-SESSION.html#GUID-DC7B8CDD-4F89-40CC-875F-F70F673711D4 |
| LINK:https://ask.csdn.net/questions/7620898?answer=53651700 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620875 |
| ANSWER_ID:53651687 |
| TITLE:sql怎么查看nls_date_format |
| ANSWER: 在pl/sql developer中要执行你这条命令的话,请打开一个命令窗口来执行
|
| LINK:https://ask.csdn.net/questions/7620875?answer=53651687 |


| SOURCE:CSDN_ASK |
| ASK_ID:7621135 |
| ANSWER_ID:53651676 |
| TITLE:关于Oracle的trunc函数 |
| ANSWER: 工具显示的问题,命令窗口会对显示内容进行截断,你把别名设置长一点他就显示出来了
正常sql窗口不会有这个问题
|
| LINK:https://ask.csdn.net/questions/7621135?answer=53651676 |


| SOURCE:CSDN_ASK |
| ASK_ID:7620611 |
| ANSWER_ID:53650948 |
| TITLE:关于nb3类文件的查看 |
| ANSWER: Navicat还原nb3备份文件步骤_fzt12138的博客-CSDN博客_mysql nb3 还原 新建数据库打开数据库备份复制粘贴备份文件还原备份 https://blog.csdn.net/fzt12138/article/details/104967740 |
| LINK:https://ask.csdn.net/questions/7620611?answer=53650948 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620477 |
| ANSWER_ID:53650939 |
| TITLE:oracle数据库行转列问题 |
| ANSWER: 怎么把数据纵向输出?-大数据-CSDN问答 CSDN问答为您找到怎么把数据纵向输出?相关问题答案,如果想了解更多关于怎么把数据纵向输出? oracle、sql、有问必答 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7613354?answer=53640572&spm=1001.2014.3001.5504
|
| LINK:https://ask.csdn.net/questions/7620477?answer=53650939 |

| SOURCE:CSDN_ASK |
| ASK_ID:7620458 |
| ANSWER_ID:53650935 |
| TITLE:Oracle数据连续时取连续值的第一个 |
| ANSWER: 这题有意思,我本来打算用开窗函数来做,但是想想用迭代思路更清晰,就凑了个迭代的sql出来,数据结果是对的,但应该还可以优化
|
| LINK:https://ask.csdn.net/questions/7620458?answer=53650935 |

| SOURCE:CSDN_ASK |
| ASK_ID:7620418 |
| ANSWER_ID:53650853 |
| TITLE:oracle中使用<>的效率 |
| ANSWER: 如果要优化sql,麻烦把完整sql、各个表的数据量、统计信息、索引及分区情况、执行计划都贴出来, |
| LINK:https://ask.csdn.net/questions/7620418?answer=53650853 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620104 |
| ANSWER_ID:53650579 |
| TITLE:创建了视图往里面插入数据无法插入 |
| ANSWER: 上一个题问怎么用两个表创建视图,这个题就问怎么往视图里插数据,这是想偷懒结果偷不成了吧。 楼上几位已经说得差不多了,你这两个表的视图的确是不能直接插入数据的,数据库不知道你打算怎么把数据放到那两个表里面去,普通视图只是一个查询sql,本身并不包含数据,所有想对非"单一表且不聚合"视图的修改必须去修改原始表。 当然,如果你数据库不是mysql而是oracle,倒是可以在视图上创建 instead of的触发器,去实现对视图插入数据的动作转化成分别插入两个表的动作 |
| LINK:https://ask.csdn.net/questions/7620104?answer=53650579 |
| SOURCE:CSDN_ASK |
| ASK_ID:7620341 |
| ANSWER_ID:53650510 |
| TITLE:sqlserver 获取某段时间每天数据的前10行数据 |
| ANSWER: 用开窗函数做分组排序就行了 |
| LINK:https://ask.csdn.net/questions/7620341?answer=53650510 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618447 |
| ANSWER_ID:53649475 |
| TITLE:请问app怎么把前端的图片(还有background-image)存储到后台数据库里面并且能够显示出来 |
| ANSWER: 大多数项目里,不会把图片的二进制数据直接存mysql里的,一般就存个链接,图片实际放到别的地方了,比如各种云,或者存到专门的文件数据库比如mongodb。 |
| LINK:https://ask.csdn.net/questions/7618447?answer=53649475 |
| SOURCE:CSDN_ASK |
| ASK_ID:7619215 |
| ANSWER_ID:53649472 |
| TITLE:请求支援,SQL server怎末算出罐数一列数值的和 |
| ANSWER: 我怀疑你是不是问题没描述清? |
| LINK:https://ask.csdn.net/questions/7619215?answer=53649472 |
| SOURCE:CSDN_ASK |
| ASK_ID:7619339 |
| ANSWER_ID:53649469 |
| TITLE:安装mysql是这个页面如何解决? |
| ANSWER: 点右边的add添加数据库相关组件继续安装 |
| LINK:https://ask.csdn.net/questions/7619339?answer=53649469 |
| SOURCE:CSDN_ASK |
| ASK_ID:7619678 |
| ANSWER_ID:53649466 |
| TITLE:mysql想法实现问题 |
| ANSWER: 楼上include_iostream_ 说得不错,但关于第一点要纠正下,翻译数据当然是要放数据库里(不一定是mysql),因为这个东西会不断扩充及修正,没有什么比一句insert或者update更简单的了,前端或者后端是不可能在代码里固定好那么多翻译的数据的。 |
| LINK:https://ask.csdn.net/questions/7619678?answer=53649466 |
| SOURCE:CSDN_ASK |
| ASK_ID:7619511 |
| ANSWER_ID:53649455 |
| TITLE:SQL 如何把行变成列,而且每列对应的结果要减去前面累积的和。 |
| ANSWER: 如果是oracle数据库,可以用pivot; 另外,如果要写得不套那么多层的话,需要数据库支持开窗函数或者递归,比如sqlserver2017、mysql8、oracle等数据库。 当然,既然前面这个流程表有固定的值,那么不介意再添加一列,第5行等于10、第4行等于18、第3行等于23,以此类推,这样可以让sql得到简化 先来个oracle的
|
| LINK:https://ask.csdn.net/questions/7619511?answer=53649455 |

| SOURCE:CSDN_ASK |
| ASK_ID:7619676 |
| ANSWER_ID:53649422 |
| TITLE:SQL如何在一条flashback语句中恢复多个被删除的表? |
| ANSWER: 闪回表的语法 根据语法来看,表级闪回是不支持多个表的,只能一个一个表来;如果是要全库闪回,请执行库级的闪回 Oracle Flashback(闪回) 详解_执笔天涯的博客-CSDN博客_flashback oracle 通常我们对数据库进行了误操作时, 需要把数据库Rollback到之前的版本.一个常用的方法就是使用日志来进行数据库恢复. 这个方法虽然强大有效, 但是花费时间等成本高.例如当我们只是误提交了1个delete语句, 丢失了删除行的数据时, 如果我们执行数据库恢复的话, 就需要断开当前所有server processes, 甚至需要关闭数据库,相当于暂停了所有的生产活动.而且使用日志恢复的话, 还往往... https://blog.csdn.net/m0_37797282/article/details/80249072 Flashback可以分为三个级别: 1.Database Level 2.Table level 3.Transaction level |
| LINK:https://ask.csdn.net/questions/7619676?answer=53649422 |
| SOURCE:CSDN_ASK |
| ASK_ID:7619607 |
| ANSWER_ID:53649357 |
| TITLE:navicat导入sql文件报错,请教一下这是为什么 |
| ANSWER: 不同数据库的语法不是完全兼容的,如果你要把数据导入到mysql数据库里,先得打开这个文件看看语法是否符合mysql规范 |
| LINK:https://ask.csdn.net/questions/7619607?answer=53649357 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618980 |
| ANSWER_ID:53648572 |
| TITLE:创建存储过程,查询指定操作员所具有的功能权限 怎么用数据库的代码实现呢 |
| ANSWER: 你上一个问题,我建议你检查一下sql的准确性和表里面的数据,看看是不是的确应该查不到 另外,你过程里要使用的话,应该还要加一个条件,把传入参数带进去,要不然你不论传什么参数都会显示同样的内容 |
| LINK:https://ask.csdn.net/questions/7618980?answer=53648572 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618526 |
| ANSWER_ID:53648533 |
| TITLE:mysql不知道怎么回事打不开了,数据库的Navicat也没法用 |
| ANSWER: 挂了, |
| LINK:https://ask.csdn.net/questions/7618526?answer=53648533 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618804 |
| ANSWER_ID:53648527 |
| TITLE:悬赏:MSSQL 表连接长语句性能优化案例求解答? |
| ANSWER: 一:最显眼的,把union 改成 union all试试 |
| LINK:https://ask.csdn.net/questions/7618804?answer=53648527 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618667 |
| ANSWER_ID:53648456 |
| TITLE:SQL Sever2012与2019的差异性 |
| ANSWER: 一般这些信息在官网上都有发布,但2012实在太老了,最新的页面只有2016、2017、2019的比较 SQL Server 2019 - 对比 | Microsoft 查看 Microsoft SQL Server 版本以比较并找出符合数据平台需求的正确版本。 https://www.microsoft.com/zh-cn/sql-server/sql-server-2019-comparison?rtc=1 更多内容可在官网查阅 |
| LINK:https://ask.csdn.net/questions/7618667?answer=53648456 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618870 |
| ANSWER_ID:53648418 |
| TITLE:使用存储过程向oracle中插入数据时报错 Invalid value for field 'DRUG_USE_DAYS' |
| ANSWER: 请贴出你的代码,从这句报错中只能得到一个信息就是 ,对于'DRUG_USE_DAYS'这个字段是无效的值 |
| LINK:https://ask.csdn.net/questions/7618870?answer=53648418 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618509 |
| ANSWER_ID:53647471 |
| TITLE:mysql 的exists关键字 |
| ANSWER: 如果不存在,才创建。 |
| LINK:https://ask.csdn.net/questions/7618509?answer=53647471 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618363 |
| ANSWER_ID:53647292 |
| TITLE:连接MySQL这样写有什么问题吗? |
| ANSWER: 数据库用户权限不对,请检查该用户的权限,比如host及密码 |
| LINK:https://ask.csdn.net/questions/7618363?answer=53647292 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618364 |
| ANSWER_ID:53647286 |
| TITLE:SQl1张表对多张结构不同的表,如何查询? |
| ANSWER: 这数据量不大,而且数据也比较单一,完全没必要设计那么多表。 |
| LINK:https://ask.csdn.net/questions/7618364?answer=53647286 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618132 |
| ANSWER_ID:53647217 |
| TITLE:⭕️⭕️百度网盘卸载不干净😭 |
| ANSWER: 删掉下面这个注册表项,然后重启电脑,
|
| LINK:https://ask.csdn.net/questions/7618132?answer=53647217 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618266 |
| ANSWER_ID:53647204 |
| TITLE:C#数据库已连接但无法读取数据库内容 |
| ANSWER: 学会单步调试代码,看参数及变量的变化是否符合预期 |
| LINK:https://ask.csdn.net/questions/7618266?answer=53647204 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618062 |
| ANSWER_ID:53647200 |
| TITLE:创建存储过程,查询指定操作员所具有的功能权限。指定操作员姓名 ,查询过程与第一个查询相同 |
| ANSWER: 你这又不是个函数,当然没有结果显示呀。 |
| LINK:https://ask.csdn.net/questions/7618062?answer=53647200 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618250 |
| ANSWER_ID:53647191 |
| TITLE:如何用sql来回答这个问题 |
| ANSWER: 你sqlserver教程的创建数据库那篇,把创建数据库的示例代码拿出来改改就好了 |
| LINK:https://ask.csdn.net/questions/7618250?answer=53647191 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618276 |
| ANSWER_ID:53647189 |
| TITLE:oracle11g安装报错乱码 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7618276?answer=53647189 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618157 |
| ANSWER_ID:53647057 |
| TITLE:Navicat 连接SQL sever数据库后,对表重命名后一导入数据就提示“对象名无效” |
| ANSWER: 可能是你导入文件里写的是insert命令,这个建议把你导入数据文件里的表名改成新的表,或者用旧的表名导入完后再去修改表名 |
| LINK:https://ask.csdn.net/questions/7618157?answer=53647057 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618172 |
| ANSWER_ID:53647053 |
| TITLE:子查询中带有count然后报不是单分组函数的问题 |
| ANSWER: 能只查一次表就不要查两次 count某个字段的时候,对于空值是不会进行计数统计的 题主说要按条件进行统计 此处的case when 对于a.a=1都会转化成一个非空的值,比如1,当然也可以是其他值,然后不满足此条件的都会返回空,结合上一点提到的,count字段只会对非空值进行统计 |
| LINK:https://ask.csdn.net/questions/7618172?answer=53647053 |
| SOURCE:CSDN_ASK |
| ASK_ID:7617859 |
| ANSWER_ID:53647045 |
| TITLE:请问一下对数据库或者是SQL的优化有哪些 |
| ANSWER: 云和恩墨售前技术指南丛书 -《理解数据库性能》.pdf - 墨天轮文档 如何理解当下的时代,到数据库的性能这个领域的关联关系?以及如何全面的看待数据库性能,制定有效的提升数据库性能的方案和选择正确的产品,避免陷入局部最优的方案中?这本运维恩墨内部售前丛书,带你以终为始的理解数据库性能。 https://www.modb.pro/doc/52858 |
| LINK:https://ask.csdn.net/questions/7617859?answer=53647045 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618051 |
| ANSWER_ID:53646815 |
| TITLE:将excel表的某一列数据导入数据库 |
| ANSWER: 创建一个导入临时表,先把数据导入到临时表 |
| LINK:https://ask.csdn.net/questions/7618051?answer=53646815 |
| SOURCE:CSDN_ASK |
| ASK_ID:7618040 |
| ANSWER_ID:53646796 |
| TITLE:sql语句中如何将查询没有的记录也显示在查询结果中,显示为0 |
| ANSWER: 说下数据库类型及版本,这个最好是用递归或者表函数来构造一个虚拟表,但有的数据库不支持。 |
| LINK:https://ask.csdn.net/questions/7618040?answer=53646796 |
| SOURCE:CSDN_ASK |
| ASK_ID:7617826 |
| ANSWER_ID:53646561 |
| TITLE:orcale中,select后面的字段没有全在group by后面,但是编译不报错 |
| ANSWER: 因为你上面声明了与字段名同名的变量,导致sql里查的不是表里面的字段名,而是你的变量了,变量是不需要跟在group by 后面的,你把上面这三个声明的变量删掉再编译和执行一下看看 改成你这样后,执行会报错,下面是实测截图
|
| LINK:https://ask.csdn.net/questions/7617826?answer=53646561 |

| SOURCE:CSDN_ASK |
| ASK_ID:7617824 |
| ANSWER_ID:53646546 |
| TITLE:SQL把同一个人的不同字段在同一行显示出来 |
| ANSWER: 说下数据库类型,不同的数据库有不同的行列转换方式 题主说是mysql 5.7,那就用下面这个方式吧 |
| LINK:https://ask.csdn.net/questions/7617824?answer=53646546 |
| SOURCE:CSDN_ASK |
| ASK_ID:7617721 |
| ANSWER_ID:53646283 |
| TITLE:Mysql数据库用户余额和购物车在两个表中,如何用用户余额减去求出来的购物车表里的商品总金额啊 |
| ANSWER: 这个表结构设计是不是有问题?你怎么确定购物车里的东西是哪个用户的?按总金额匹配?难道就不会有两个人买了同样金额的东西么? |
| LINK:https://ask.csdn.net/questions/7617721?answer=53646283 |
| SOURCE:CSDN_ASK |
| ASK_ID:7617202 |
| ANSWER_ID:53645366 |
| TITLE:oracle定义一个异常,并将名字和错误代码绑定 |
ANSWER:既然是课后题,那课堂上应该教了啊,这就一个plsql代码里的基本语法而已 |
| LINK:https://ask.csdn.net/questions/7617202?answer=53645366 |
| SOURCE:CSDN_ASK |
| ASK_ID:7617193 |
| ANSWER_ID:53645360 |
| TITLE:sql server,电表每小时记录一次当前数值加到表中,算出每个电表每小时、每天、每周的用电量,每层电表每小时、每天、每周用电量 |
| ANSWER: 把你最后要展现的数据格式列出来一下,看看是要几张结果表,分别有哪些字段 给你一个这样的sql应该就够了,其他的都是基于这个数据去做汇总
|
| LINK:https://ask.csdn.net/questions/7617193?answer=53645360 |

| SOURCE:CSDN_ASK |
| ASK_ID:7617064 |
| ANSWER_ID:53645262 |
| TITLE:Qracle数据库用字符串时间格式查询报错 |
| ANSWER: 你这样查会不会报错?
|
| LINK:https://ask.csdn.net/questions/7617064?answer=53645262 |

| SOURCE:CSDN_ASK |
| ASK_ID:7617030 |
| ANSWER_ID:53645247 |
| TITLE:python manage.py makemigrations 一运就这样子了 不知道哪里写错了 |
| ANSWER: Django2.1 include()函数报错'provide the namespace argument to include() instead.' % len(arg)_Lizune-CSDN博客 《Python编程:从入门到实践》项目三 Web应用程序书中原来的程序from django.conf.urls import include, urlfrom django.contrib import adminurlpatterns = [ url(r'^admin/', include(admin.site.urls)), url(r'', include(... https://blog.csdn.net/m0_38059875/article/details/82793269 |
| LINK:https://ask.csdn.net/questions/7617030?answer=53645247 |
| SOURCE:CSDN_ASK |
| ASK_ID:7617022 |
| ANSWER_ID:53645109 |
| TITLE:请问如何让这两个表连接一起 |
| ANSWER: 重复问题,这个结构应该能看懂吧?把一个查询用括号扩起来就能当一张表用了 |
| LINK:https://ask.csdn.net/questions/7617022?answer=53645109 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616942 |
| ANSWER_ID:53645001 |
| TITLE:这两个内容无论如何也连接不了 |
| ANSWER: 最简单的改法, |
| LINK:https://ask.csdn.net/questions/7616942?answer=53645001 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616907 |
| ANSWER_ID:53644978 |
| TITLE:关于sqlserver查询条件相同,返回结果不同 |
| ANSWER: 不能简单的判断哪个快,要看数据量和磁盘存储分布的。另外,这与A是实体表还是视图也是有关系的。 |
| LINK:https://ask.csdn.net/questions/7616907?answer=53644978 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616832 |
| ANSWER_ID:53644824 |
| TITLE:Linux无法更改到 var/user1目录:没有那个文件或目录。怎么搞呀 |
| ANSWER: 这只是提示你没有那个目录,不影响其他操作。 |
| LINK:https://ask.csdn.net/questions/7616832?answer=53644824 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616851 |
| ANSWER_ID:53644811 |
| TITLE:请问哪里错了?555~ |
| ANSWER: 麻烦把代码放在代码块里,你这发出来的代码看不出来结构。 |
| LINK:https://ask.csdn.net/questions/7616851?answer=53644811 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616852 |
| ANSWER_ID:53644800 |
| TITLE:导入excel数据被自动四舍五入没有小数点咋解决 |
| ANSWER: 你看下你对应的接收参数类型是不是设置成整型了 |
| LINK:https://ask.csdn.net/questions/7616852?answer=53644800 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616539 |
| ANSWER_ID:53644564 |
| TITLE:能插入一个左连接后的表么,具体语句应该怎么样写呢 |
| ANSWER: 如果是oracle,倒可以通过insert all实现,但mysql没有这个语法。 |
| LINK:https://ask.csdn.net/questions/7616539?answer=53644564 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616387 |
| ANSWER_ID:53644551 |
| TITLE:Mysql,三表查询求解答面试遇到的 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7616387?answer=53644551 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616702 |
| ANSWER_ID:53644520 |
| TITLE:关于#oracle#的问题,请各位专家解答!想通过自定义一个函数实现select getdate('年') from dual,把多行多列结果都呈现出来 |
| ANSWER: oracle的函数,使用select的方式,只能返回"一个值",或者说一个字段。你如果想包含多个字段的信息,要么把多个字段的内容合到一个字段里去,要么就要select多次这个函数。 我觉得你可能还是没搞清楚项目经理的意思,既然你执意要所谓的多行多列,那我就写个函数把,不过我敢有很大的把握肯定这个函数用不上 实测截图
|
| LINK:https://ask.csdn.net/questions/7616702?answer=53644520 |

| SOURCE:CSDN_ASK |
| ASK_ID:7616382 |
| ANSWER_ID:53643917 |
| TITLE:samba共享,ubuntu能访问windows,但是windows访问不了Ubuntu |
| ANSWER: 你看下你安装的samba是1.0版本还是2.0版本 |
| LINK:https://ask.csdn.net/questions/7616382?answer=53643917 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616377 |
| ANSWER_ID:53643908 |
| TITLE:就是一个pandas的问题。求解答 |
| ANSWER: DataFrame对象没有"values1"这个东西 |
| LINK:https://ask.csdn.net/questions/7616377?answer=53643908 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616324 |
| ANSWER_ID:53643899 |
| TITLE:我的WordPress网页中需要实现 点击按钮出来联系框弹窗的功能。 |
ANSWER:
https://wordpress.org/plugins/modal-window/#how%20to%20open%20a%20modal%20window%20clicking%20on%20the%20link%3F |
| LINK:https://ask.csdn.net/questions/7616324?answer=53643899 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616329 |
| ANSWER_ID:53643893 |
| TITLE:继续点就返回了 我要写30个人的 |
| ANSWER: 把代码拉出来溜溜 |
| LINK:https://ask.csdn.net/questions/7616329?answer=53643893 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616331 |
| ANSWER_ID:53643881 |
| TITLE:是否有办法将输入的一串数字就以数字的形式保存在文件中? |
| ANSWER: 你把它转换成文本,以文本方式写入应该就不会乱码了。因为你是用文本编辑器打开的这个文件,当然只能识别文本了 |
| LINK:https://ask.csdn.net/questions/7616331?answer=53643881 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616342 |
| ANSWER_ID:53643878 |
| TITLE:安装不了Python程序 |
| ANSWER: 另外可能要手动配置环境变量 |
| LINK:https://ask.csdn.net/questions/7616342?answer=53643878 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616316 |
| ANSWER_ID:53643874 |
| TITLE:python程序设计qwq help!! |
| ANSWER: python反转list的三种方法_米尔大哥的博客-CSDN博客_python 列表反向 现有a = [1,2,3,4,5],现需要进行对a进行反转方法1:list(reversed(a)) reversed(a)返回的是迭代器,所以前面加个list转换为list方法2:sorted(a,reverse=True)方法3:a[: :-1] 其中[::-1]代表从后向前取值,每次步进值为1... https://blog.csdn.net/qq_37969201/article/details/80406726 统计字母个数用正则模块的findall找到所有字母作为一个list,再计算这个list的长度 filter - 廖雪峰的官方网站 研究互联网产品和技术,提供原创中文精品教程 https://www.liaoxuefeng.com/wiki/1016959663602400/1017404530360000 如果这题质量要高的话,其实是考的算法效率,有些数字是可以直接跳过的,比如所有偶数,至于其他更高级的,你估计学不来了吧 |
| LINK:https://ask.csdn.net/questions/7616316?answer=53643874 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616335 |
| ANSWER_ID:53643869 |
| TITLE:请问如何解析复杂sql字符串中的所有表名,在不连接数据库的情况下? |
| ANSWER: 当然java什么的都可以,用Antlr4可以构建适用于多种语言的语法解析器,看你熟悉哪种语言,就用哪种,可以在网上搜索相关资料,或者参考这篇文章 【python】使用Antlr4实现识别sql中的表或视图名_DarkAthena的博客-CSDN博客_antlr4 sql 前言先上成果预览图吧作为一个数据库sql开发者,肯定有很多人和我一样,想要有一个工具,能传入任意sql,解析出sql中的所有表。我之前有一篇文章【AIO】将任意查询sql转换成带远程数据库DBLINK的sql 中就提到了,使用纯文本硬解析会存在很多不确定因素,比如oracle新版本就添加了新的sql语法,有些场景太难处理,而解析器则只需要配置好规则,并且标准化规则的语法,那么扩展性就很强了。antlr4 https://github.com/antlr/antlr4Antlr这个老早就有了,如今 https://darkathena.blog.csdn.net/article/details/120694597 |
| LINK:https://ask.csdn.net/questions/7616335?answer=53643869 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616322 |
| ANSWER_ID:53643860 |
| TITLE:输出excel怎么去掉表头和行号? |
| ANSWER: 先把你输出的代码贴出来,再看怎么改你的代码 |
| LINK:https://ask.csdn.net/questions/7616322?answer=53643860 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616303 |
| ANSWER_ID:53643842 |
| TITLE:请问如何在oracle数据库中发送ssl的smtp邮件,不要调Java的 |
| ANSWER: 【AIO】使用ORACLE数据库存储过程发送加密email(SSL)_DarkAthena的博客-CSDN博客 之前说过了ORACLE可以使用存储过程来发送未加密的smtp协议邮件,但是现在越来越多邮箱服务商要求强制使用ssl加密,按照前一篇文章的方式,是无法发送的,因此这一篇教大家如何使用ORACLE存储过程来发送带ssl加密的email。文章分以下几个部分一、获取邮件SSL证书文件二、把证书添加到oracle 钱夹(wallet)三、发送邮件的方法一、获取邮件ssl证书文件#### 方法一:使用浏览器获取证书(以360极速浏览器为例)打开对应邮箱的网页客户端,例如QQ邮箱,浏览器会显示一把锁,如图 https://darkathena.blog.csdn.net/article/details/120598115
|
| LINK:https://ask.csdn.net/questions/7616303?answer=53643842 |

| SOURCE:CSDN_ASK |
| ASK_ID:7616266 |
| ANSWER_ID:53643831 |
| TITLE:python怎么画出随机个数,随机高宽的矩形和三角形 |
| ANSWER: 定义多个随机数 |
| LINK:https://ask.csdn.net/questions/7616266?answer=53643831 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616267 |
| ANSWER_ID:53643827 |
| TITLE:mysql模糊查询失效 |
| ANSWER: LIMIT 1,10 表示从第2行开始检索,一共检索10条记录,即查询第2到11条记录,你这表里只有2条记录,带上这个限制,那么不管怎样都只会查到1条数据 |
| LINK:https://ask.csdn.net/questions/7616267?answer=53643827 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616088 |
| ANSWER_ID:53643818 |
| TITLE:这个图片文件怎么都删不掉怎么办 |
| ANSWER: 刷新一下桌面或者重启电脑如果还在的话,建议使用某些安全软件的文件粉碎工具 |
| LINK:https://ask.csdn.net/questions/7616088?answer=53643818 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616090 |
| ANSWER_ID:53643815 |
| TITLE:这是招人是培训吗?问一下 |
| ANSWER: 这。。。。。看上去不像正经公司缺开发的情况。。。反正如果要收你钱就不搞了嘛 |
| LINK:https://ask.csdn.net/questions/7616090?answer=53643815 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616103 |
| ANSWER_ID:53643808 |
| TITLE:虚拟环境创建失败,怎么解决? |
| ANSWER: 没有配置代理,那个url在国内无法访问 win10通过Anaconda安装tensorflow过程中遇到的 An HTTP error occurred和ConnectTimeout的 问题_liumoude6的博客-CSDN博客 通过我的上一篇博客的安装过程中,有些网络会存在 An HTTP error occurred when trying to retrieve this URL. HTTP errors are often intermittent, and a simple retry will get you on your way. ConnectTimeout(MaxRetryError("HTT... https://blog.csdn.net/liumoude6/article/details/82496535 |
| LINK:https://ask.csdn.net/questions/7616103?answer=53643808 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616197 |
| ANSWER_ID:53643796 |
| TITLE:win10,送的正版office2019,激活后才不到两个月就显示没激活?怎么办呀? |
| ANSWER: 找售后,售后不解决就赔钱。 |
| LINK:https://ask.csdn.net/questions/7616197?answer=53643796 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616206 |
| ANSWER_ID:53643784 |
| TITLE:帮我看看我这个大蜘蛛杀毒软件的防火墙出什么问题了 |
| ANSWER: 没啥问题,这不正常网络使用么 |
| LINK:https://ask.csdn.net/questions/7616206?answer=53643784 |
| SOURCE:CSDN_ASK | ||||||||
| ASK_ID:7616230 | ||||||||
| ANSWER_ID:53643779 | ||||||||
TITLE:INSERT INTO auth_permission VALUES (1, 'Can add log entry', 1, 'add_logentry');含义 | ||||||||
| ANSWER: 往auth_permission这个表里插入一行数据
上面就是显示的你执行这个插入动作后查询这张表的效果, | ||||||||
| LINK:https://ask.csdn.net/questions/7616230?answer=53643779 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616118 |
| ANSWER_ID:53643658 |
| TITLE:为什么账号对密码错能进入登陆失败提示页,账号错却会直接报错? |
| ANSWER: 貌似没有 getUserByUname 查不出数据时的异常处理 |
| LINK:https://ask.csdn.net/questions/7616118?answer=53643658 |
| SOURCE:CSDN_ASK |
| ASK_ID:7616016 |
| ANSWER_ID:53643653 |
| TITLE:如何解决导出的excel的数据有科学计数法的问题? |
| ANSWER: 如果有小数,就傻了 |
| LINK:https://ask.csdn.net/questions/7616016?answer=53643653 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615870 |
| ANSWER_ID:53643501 |
| TITLE:遇到奇葩问题:用sqoop 把mysql导入hive报错,有些表导入正常,有些表报错 |
| ANSWER: 你源数据是datetime类型,但目标表却是string类型。要么改目标表字段类型,要么导入的sql中对日期进行格式化处理转换成字符串类型 |
| LINK:https://ask.csdn.net/questions/7615870?answer=53643501 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615818 |
| ANSWER_ID:53643364 |
| TITLE:一条关于数据库的问题 |
| ANSWER: 对两个表分别求和,作为两个子查询,然后再将两个子查询join起来,注意要对某个商品可能不存在于某张表的处理,所以此时应该还要有一个完整的商品档案表作为主表,去左连接这两个子查询 |
| LINK:https://ask.csdn.net/questions/7615818?answer=53643364 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615778 |
| ANSWER_ID:53643361 |
| TITLE:mysql 一个库里两个表一部分数据,插入到另一个库里两个表中,如何处理外键? |
| ANSWER: 先插a表,不要插id字段,让id自动生成,然后获取刚刚插入的这笔数据的id的值,把要插b表数据中的a_id替换成刚刚获取的值后,再插入b表。 |
| LINK:https://ask.csdn.net/questions/7615778?answer=53643361 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615718 |
| ANSWER_ID:53643356 |
| TITLE:关于#报表#的问题:水晶报表连接官网文件就出错,连接Oracle数据库 |
| ANSWER: 你连接的这个xtreme.mdb玩意,肯定不是oracle数据库呀 |
| LINK:https://ask.csdn.net/questions/7615718?answer=53643356 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613795 |
| ANSWER_ID:53643063 |
| TITLE:数据库的一个简单的小问题 |
| ANSWER: 都不知道你表结构,怎么写? |
| LINK:https://ask.csdn.net/questions/7613795?answer=53643063 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615442 |
| ANSWER_ID:53643055 |
| TITLE:关于循环终止条件的问题 |
| ANSWER: 当X是整数时, x>4和x>=5是等价的 |
| LINK:https://ask.csdn.net/questions/7615442?answer=53643055 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615422 |
| ANSWER_ID:53642963 |
| TITLE:mysql,这个问题要怎么搞 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7615422?answer=53642963 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615414 |
| ANSWER_ID:53642959 |
| TITLE:mysql关于这个问题要如何去解决 |
| ANSWER: 是这个意思? |
| LINK:https://ask.csdn.net/questions/7615414?answer=53642959 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615305 |
| ANSWER_ID:53642957 |
| TITLE:oracle数据库的sysdba为何不能执行某些语句? |
| ANSWER: 根据用户名看,你这是多租户可插拔数据库, 另外,那个执行按钮没亮起来,一般是没连上数据库,plsql默认支持多用户连接,你看看下面的连接信息是不是和上面保持一致 |
| LINK:https://ask.csdn.net/questions/7615305?answer=53642957 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615355 |
| ANSWER_ID:53642860 |
| TITLE:Oracle数据库回滚的问题 |
| ANSWER: 用下面这个sql可以查询1个小时前这个表的数据是啥样的,也可以把时间继续往前推,具体能推到多钱,得看数据库设置及相关空间大小 具体操作请自行搜索关键词 oracle 闪回 |
| LINK:https://ask.csdn.net/questions/7615355?answer=53642860 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615250 |
| ANSWER_ID:53642740 |
| TITLE:MySQL:unknown variable 怎么解决 |
| ANSWER: 把路径换一下,别用这种长文件夹又带符号又带中文的 |
| LINK:https://ask.csdn.net/questions/7615250?answer=53642740 |
| SOURCE:CSDN_ASK |
| ASK_ID:7615169 |
| ANSWER_ID:53642738 |
| TITLE:使用Navicat for MySQL出现错误1364,怎样解决 |
| ANSWER: 你这是做了什么操作?麻烦把操作步骤说清楚 |
| LINK:https://ask.csdn.net/questions/7615169?answer=53642738 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614925 |
| ANSWER_ID:53642731 |
| TITLE:sql 数组格式的json字符串,转成in可用的条件怎么实现? |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7614925?answer=53642731 |

| SOURCE:CSDN_ASK |
| ASK_ID:7614923 |
| ANSWER_ID:53642718 |
| TITLE:各位帮我解答一下,下面的问题? |
| ANSWER: 这个sql能在oracle执行呀,有啥问题? |
| LINK:https://ask.csdn.net/questions/7614923?answer=53642718 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614894 |
| ANSWER_ID:53642714 |
| TITLE:oracle关闭回收站有什么效果? |
| ANSWER: 你执行关闭后,再检查一下这个参数看是开还是关,有时候由于存在优先级更高的策略,你修改是不成功的 |
| LINK:https://ask.csdn.net/questions/7614894?answer=53642714 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614834 |
| ANSWER_ID:53642703 |
| TITLE:oracle查询入职年限大于20年的员工信息 |
| ANSWER: 这里先要确定一个问题,是自然年20年,还是简单的36520?是否需要考虑闰年?不满365天但跨了年算不算1年等等情况。 |
| LINK:https://ask.csdn.net/questions/7614834?answer=53642703 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614779 |
| ANSWER_ID:53642421 |
| TITLE:sql Server 触发器如何实现两张表的同一数据进行更新? |
| ANSWER: 创建 DML 触发器 - SQL Server | Microsoft Docs 创建 DML 触发器 https://docs.microsoft.com/zh-cn/sql/relational-databases/triggers/create-dml-triggers?view=sql-server-2017 |
| LINK:https://ask.csdn.net/questions/7614779?answer=53642421 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614731 |
| ANSWER_ID:53642278 |
| TITLE:这也是找到饼干的一种非常真实的方式。在我看来,这与偷饼干非常相似。 |
| ANSWER: 源码都拿到了,那当然就知道怎么计算cookie了,当然必须是完整源码,比如计算过程中使用的私钥也得有。 |
| LINK:https://ask.csdn.net/questions/7614731?answer=53642278 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614802 |
| ANSWER_ID:53642254 |
| TITLE:oracle回收站没找到被删除的数据 |
| ANSWER: 查这个 select * from dba_recyclebin; plsql developer 这里显示有问题,有时候不要太依赖可视化工具 |
| LINK:https://ask.csdn.net/questions/7614802?answer=53642254 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614747 |
| ANSWER_ID:53642250 |
| TITLE:请问怎么用plsql的语句,执行查出来的语句的储存过程 |
| ANSWER: 把查出来的命令当动态sql执行即可 上面我写成了循环, 是方便修改成其他查询条件也能执行 |
| LINK:https://ask.csdn.net/questions/7614747?answer=53642250 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614596 |
| ANSWER_ID:53642105 |
| TITLE:DB2数据库相关!有人能说说嘛 |
| ANSWER: 你确定需求没描述错?不是要整月汇总,而是每月最后一天? |
| LINK:https://ask.csdn.net/questions/7614596?answer=53642105 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614630 |
| ANSWER_ID:53642100 |
| TITLE:oracle xmltype内容只有一个字段,但是量太多,用xmltable解析报错,删成几百个就没问题,如何解决? |
| ANSWER: 你给一小段完整的xml文本出来,我去试试 我做了个测试,模拟25万个记录 可以很快查出结果
根据你这个sql中的 ":auIdParams“来看,应该是使用参数传入,这里容易忽视一个问题,就是varchar2的最大长度只有三万多,简单的字符串传入会导致内容被截断,导致xml校验不通过。 |
| LINK:https://ask.csdn.net/questions/7614630?answer=53642100 |

| SOURCE:CSDN_ASK |
| ASK_ID:7614574 |
| ANSWER_ID:53642002 |
| TITLE:相同年月日的两条数据,只能统计为一次 |
| ANSWER: 首先楼上说的distinct 应该不符合所有场景,从这个结构上来看,会有其他列数据不一样但日期一样的情况。 如果你确定无论关联出来多少台都只算1台的话,那就再对这些求和字段再写个case when ,大于0台算1台,否则为0台 |
| LINK:https://ask.csdn.net/questions/7614574?answer=53642002 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614528 |
| ANSWER_ID:53641979 |
| TITLE:string_agg这个合并数据怎么设置分隔符 |
| ANSWER: b2c_owner_user是用户自定义包,网上找不到的,你要打开一下这个包,看string_agg要传入什么参数以及参数类型是什么 |
| LINK:https://ask.csdn.net/questions/7614528?answer=53641979 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614497 |
| ANSWER_ID:53641938 |
| TITLE:mysql子查询的子查询无法使用外层参数问题 |
| ANSWER: 你套了两层括号,它认不到了,删掉一层即可 注:以上sql只针对报错问题解决,不表示认可此sql逻辑,也未进行优化 |
| LINK:https://ask.csdn.net/questions/7614497?answer=53641938 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614470 |
| ANSWER_ID:53641934 |
| TITLE:Ubuntu查询不到mysql状态 |
| ANSWER: 从1图和2图上来看,是没有安装mysql数据库, 所以根据以上图只能得出一个答案,那就是这台linux服务器上没有安装mysql数据库 如果你要启动第3图安装的mariadb数据库,应该是启动mariadb,而不是mysql |
| LINK:https://ask.csdn.net/questions/7614470?answer=53641934 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614454 |
| ANSWER_ID:53641930 |
| TITLE:SQL中关于创建外键的问题 |
| ANSWER: 这个报错是告诉你 cjdj这个表里面 ,没有kch这个字段 |
| LINK:https://ask.csdn.net/questions/7614454?answer=53641930 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614336 |
| ANSWER_ID:53641687 |
| TITLE:select查询语句的优化问题 |
| ANSWER: 有没有明确的报错信息? |
| LINK:https://ask.csdn.net/questions/7614336?answer=53641687 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614324 |
| ANSWER_ID:53641682 |
| TITLE:postgresql 使用table的默认前缀为public |
| ANSWER: 你对象创建在public下了,跨SCHEMA查询当然要加对应的SCHEMA名称,因为不同的SCHEMA下可以创建相同名称的对象 |
| LINK:https://ask.csdn.net/questions/7614324?answer=53641682 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614302 |
| ANSWER_ID:53641670 |
| TITLE:有如下两条MySQL连接查询语句,结果是一样的,敢问哪种用法效率更高! |
| ANSWER: 这几个表在不同数据量的情况下,效率会不一样,比较靠谱的方式还是看执行计划,当然实践出真知,不到生产上跑一跑,也无法100%确定数据库会不会自行对sql进行优化,优化方向是否符合自己的预期 |
| LINK:https://ask.csdn.net/questions/7614302?answer=53641670 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614277 |
| ANSWER_ID:53641656 |
| TITLE:将表A中数值的代码替换成表B中对应代码的汉字 |
| ANSWER: 表A是一个字符串? 由于题主要求使用sql,那么就得使用with as递归写法了 以下为实测截图
|
| LINK:https://ask.csdn.net/questions/7614277?answer=53641656 |

| SOURCE:CSDN_ASK |
| ASK_ID:7614215 |
| ANSWER_ID:53641623 |
| TITLE:dbeaver 21.3保持链接 |
| ANSWER: 几分钟不动 就会断开连接,这不是软件问题,是数据库策略或者网络策略的问题,请咨询数据库管理员或者网络管理员 |
| LINK:https://ask.csdn.net/questions/7614215?answer=53641623 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614095 |
| ANSWER_ID:53641618 |
| TITLE:没有SQL SERVER软件 可以帮打一下表格吗(参考图一) |
| ANSWER: 而且你这截图是认真的?让别人对着图片打码? |
| LINK:https://ask.csdn.net/questions/7614095?answer=53641618 |
| SOURCE:CSDN_ASK |
| ASK_ID:7614077 |
| ANSWER_ID:53641613 |
| TITLE:SQL数据库N对N的问题 |
| ANSWER: 这是个程序设计需求啊,要写多个函数或者过程,涉及到库存数量的占用和释放 |
| LINK:https://ask.csdn.net/questions/7614077?answer=53641613 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613863 |
| ANSWER_ID:53641591 |
| TITLE:开窗函数怎末分组?求解 |
| ANSWER: 开窗函数中的分组是在 patition by 这里定义的 |
| LINK:https://ask.csdn.net/questions/7613863?answer=53641591 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613797 |
| ANSWER_ID:53641585 |
| TITLE:使用scrapy框架爬取腾讯招聘网的数据 |
ANSWER:上面这句报错是提示你sql写错了,应该是 truncate table tencent |
| LINK:https://ask.csdn.net/questions/7613797?answer=53641585 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613045 |
| ANSWER_ID:53640849 |
| TITLE:powerBI列合并 |
| ANSWER: 添加自定义列或者条件列
|
| LINK:https://ask.csdn.net/questions/7613045?answer=53640849 |


| SOURCE:CSDN_ASK |
| ASK_ID:7613594 |
| ANSWER_ID:53640768 |
| TITLE:关于mysql,请问这个错误是为什么 |
| ANSWER: 楼上说得对,三个参数都要传,如果是out就更要传,必须声明个变量去接收它,要不然它没地方塞 |
| LINK:https://ask.csdn.net/questions/7613594?answer=53640768 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613483 |
| ANSWER_ID:53640710 |
| TITLE:plsql的job修改了interval不生效,next_date不变 |
| ANSWER: next_date在两种情况下会变化
|
| LINK:https://ask.csdn.net/questions/7613483?answer=53640710 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613088 |
| ANSWER_ID:53640704 |
| TITLE:mysql 问题处理,请教各位! |
| ANSWER: MySQL IFNULL 函数是MySQL控制流函数之一,它接受两个参数,如果不是 NULL ,则返回第一个参数。 否则, IFNULL 函数返回第二个参数。 两个参数可以是文字值或表达式。 |
| LINK:https://ask.csdn.net/questions/7613088?answer=53640704 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612737 |
| ANSWER_ID:53640688 |
| TITLE:MySQL8.0 删除表行数据出现错误,删除失败,这是为啥?? |
| ANSWER: 你没找到类似的问题,是因为,你这个不叫删除多行数据,而是叫删除多列
|
| LINK:https://ask.csdn.net/questions/7612737?answer=53640688 |

| SOURCE:CSDN_ASK |
| ASK_ID:7612692 |
| ANSWER_ID:53640673 |
| TITLE:#sql# 我想用date但它总是报错,只有用timestamp不会报错 |
| ANSWER: 是什么类型的数据库? |
| LINK:https://ask.csdn.net/questions/7612692?answer=53640673 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613423 |
| ANSWER_ID:53640652 |
| TITLE:为什么insert into插入数据之后结果显示不出来 |
| ANSWER: 你先把你执行插入后,下面输出的信息贴出来看看 |
| LINK:https://ask.csdn.net/questions/7613423?answer=53640652 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613417 |
| ANSWER_ID:53640647 |
| TITLE:SQL sever的累计和问题 |
| ANSWER: 今天刚好回答了一个类似的题,要求是5天一合计,你先看看,不懂再问 SQL server中一个月每五天统计一次这五天所有数据总和除以天数最后不足五天的为一组,有知道不用存储过程怎末写吗?-大数据-CSDN问答 CSDN问答为您找到SQL server中一个月每五天统计一次这五天所有数据总和除以天数最后不足五天的为一组,有知道不用存储过程怎末写吗?相关问题答案,如果想了解更多关于SQL server中一个月每五天统计一次这五天所有数据总和除以天数最后不足五天的为一组,有知道不用存储过程怎末写吗? sql、数据库 技术问题等相关问答,请访问CSDN问答。 https://ask.csdn.net/questions/7612646?spm=1005.2025.3001.5141 |
| LINK:https://ask.csdn.net/questions/7613417?answer=53640647 |
| SOURCE:CSDN_ASK |
| ASK_ID:7613354 |
| ANSWER_ID:53640572 |
| TITLE:怎么把数据纵向输出? |
| ANSWER: 这个要用unpivot
|
| LINK:https://ask.csdn.net/questions/7613354?answer=53640572 |

| SOURCE:CSDN_ASK |
| ASK_ID:7613105 |
| ANSWER_ID:53640567 |
| TITLE:mysql之select多条件两表联查,合并生成新的查询结果 |
| ANSWER: 这个两边数据都缺的情况,明显的要用 full join啊 题主更改数据库类型为sqlite,此数据库是不支持 full join 的,但可以通过左连接union右连接模拟 或者先构造一个全部区域、部门、性质的数据,以此数据为准去左连接这两个表 |
| LINK:https://ask.csdn.net/questions/7613105?answer=53640567 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612859 |
| ANSWER_ID:53640557 |
| TITLE:如何复制表中的某部分数据,并修改部分字段的内容 |
| ANSWER: 先按照你说的数据内容要求,把select查询语句写出来,确认是你要的数据内容后,在前面加上insert语句就行了 |
| LINK:https://ask.csdn.net/questions/7612859?answer=53640557 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612819 |
| ANSWER_ID:53640554 |
| TITLE:报表的sql怎么修改,在数据库可以运行,但在报表中无法运行 |
| ANSWER: 你把这个sql最后的分号去掉试一试 |
| LINK:https://ask.csdn.net/questions/7612819?answer=53640554 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612787 |
| ANSWER_ID:53640546 |
| TITLE:乾润报表sql语句报错,怎么搞?? |
| ANSWER: 贴下报错信息,可能不是sql错误,而是报表设置错误 |
| LINK:https://ask.csdn.net/questions/7612787?answer=53640546 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612980 |
| ANSWER_ID:53640319 |
| TITLE:Teradata SQL 转成hive 语句 下面这句话该怎么写 |
| ANSWER: 这段只是查询sql中的一个栏位,hive里支持case when 和cast,所以这段不用改
|
| LINK:https://ask.csdn.net/questions/7612980?answer=53640319 |

| SOURCE:CSDN_ASK |
| ASK_ID:7612153 |
| ANSWER_ID:53640061 |
| TITLE:传入主id集合,查询主id下关联的前几条数据,用MySQL怎么实现? |
| ANSWER: 用个开窗函数进行分组排序就好了 |
| LINK:https://ask.csdn.net/questions/7612153?answer=53640061 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612646 |
| ANSWER_ID:53639757 |
| TITLE:SQL server中一个月每五天统计一次这五天所有数据总和除以天数最后不足五天的为一组,有知道不用存储过程怎末写吗? |
| ANSWER: 用递归构造所有日期,用开窗函数取模分组 下面是实测截图
|
| LINK:https://ask.csdn.net/questions/7612646?answer=53639757 |

| SOURCE:CSDN_ASK |
| ASK_ID:7612645 |
| ANSWER_ID:53639648 |
| TITLE:oracle 执行SDE.st_distance出现ORA-28579: 在从外部过程代理程序回调时, 发生网络错误 |
| ANSWER: 这是一个ORACLE的BUG,需要升级数据库到11.2.0.2以上 Bug: Spatial Type for Oracle: st_intersects can fail with error ORA-028579 Technical Article Details : Bug: Spatial Type for Oracle: st_intersects can fail with error ORA-028579  https://support.esri.com/en/technical-article/000011218 |
| LINK:https://ask.csdn.net/questions/7612645?answer=53639648 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612525 |
| ANSWER_ID:53639484 |
| TITLE:在Mac上 装MySQL遇到这种情况怎么解决 |
| ANSWER: 这张图里没有问题啊,是不认识英语么? 启动mysql服务
初始化数据库
卸载
|
| LINK:https://ask.csdn.net/questions/7612525?answer=53639484 |



| SOURCE:CSDN_ASK |
| ASK_ID:7612338 |
| ANSWER_ID:53639470 |
| TITLE:mysql批量插入数据怎么生成uuid? |
| ANSWER: 先uuid查出来,然后再在外面套一层replace是可以的,见下图的测试
|
| LINK:https://ask.csdn.net/questions/7612338?answer=53639470 |

| SOURCE:CSDN_ASK |
| ASK_ID:7612410 |
| ANSWER_ID:53639454 |
| TITLE:Oracle远程连接出现01017 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7612410?answer=53639454 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612315 |
| ANSWER_ID:53639312 |
| TITLE:为什么使用DBeaver打开MySQL实体表数据库的时候报 -320086985 错误? |
| ANSWER: 看下是不是你连接信息填得有问题 在这个软件的github上,也有个中国用户报了can't open entity的错,但错误代码不一样,除此之外也没找到其他有人有报这个错的,而且此问题被标注为无法复现,因为他重启电脑后就好了,没准你也可以试试? Can't open entity 'xxx' Reason: -434054089 · Issue #13269 · dbeaver/dbeaver · GitHub System information: win10 DBeaver version = 21.1.3.202107181810 Database name and version:Any Driver name:Any ErrorLog: java.lang.NegativeArraySizeException: -434054089 at org.eclipse.swt.program.Program.getKeyValue(Program.java:164) at ...  https://github.com/dbeaver/dbeaver/issues/13269 |
| LINK:https://ask.csdn.net/questions/7612315?answer=53639312 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612153 |
| ANSWER_ID:53639303 |
| TITLE:传入主id集合,查询主id下关联的前几条数据,用MySQL怎么实现? |
| ANSWER: 同意楼上,建议先把当前表结构和你最终想要的数据格式样例发出来,可能没你想得那么复杂 |
| LINK:https://ask.csdn.net/questions/7612153?answer=53639303 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612132 |
| ANSWER_ID:53639302 |
| TITLE:真是奇了怪了,竟然搜不到关于tinyint字段修改问题的解决方案 |
| ANSWER: 不是你update这个字段的问题,而是"where order_no=?"没查出数据, |
| LINK:https://ask.csdn.net/questions/7612132?answer=53639302 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612125 |
| ANSWER_ID:53639294 |
| TITLE:mysql怎么用查出的字段作为筛选条件 |
| ANSWER: MySQL 带参数的存储过程(动态执行SQL语句) - 简书 MySQL5.0 以后,支持动态sql语句。当SQL语句中 字段名,表名,数据库名等 要作为变量时,必须要使用动态SQL。MySQL动态SQL语法如下: 1、 定义要执行的s... https://www.jianshu.com/p/d070abffa5fe |
| LINK:https://ask.csdn.net/questions/7612125?answer=53639294 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612231 |
| ANSWER_ID:53639288 |
| TITLE:sql语句提示不是单组分组函数 |
| ANSWER: 把你所有没做汇总的字段都group by 一下就行了 |
| LINK:https://ask.csdn.net/questions/7612231?answer=53639288 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612201 |
| ANSWER_ID:53639285 |
| TITLE:Python➕SQL server连接问题 |
| ANSWER: ODBC DRIVER 17 FOR SQL SERVER 下载页面 Download ODBC Driver for SQL Server - ODBC Driver for SQL Server | Microsoft Docs Download the Microsoft ODBC Driver for SQL Server to develop native-code applications that connect to SQL Server and Azure SQL Database. https://docs.microsoft.com/en-us/sql/connect/odbc/download-odbc-driver-for-sql-server?view=sql-server-ver15 |
| LINK:https://ask.csdn.net/questions/7612201?answer=53639285 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612194 |
| ANSWER_ID:53639284 |
| TITLE:web项目连接不上数据库 |
| ANSWER: java空指针了,请检查java代码 |
| LINK:https://ask.csdn.net/questions/7612194?answer=53639284 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612229 |
| ANSWER_ID:53639282 |
| TITLE:mysql配置错误,怎么回事 |
| ANSWER: 这个界面是MYSQL 的安装器,这个列表中显示的是你已经安装的组件。 |
| LINK:https://ask.csdn.net/questions/7612229?answer=53639282 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611990 |
| ANSWER_ID:53639181 |
| TITLE:Navicat Premium中如何设置bold属性? |
| ANSWER: 用可视化工具建表的话,就像上面那样操作, |
| LINK:https://ask.csdn.net/questions/7611990?answer=53639181 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612103 |
| ANSWER_ID:53639165 |
| TITLE:oracle数据库同样的查询语句有时候能查出数据,有时候查不出,需要重新连接。导致前端页面点查询也是这个情况。 |
| ANSWER: 这个问题有意思,
二、如果无论怎么检查的确是同一个数据库,检查2个sql的执行计划是否有区别,尝试在查不到的那个数据库上修改查询条件缩小范围,看是不是的确没有数据,因为可能存在执行计划跑错了导致数据查不到的情况, 三、最后一种可能性,就得看下数据库是不是有损坏了 |
| LINK:https://ask.csdn.net/questions/7612103?answer=53639165 |
| SOURCE:CSDN_ASK |
| ASK_ID:7612021 |
| ANSWER_ID:53639113 |
| TITLE:oracle数据集里某列存储了sql,如何通过select 直接查询数据集及数据集里sql执行后的值 |
| ANSWER: 首先,你得确定这个你处理出来的sql是只查询一个1行中的1列,即1个值。 接下来,你就可以用这个函数把你处理的这个sql字符串包起来,它就能在你查询的时候返回对应sql的结果了, |
| LINK:https://ask.csdn.net/questions/7612021?answer=53639113 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611968 |
| ANSWER_ID:53639086 |
| TITLE:Oracle,希望将两万张表里的100张不被新用户访问 |
| ANSWER: 授权SQL可以写个字符串拼接的sql得到,或者你也可以在EXCEL里用公式把授权命令拼出来。 因为你是新用户访问原用户里的部分表,不管是多还是少,只要需求是"部分",那么你必然不能做ALL的授权,而是必须要生成这19900个指定表的授权命令。 |
| LINK:https://ask.csdn.net/questions/7611968?answer=53639086 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611936 |
| ANSWER_ID:53638956 |
| TITLE:Java,SQL相关问题 |
| ANSWER: 引入对应数据库类型的jdbc驱动包 |
| LINK:https://ask.csdn.net/questions/7611936?answer=53638956 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611758 |
| ANSWER_ID:53638950 |
| TITLE:请问一下这一段SQL> Importing table ETL TERA.DW P00 PRODUCT@odsdb是干嘛的?直接执行会怎样? |
| ANSWER: 会报错,因为这不是sql命令,只是回显的日志 |
| LINK:https://ask.csdn.net/questions/7611758?answer=53638950 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611278 |
| ANSWER_ID:53638942 |
| TITLE:redhat8 安装oracle 11g 监听问题 求解答 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7611278?answer=53638942 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611287 |
| ANSWER_ID:53638941 |
| TITLE:redhat8 安装oracle 11g 监听问题 求解答 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7611287?answer=53638941 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611361 |
| ANSWER_ID:53638736 |
| TITLE:mysql基础#^_^# |
| ANSWER: 触发器是基于特定动作进行的一连串操作,你得先定义在什么情况下触发,比如更新、插入、删除某一张表,那么就要在这张表上建立触发器,在触发器里可以执行插入到日志表的sql。 如果是要监控所有表的修改,那就不应该用触发器了,应该开启数据库的审计功能,可以选择要对哪些行为进行审计 |
| LINK:https://ask.csdn.net/questions/7611361?answer=53638736 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611622 |
| ANSWER_ID:53638722 |
| TITLE:sql delete如何删除非int数据 |
| ANSWER: 如果这是个字符串拼接,那么你应该在这个变量的前后都加上单引号 上面这两行,第一行是不能执行的,第二行才能执行,你可以打印一下$sql看是个什么东东 |
| LINK:https://ask.csdn.net/questions/7611622?answer=53638722 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611595 |
| ANSWER_ID:53638714 |
| TITLE:用sql 查找出宿舍编号中倒数第二个数字为“0”的宿舍所在的园区名称。 |
| ANSWER: 字符串截取函数,第二个参数-2表示截取最后两位,然后只要识别它是0开头的2个字符就行了 |
| LINK:https://ask.csdn.net/questions/7611595?answer=53638714 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611570 |
| ANSWER_ID:53638695 |
| TITLE:连接SQL server 连接提示08001 |
| ANSWER: navicat默认没有安装sqlserver的驱动,你到navicat的安装目录里,找到"sqlncli_x64.msi"这个玩意,打开,安装,然后navicat就不会报这个ODBC的错了。 但是可能会报别的错,这个要看你sqlserver的版本了 navicat中自带的sqlserver驱动版本是10,无法连接新版的sqlserver,可以在以下页面中下载新版的驱动 Download Microsoft® SQL Server® 2012 SP4 Feature Pack from Official Microsoft Download Center https://www.microsoft.com/en-us/download/details.aspx?id=56041 进去此页面后,点击download,在弹出的框框中,选择sqlncli.msi(64位系统选大的,32位系统选小的),点击next,下载保存安装
然后在navicat里编辑连接,在高级里面选择11版本的驱动
|
| LINK:https://ask.csdn.net/questions/7611570?answer=53638695 |



| SOURCE:CSDN_ASK |
| ASK_ID:7611343 |
| ANSWER_ID:53638135 |
| TITLE:关于SQL语句的修改多行数据问题 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7611343?answer=53638135 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611312 |
| ANSWER_ID:53638133 |
| TITLE:创建视图的SQL语句太长,且用视图查看数据的查询速度太慢,想知道如何优化提高查询速度 |
| ANSWER: 把完整sql拿出来,还有各个表的数据量、索引、分区,再看下执行计划。光看你这个伪代码没有意义 |
| LINK:https://ask.csdn.net/questions/7611312?answer=53638133 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611219 |
| ANSWER_ID:53637993 |
| TITLE:vs2010和mysql数据库问题 |
| ANSWER: 把报错内容贴出来看看 这是个很经典的报错了,mysql 5.7和8.0的默认认证方式不一样,你用老的mysql客户端去连8.0版本的mysql就会这样。解决方式是修改对应登录账户的认证方式并刷新权限,或者修改数据库的启动配置文件中的认证方式。 |
| LINK:https://ask.csdn.net/questions/7611219?answer=53637993 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611208 |
| ANSWER_ID:53637991 |
| TITLE:可以ping通不能访问mysql |
| ANSWER: 你数据库那一栏填错了,不应该填ip,应该填数据库名称 |
| LINK:https://ask.csdn.net/questions/7611208?answer=53637991 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611124 |
| ANSWER_ID:53637898 |
| TITLE:调用sqlalchemy查询时出错 |
| ANSWER: 因为你打印的是对象,而不是对象的值, |
| LINK:https://ask.csdn.net/questions/7611124?answer=53637898 |
| SOURCE:CSDN_ASK |
| ASK_ID:7611021 |
| ANSWER_ID:53637889 |
| TITLE:关于sqlserver 的问题:为什么这段子查询SQL 只能查到最先插入到子表hgt里面的记录 |
| ANSWER: 你的主表和子表是用 hf.TruckID=ht.ID 这个条件进行join的,所以你不光要看子表的id是否存在,最主要的是看主表的TruckID是否存在,因为你这是个left join,是以左边为准去匹配右边的 |
| LINK:https://ask.csdn.net/questions/7611021?answer=53637889 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610902 |
| ANSWER_ID:53637827 |
| TITLE:虚拟机jps查看Java版本错误 |
| ANSWER: 库文件没加载,你看下profile里面是不是没正确配置库文件的路径 |
| LINK:https://ask.csdn.net/questions/7610902?answer=53637827 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610968 |
| ANSWER_ID:53637815 |
| TITLE:求一个简单的SQL语句 |
| ANSWER: 用开窗函数,按日期分组,取最小的开始时间和最大的结束时间 ORACLE数据库中的实测截图如下,其他常用主流数据库基本也是支持的
|
| LINK:https://ask.csdn.net/questions/7610968?answer=53637815 |

| SOURCE:CSDN_ASK |
| ASK_ID:7610880 |
| ANSWER_ID:53637804 |
| TITLE:mysql导入csv文件时如何忽略文本中的逗号 |
| ANSWER: 由于csv本来就是用逗号分隔的列,如果你文本内容中本身就有逗号,那么生成CSV的时候应该把对应的列值用双引号引起来,否则程序是无法识别对应的逗号是分隔符还是数据本身的。 |
| LINK:https://ask.csdn.net/questions/7610880?answer=53637804 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610905 |
| ANSWER_ID:53637789 |
| TITLE:springboot项目打包后没有手动导入的包 |
| ANSWER: 这个报错的确就是没找到oracle的jdbc驱动, |
| LINK:https://ask.csdn.net/questions/7610905?answer=53637789 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610799 |
| ANSWER_ID:53637653 |
| TITLE:oracle dblink链接用户去查询另一个用户的表 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7610799?answer=53637653 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610075 |
| ANSWER_ID:53637648 |
| TITLE:mysql 连不上is not allowed to connect to this mysql server |
| ANSWER: 应该是权限被修改了,只允许哪些ip连接数据库,如果有其他人共用就去找其他人,如果只有你自己用,就去检查下你执行了一些什么命令 |
| LINK:https://ask.csdn.net/questions/7610075?answer=53637648 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610791 |
| ANSWER_ID:53637618 |
| TITLE:【每日SQL打卡】DAY 25丨不同性别每日分数总计【难度中等】 |
| ANSWER: 没有进行提问,这是让我猜么? |
| LINK:https://ask.csdn.net/questions/7610791?answer=53637618 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610751 |
| ANSWER_ID:53637611 |
| TITLE:关于#sql#的问题:EndTlme要小于BeqinTime,两个时间比较 |
ANSWER:你是这个意思? |
| LINK:https://ask.csdn.net/questions/7610751?answer=53637611 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610689 |
| ANSWER_ID:53637604 |
| TITLE:SQL pg_是什么意思? |
| ANSWER: pg是postgresql数据库的简写, |
| LINK:https://ask.csdn.net/questions/7610689?answer=53637604 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610581 |
| ANSWER_ID:53637569 |
| TITLE:如何在Navicat下建立job或者定时函数 |
| ANSWER: plsql developer 直接查看job对象是长这个样子 需要稍微修改一下,声明个参数,用来接收job号就好了 注意参数前的冒号要去掉 |
| LINK:https://ask.csdn.net/questions/7610581?answer=53637569 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610767 |
| ANSWER_ID:53637558 |
| TITLE:sql 最后加了 .If Errorcode <> 0 Then Quit 12; 是什么意思 |
| ANSWER: 如果 错误代码 不等于 0 则 退出 |
| LINK:https://ask.csdn.net/questions/7610767?answer=53637558 |
| SOURCE:CSDN_ASK |
| ASK_ID:7610292 |
| ANSWER_ID:53637514 |
| TITLE:SQL Server 日期范围按每月一行拆分 |
| ANSWER: 这里要用到递归写法,刚好之前有写过oracle的这个需求
在sqlserver 中也可以使用with进行递归,语法基本和oracle一致,但是日期计算函数和oracle中不一样,需要你自行替换成sqlserver中的函数,比如取月第一天、月最后一天、两个日期间间隔的月份数、指定日期加一月等 |
| LINK:https://ask.csdn.net/questions/7610292?answer=53637514 |

| SOURCE:CSDN_ASK |
| ASK_ID:7610576 |
| ANSWER_ID:53637404 |
| TITLE:sql查询问题对于某一字段连续且重复,只取一 |
| ANSWER: 这里要使用开窗函数进行分组排序 里面的 order by c_time,加ASC或者DESC可以决定是取第一条还是最后一条 根据题主补充描述,应该使用以下sql 实测和题主要求一致
以上是在oracle数据库中进行的测试,如果是在其他数据库,nvl空值处理的函数可能要换成对应数据库中的函数 |
| LINK:https://ask.csdn.net/questions/7610576?answer=53637404 |

| SOURCE:CSDN_ASK |
| ASK_ID:7610294 |
| ANSWER_ID:53637385 |
| TITLE:SQL server中一个月每五天统计一次这五天所有数据总和除以天数最后不足五天的为一组,有知道不用存储过程怎末写吗? |
| ANSWER: 获取行号,除以5,取商的整数,得分组号,再按分组号group by 以下是实测截图
如果日期存在重复,你可以先按日期做一次汇总作为子查询,然后外面再套这个开窗函数就行了,如下 |
| LINK:https://ask.csdn.net/questions/7610294?answer=53637385 |

| SOURCE:CSDN_ASK |
| ASK_ID:7610349 |
| ANSWER_ID:53637319 |
| TITLE:使用left ioin on ,sql报错:an on clause has an invalid table reference |
ANSWER:由于你left join 前后是C表和D表,所以on的字段只能在C和D里面选,你要么改成on c.id = d.id ,要么把表的排列顺序换下,把a表放到left join前面去 |
| LINK:https://ask.csdn.net/questions/7610349?answer=53637319 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609490 |
| ANSWER_ID:53636638 |
| TITLE:postgresql拼接传参,以及where后对传参的判断 |
| ANSWER: |
| LINK:https://ask.csdn.net/questions/7609490?answer=53636638 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609963 |
| ANSWER_ID:53636635 |
| TITLE:刚学数据库,这怎么改啊? |
| ANSWER:
你仔细看看上下两个字段有什么区别?是不是多了个空格? |
| LINK:https://ask.csdn.net/questions/7609963?answer=53636635 |

| SOURCE:CSDN_ASK |
| ASK_ID:7609876 |
| ANSWER_ID:53636633 |
| TITLE:以root用户登录Linux系统后,当前工作目录为/root。请按以下要求写出相应操作的命令语句。 |
| ANSWER: 为什么标签写个"sql"? |
| LINK:https://ask.csdn.net/questions/7609876?answer=53636633 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609860 |
| ANSWER_ID:53636631 |
| TITLE:sql Server 怎么用 |
| ANSWER: 你怎么改数据库里面的东西都不会对你电脑有影响,最多就是数据库挂了、数据库启不动了 |
| LINK:https://ask.csdn.net/questions/7609860?answer=53636631 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609847 |
| ANSWER_ID:53636629 |
| TITLE:SQL Service视图 |
| ANSWER: 你都可以查出数据来了,当然可以导出来啊,你又不是去改里面的数据。 |
| LINK:https://ask.csdn.net/questions/7609847?answer=53636629 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609799 |
| ANSWER_ID:53636627 |
| TITLE:sql怎么判断是否同一月,同一天 |
| ANSWER: 截取出月份和日期,再进行比较。 |
| LINK:https://ask.csdn.net/questions/7609799?answer=53636627 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609944 |
| ANSWER_ID:53636623 |
| TITLE:关于#oracle#的问题:培训了几个月 学习能力也是前几名 最近找了几天工作,还是直接坦诚相待拿低薪 |
| ANSWER: 你如果对自己的能力没自信的话,建议先攒经验,只要你能做出足够的成绩,就有底气要求涨薪,不涨就跳,这个时候也已经有工作经验了。 |
| LINK:https://ask.csdn.net/questions/7609944?answer=53636623 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609943 |
| ANSWER_ID:53636613 |
| TITLE:Oracle数据库中dmp的文件怎么执行 |
| ANSWER: dmp是oracle数据库工具exp或expdp导出的数据库文件,需要使用imp或impdp工具执行导入。 |
| LINK:https://ask.csdn.net/questions/7609943?answer=53636613 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609208 |
| ANSWER_ID:53636610 |
| TITLE:Symmetric hash join |
| ANSWER:
上面这张图用最直白的方式描述了 simply hash join 和symmetric hash join的区别 |
| LINK:https://ask.csdn.net/questions/7609208?answer=53636610 |

| SOURCE:CSDN_ASK |
| ASK_ID:7609638 |
| ANSWER_ID:53636403 |
| TITLE:安装MySQL的时候到这一步出现问题了,不知道怎么搞 |
| ANSWER: 点这个界面右边的 "log",根据提示信息排查问题
|
| LINK:https://ask.csdn.net/questions/7609638?answer=53636403 |

| SOURCE:CSDN_ASK |
| ASK_ID:7609512 |
| ANSWER_ID:53636399 |
| TITLE:这四个选项那个不能进行模糊查询 |
| ANSWER: 这是啥题啊,模糊查询就是like加通配符(%_)来查询,不用like就不叫模糊查询。 麻烦给个题目出处 |
| LINK:https://ask.csdn.net/questions/7609512?answer=53636399 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609435 |
| ANSWER_ID:53636188 |
| TITLE:有人会存储过程还有触发器吗?求 |
| ANSWER: 麻烦明确问题需求是什么。 |
| LINK:https://ask.csdn.net/questions/7609435?answer=53636188 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609278 |
| ANSWER_ID:53636175 |
| TITLE:请教,这个sql语句的count取值为什么是小于2,而不是小于4? |
| ANSWER: 楼上说得对,这个count你不要理解成主查询的行数,而是应该理解为一个类似exists子查询的条件 |
| LINK:https://ask.csdn.net/questions/7609278?answer=53636175 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609277 |
| ANSWER_ID:53636151 |
| TITLE:SQL语句修改与查询如何联合 |
| ANSWER: 你第一条sql里,子查询应该把这张表再放进去,而不是使用别名,from后面是不能直接接别名的 |
| LINK:https://ask.csdn.net/questions/7609277?answer=53636151 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609262 |
| ANSWER_ID:53636133 |
| TITLE:PHPstudy 中无法启动MySQL |
| ANSWER:
这个目录不存在 "D:\PHP\编辑器与集成环境\php\study\服务器\phpstudy_pro\Extensions\MySQL5.7.26\data" 请检查数据库配置 |
| LINK:https://ask.csdn.net/questions/7609262?answer=53636133 |

| SOURCE:CSDN_ASK |
| ASK_ID:7609232 |
| ANSWER_ID:53636124 |
| TITLE:关于#sql#的问题,如何解决? |
| ANSWER: 报错已经提示你了,有些参数的类型不能转换成string
|
| LINK:https://ask.csdn.net/questions/7609232?answer=53636124 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609215 |
| ANSWER_ID:53636117 |
| TITLE:oracle中sql查询超时问题 |
| ANSWER: 如果你的coupon_no有索引,那么的确有可能会不加日期条件更快,因为你最终的目的是统计coupon_no的去重个数,而索引是可以快速计算出这个值的;而当你用了时间条件后,执行计划可能就不走coupon_no的索引了,速度反而会慢,你可以看下加时间条件和不加时间条件的执行计划的区别,在plsql中看执行计划的快捷方式是,选中sql,按F5 |
| LINK:https://ask.csdn.net/questions/7609215?answer=53636117 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609310 |
| ANSWER_ID:53636048 |
| TITLE:Windows使用Oracle 19c的Logminer在确认参数是否设定时发现缺少utl_file_dir |
| ANSWER: Using LogMiner to Analyze Redo Log Files https://docs.oracle.com/cd/E11882_01/server.112/e22490/logminer.htm#SUTIL1563
意思其实就是 "utl_file_dir" 这个东西是要你手动指定的。 Oracle日志挖掘之LogMiner(前部分原理解释,后部分实操!)_yes_is_ok的博客-CSDN博客_logminer Oracle日志挖掘之LogMiner官方文档地址:http://docs.oracle.com/cd/E11882_01/server.112/e22490/logminer.htm#SUTIL019本文转自:http://blog.itpub.net/26736162/viewspace-2141148/众所周知,所有对用户数据和数据字典的改变都记录在Oracle的Redo Log中,因此... https://blog.csdn.net/yes_is_ok/article/details/79296614 |
| LINK:https://ask.csdn.net/questions/7609310?answer=53636048 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609330 |
| ANSWER_ID:53636030 |
| TITLE:oracle数据库去重查询后怎么消除null值 |
| ANSWER: 举几个你数据的例子看看? 另外,你说加" where条件org is not null 不好用"是个什么意思?是用了报错还是条件没生效? |
| LINK:https://ask.csdn.net/questions/7609330?answer=53636030 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609320 |
| ANSWER_ID:53636009 |
| TITLE:图一该怎么修改才能做出图二的婚否复选框 |
| ANSWER: 先说下你第二张图用的是什么工具? 数据库的表和数据本身不会带什么复选框的,只有某些工具在显示的时候才会进行转换,需要看看你用的是什么工具展示数据,再看如何配置工具以转换成复选框进行显示 |
| LINK:https://ask.csdn.net/questions/7609320?answer=53636009 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609154 |
| ANSWER_ID:53635905 |
| TITLE:关于sql 处理字段中字符串的问题 |
| ANSWER: 简单来说,就是取":"到";"之间的字符串(初始字符串需要在最后拼一个";"),取这个可以用正则表达式,也可以用存储过程循环来处理。
如果是其他数据库,请说明数据库类型 |
| LINK:https://ask.csdn.net/questions/7609154?answer=53635905 |

| SOURCE:CSDN_ASK |
| ASK_ID:7608688 |
| ANSWER_ID:53635898 |
| TITLE:关于银行类#SQL#的问题,如何解决? |
| ANSWER: 话说这面试题做对是不是就可以进银行了? 如果需要翻译产品名称,再把第二个表关联进去两次来进行翻译就好了。 |
| LINK:https://ask.csdn.net/questions/7608688?answer=53635898 |
| SOURCE:CSDN_ASK |
| ASK_ID:7609149 |
| ANSWER_ID:53635850 |
| TITLE:SQL的文件怎么能使啊 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7609149?answer=53635850 |
| SOURCE:CSDN_ASK |
| ASK_ID:7608889 |
| ANSWER_ID:53635834 |
| TITLE:oracle是否有一种可以在存储过程中使用的内存表,可以用来保存查询结果并多次使用,做join查询merge更新用 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7608889?answer=53635834 |
| SOURCE:CSDN_ASK |
| ASK_ID:7608872 |
| ANSWER_ID:53635828 |
| TITLE:Oracle数据库中怎么提取指定时间? |
| ANSWER: 方案一,查看你这个函数的代码,参考着修改,建一个新的函数 ORACLE里要取各种日期其实很容易的,封装普通的自定义函数看上去是让代码整洁了,但是执行效率会变低,除非使用函数缓存或者sql宏 |
| LINK:https://ask.csdn.net/questions/7608872?answer=53635828 |
| SOURCE:CSDN_ASK |
| ASK_ID:7583390 |
| ANSWER_ID:53635183 |
| TITLE:遇到了一个看不太明白的脚本,可以解释一下吗 |
| ANSWER: 关闭回显 |
| LINK:https://ask.csdn.net/questions/7583390?answer=53635183 |
| SOURCE:CSDN_ASK |
| ASK_ID:7607918 |
| ANSWER_ID:53635178 |
| TITLE:使用datax同步oracle到hive的数据错乱问题 |
| ANSWER: 查了一些资料,Datax源码的确有点问题,需要修改Datax的源码。 datax mysql null不能转为Long 等一些列无法强转问题_大壮的博客-CSDN博客_datax null 首先来说一下前置,hive的hdfs文件,增量同步至mysql中。1.解决datax抽hdfs数据到mysql之null值变成 \N 或者 转换错误 的问题修改datax源码plugin-unstructured-storage-util下的UnstructuredStorageReaderUtil.class加上一个判断,因为在hdfs中,null值存储的是 \N ,... https://blog.csdn.net/qq_33792843/article/details/91987903 Datax的一次填坑经历 - 知乎 使用Datax进行两个集群间的数据同步,在读取HDFS数据时,会出现数据丢失问题,本文针对数据丢失问题做出了分析以及对应解决方案,希望帮助大家在使用Datax过程中避免该问题的出现!问题描述最近在使用Datax进行两… https://zhuanlan.zhihu.com/p/64852047 |
| LINK:https://ask.csdn.net/questions/7607918?answer=53635178 |
| SOURCE:CSDN_ASK |
| ASK_ID:7608620 |
| ANSWER_ID:53635161 |
| TITLE:我数据库的系统分离了,为什么在电脑里找不到相应的mdf,ldf文件? |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7608620?answer=53635161 |
| SOURCE:CSDN_ASK |
| ASK_ID:7608383 |
| ANSWER_ID:53634994 |
| TITLE:mysql更改root密码语法错误 |
| ANSWER: 用错符号了,应该是单引号',而不是` |
| LINK:https://ask.csdn.net/questions/7608383?answer=53634994 |
| SOURCE:CSDN_ASK |
| ASK_ID:7608371 |
| ANSWER_ID:53634985 |
| TITLE:为什么Oracle账户无法删除和更改密码 |
| ANSWER: 操作系统的账户重命名不是在这个界面么?
|
| LINK:https://ask.csdn.net/questions/7608371?answer=53634985 |

| SOURCE:CSDN_ASK |
| ASK_ID:7608335 |
| ANSWER_ID:53634982 |
| TITLE:管理员模式无法登录MySQL |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7608335?answer=53634982 |
| SOURCE:CSDN_ASK |
| ASK_ID:7608310 |
| ANSWER_ID:53634978 |
| TITLE:MYSQL多条件查询 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7608310?answer=53634978 |
| SOURCE:CSDN_ASK |
| ASK_ID:7608060 |
| ANSWER_ID:53634681 |
| TITLE:Mysql环境下select两表联合多条件查询语句怎么写? |
| ANSWER: mysql没有full join,可以使用以下方式 注意中间的union,达到去重的效果 |
| LINK:https://ask.csdn.net/questions/7608060?answer=53634681 |
| SOURCE:CSDN_ASK |
| ASK_ID:7607641 |
| ANSWER_ID:53634307 |
| TITLE:请问sql for json path如何控制查询结果输出为单个列名形式 |
ANSWER:实测截图,和你要的结果一模一样
list其实是无序的,你分开两个数组,很有可能会导致数据无法对应。json和xml一样,一直是有大量冗余的字符,但这就是保证兼容性的标准。自己定解析规则也不是不行,但这样就无法兼容其他外部接口了,只能你自己内部使用 |
| LINK:https://ask.csdn.net/questions/7607641?answer=53634307 |

| SOURCE:CSDN_ASK |
| ASK_ID:7607548 |
| ANSWER_ID:53634243 |
| TITLE:如何解决Crystal Reports 2008的ORA-28040报错 |
| ANSWER: 有两个方案
|
| LINK:https://ask.csdn.net/questions/7607548?answer=53634243 |
| SOURCE:CSDN_ASK |
| ASK_ID:7607564 |
| ANSWER_ID:53634214 |
| TITLE:hive查询,使用where子查询没有返回结果 |
| ANSWER: where中又使用了一次emloyees表,和上面的emloyees表没有任何关联关系,你要根据80000.0来定位数据的话,应该是像下面这样写 当然我不确定你这个显示是否有小数位四舍五入,或许要改成 |
| LINK:https://ask.csdn.net/questions/7607564?answer=53634214 |
| SOURCE:CSDN_ASK |
| ASK_ID:7607536 |
| ANSWER_ID:53634195 |
| TITLE:sql三表关联后去重 |
| ANSWER: 把表结构和你最后想要的格式发出来,并说明对应关系 根据题主补充描述,可使用开窗函数结合nullif函数使上下相邻两个格子中重复数据只保留一个,其他变为空值,如下 下面是sqlserver实测截图
此方法在oracle数据库中也可以使用,参考 【ORACLE】收集一些较为少见但很有用的SQL函数及写法.part5 - DarkAthena's World-ORACLE,RETAIL and IT 接上篇【ORACLE】收集一些较为少见但很有用的SQL函数及写法.part429.ANY_VALUE作用:作为聚合函数,返回任意一个值(19c版本才添加的)。比如常见的一个查询,关联商品基础信息表和销售明细表,对销售明细进行汇总,然后同时又要显示商品编码和商品名称,大多数情况下都是这么写的selec https://www.darkathena.top/archives/oracle-sql-part5 |
| LINK:https://ask.csdn.net/questions/7607536?answer=53634195 |

| SOURCE:CSDN_ASK |
| ASK_ID:7607475 |
| ANSWER_ID:53634193 |
| TITLE:如何根据一个字段控制另一个字段保留相应的小数位 |
| ANSWER: 对应的参数位置直接使用那个字段就好了,比如
以上测试来自于oracle数据库,sqlserver中的round函数应该是一样的效果,都符合ANSI-SQL标准 |
| LINK:https://ask.csdn.net/questions/7607475?answer=53634193 |

| SOURCE:CSDN_ASK |
| ASK_ID:7607461 |
| ANSWER_ID:53634182 |
| TITLE:为什么查询过程出现了指定了非布尔型表达式啊 |
| ANSWER:
这句语法不对,报错提示不是布尔表达式 ,是指的 where 后面,你只接了一个material_no ,很明显这个值不是true或false。 但这一行的错误还不仅仅只有这一个,看不懂你这句想要干什么 |
| LINK:https://ask.csdn.net/questions/7607461?answer=53634182 |

| SOURCE:CSDN_ASK |
| ASK_ID:7607424 |
| ANSWER_ID:53634176 |
| TITLE:navicat怎么设置对性别的约束 |
| ANSWER: 不同的数据库有点区别,如果是mysql的话 |
| LINK:https://ask.csdn.net/questions/7607424?answer=53634176 |
| SOURCE:CSDN_ASK |
| ASK_ID:7607491 |
| ANSWER_ID:53634149 |
| TITLE:select跨表查询之分表汇总后联合显示数据如何处理? |
| ANSWER: 在两张表中都有可能关联数据缺失的情况下,如果要让数据不会由于关联而遗漏,需要使用full join,并且对select的字段做判断为空的处理,另外就是对除数为0的处理。 我手上目前没有sqlite,关于full join 的替代方式可以在网上搜一下,当然针对你这个问题有另外一种方式,无需join 搜了下,sqlite好像不支持decode,所以改成case when了 |
| LINK:https://ask.csdn.net/questions/7607491?answer=53634149 |
| SOURCE:CSDN_ASK |
| ASK_ID:7607120 |
| ANSWER_ID:53633992 |
| TITLE:Mysql连接mycat报错是什么原因呢? |
| ANSWER: 到这里下载对应操作系统版本的jdbc库放进去 |
| LINK:https://ask.csdn.net/questions/7607120?answer=53633992 |
| SOURCE:CSDN_ASK |
| ASK_ID:7607216 |
| ANSWER_ID:53633981 |
| TITLE:列转行需要用sql处理处理拆分拼接字段 |
| ANSWER: 问题不够明确,建议拿数据举例,转换前是什么样子,转换后是什么样子,至少要有两条数据的例子 |
| LINK:https://ask.csdn.net/questions/7607216?answer=53633981 |
| SOURCE:CSDN_ASK |
| ASK_ID:7607189 |
| ANSWER_ID:53633975 |
| TITLE:根据前端过来不同日期 统计日期每小时的访问量 写动态sql 统计24小时内每小时的数据 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7607189?answer=53633975 |
| SOURCE:CSDN_ASK |
| ASK_ID:7606642 |
| ANSWER_ID:53633444 |
| TITLE:java mysql单表千万级数据求和 |
| ANSWER: 一般情况下,当然是在sql里快。 |
| LINK:https://ask.csdn.net/questions/7606642?answer=53633444 |
| SOURCE:CSDN_ASK |
| ASK_ID:7606574 |
| ANSWER_ID:53633438 |
| TITLE:Mysql创建数据库报错 |
| ANSWER: 这是sql server创建数据库的指令,在mysql里当然不行了啊 |
| LINK:https://ask.csdn.net/questions/7606574?answer=53633438 |
| SOURCE:CSDN_ASK |
| ASK_ID:7606488 |
| ANSWER_ID:53633425 |
| TITLE:oracle自定义了个日期函数,这种写法有什么错误? |
ANSWER:上面这一行改成下面这样 还有,你最后的 "return (datatime);",可以不要括号 |
| LINK:https://ask.csdn.net/questions/7606488?answer=53633425 |
| SOURCE:CSDN_ASK |
| ASK_ID:7606032 |
| ANSWER_ID:53632820 |
| TITLE:excel用&合并单元格内容后为什么整数1000变成了1, |
| ANSWER:
excel里应该没有这个列 |
| LINK:https://ask.csdn.net/questions/7606032?answer=53632820 |

| SOURCE:CSDN_ASK |
| ASK_ID:7606335 |
| ANSWER_ID:53632808 |
| TITLE:如何将以下数据按影视、教育、音乐、电竞等板块分组 |
| ANSWER: 转换后的第一列,是否为责任方这个字段的最后两个汉字? |
| LINK:https://ask.csdn.net/questions/7606335?answer=53632808 |
| SOURCE:CSDN_ASK |
| ASK_ID:7605876 |
| ANSWER_ID:53632793 |
| TITLE:oracle一列多值的更新问题。 |
| ANSWER: 问题有点歧义,"多值含有3,要把3删掉"这种情况,如果是'1,2,3'也是要把3删掉么?那么这不就是所有的3都被删掉了?我先假设你'1,2,3'是想转换成'a,b,c',那么可以用translate函数来进行转换,其他的特殊处理用case when来判断,比如
以上sql为方便理解,拆解了步骤,其实可以合并成只用一个select的 |
| LINK:https://ask.csdn.net/questions/7605876?answer=53632793 |

| SOURCE:CSDN_ASK |
| ASK_ID:7606285 |
| ANSWER_ID:53632755 |
| TITLE:SQLyog导入数据库失败,不知道怎么搞 |
| ANSWER: 第一个报错,No database selected 是你没有选择数据库, |
| LINK:https://ask.csdn.net/questions/7606285?answer=53632755 |
| SOURCE:CSDN_ASK |
| ASK_ID:7606167 |
| ANSWER_ID:53632672 |
| TITLE:未能加载文件或程序集 |
| ANSWER: 删除以下注册表 |
| LINK:https://ask.csdn.net/questions/7606167?answer=53632672 |
| SOURCE:CSDN_ASK |
| ASK_ID:7605662 |
| ANSWER_ID:53631992 |
| TITLE:mysql如何查询多个值 |
| ANSWER: 如果是MYSQL8.0版本,可以用with递归 |
| LINK:https://ask.csdn.net/questions/7605662?answer=53631992 |
| SOURCE:CSDN_ASK |
| ASK_ID:7605247 |
| ANSWER_ID:53631987 |
| TITLE:MYSQL触发器怎么写? |
| ANSWER: 很好奇你书里的例子,能不能拍个照看看,顺便拍一下书名? 然后我怀疑是我孤陋寡闻,在网上搜到了这篇,和你这个sql一模一样 但是,这是sql server啊,不是mysql,mysql是不支持这种语法的,不同数据库的语法是不一样的 |
| LINK:https://ask.csdn.net/questions/7605247?answer=53631987 |
| SOURCE:CSDN_ASK |
| ASK_ID:7605250 |
| ANSWER_ID:53631936 |
| TITLE:同一条sql,sqlplus,plsql中执行没有问题,后台报异常ORA-01855: AM/A.M. or PM/P.M. required |
| ANSWER: 这个玩意是基于oracle客户端产生的会话的,你java应用访问产生的会话,那么就要把java应用端的环境变量改了 可以创建登录触发器来修改,比如 |
| LINK:https://ask.csdn.net/questions/7605250?answer=53631936 |
| SOURCE:CSDN_ASK |
| ASK_ID:7604845 |
| ANSWER_ID:53631778 |
| TITLE:类似qq那种,好友不同的分类 |
| ANSWER: 你这个问题就是设计两张表,1张人员明细表,1张好友类型表,两张表通过好友类型代码建立关系 加人就在人员明细表里插数据,好友类型只能从好友类型表里选; 去了解下什么叫做关系型数据库吧 |
| LINK:https://ask.csdn.net/questions/7604845?answer=53631778 |
| SOURCE:CSDN_ASK |
| ASK_ID:7605379 |
| ANSWER_ID:53631769 |
| TITLE:update和count一样用,统计函数怎么写 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7605379?answer=53631769 |
| SOURCE:CSDN_ASK |
| ASK_ID:7605215 |
| ANSWER_ID:53631763 |
| TITLE:oracle rac集群为什么需要部署在物理服务器上? |
| ANSWER: 本地虚拟机都能装rac,谁说的不能部署在云服务器上? |
| LINK:https://ask.csdn.net/questions/7605215?answer=53631763 |
| SOURCE:CSDN_ASK |
| ASK_ID:7604342 |
| ANSWER_ID:53631582 |
| TITLE:mysql插入数据时做判断 |
| ANSWER: 同意楼上王胖胖, |
| LINK:https://ask.csdn.net/questions/7604342?answer=53631582 |
| SOURCE:CSDN_ASK |
| ASK_ID:7604739 |
| ANSWER_ID:53631556 |
| TITLE:SqlCommand运行一个正确的sql语句,查询结果与数据库中的查询结果不一致? |
| ANSWER: 断点调试或者打印下日志,看 rdr["contact"].ToString() 这个玩意在程序运行中到底是个啥值,如果对了就跟踪Contact值的变化;如果不对就往前找 |
| LINK:https://ask.csdn.net/questions/7604739?answer=53631556 |
| SOURCE:CSDN_ASK |
| ASK_ID:7604588 |
| ANSWER_ID:53631527 |
| TITLE:请教DB2中分组统计中,如何显示COUNT结果为0的行? |
| ANSWER: 这个题有问题,如果带where条件能查到1100,比如下面这个sql 那么查询同一个表,不带条件,理论上查出来的数据只会多不会少,可是题主却说1100不见了? 建议题主把真实的sql发一下 |
| LINK:https://ask.csdn.net/questions/7604588?answer=53631527 |
| SOURCE:CSDN_ASK |
| ASK_ID:7605135 |
| ANSWER_ID:53631504 |
| TITLE:SQL server导出一段包含换行符的数据 直接查询导出数据不会换行 |
| ANSWER: EXCEL中要显示换行,需保证字符串中有回车符和换行符两个,你原始数据可能只有一个换行或者只有一个回车,因此导致在不同程序中看到的情况不一样。 |
| LINK:https://ask.csdn.net/questions/7605135?answer=53631504 |
| SOURCE:CSDN_ASK |
| ASK_ID:7604039 |
| ANSWER_ID:53630405 |
| TITLE:寻找解决方法——mysql创建储存函数 |
| ANSWER: 一般来说,常规写法是,这个过程里要声明两个变量,一个平均分,一个返回值, 另一个做法就是,先写个查询sql,计算平均值,并直接用case when 判断,直接得出最终输出的结果,然后把这个sql改成 into 到一个变量,最后return它就好了 |
| LINK:https://ask.csdn.net/questions/7604039?answer=53630405 |
| SOURCE:CSDN_ASK |
| ASK_ID:7604240 |
| ANSWER_ID:53630396 |
| TITLE:运行sql文件成功;转储sql文件运行成功,但刷新都没有表 |
| ANSWER: 确认下sql文件里面有没有建表语句,建表语句有没有指定其他schema |
| LINK:https://ask.csdn.net/questions/7604240?answer=53630396 |
| SOURCE:CSDN_ASK |
| ASK_ID:7604273 |
| ANSWER_ID:53630393 |
| TITLE:dbeaver本地oracle数据库 |
| ANSWER: 监听没启动 |
| LINK:https://ask.csdn.net/questions/7604273?answer=53630393 |
| SOURCE:CSDN_ASK |
| ASK_ID:7604067 |
| ANSWER_ID:53630239 |
| TITLE:sql怎么求出每个时间段在线的人数。 |
| ANSWER: 这个呀,直观上来看,是如何让一行记录变多行的问题, |
| LINK:https://ask.csdn.net/questions/7604067?answer=53630239 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603946 |
| ANSWER_ID:53630217 |
| TITLE:mysql通过insert into select插入数据过程中使用cast(expr as json)将varcahr(255)类型转成json类型 |
| ANSWER: 拼字符串就是了 |
| LINK:https://ask.csdn.net/questions/7603946?answer=53630217 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603794 |
| ANSWER_ID:53630080 |
| TITLE:MYSQL的unix_timestamp问题 |
| ANSWER: 你cut_time这个字段里面,并不是所有数据都满足这个日期格式, 看看这个转换错误的cut_time这一行到底长啥样 |
| LINK:https://ask.csdn.net/questions/7603794?answer=53630080 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603904 |
| ANSWER_ID:53630072 |
| TITLE:请求同一个名称下的多列数据怎么合并到同一行? |
| ANSWER: a.id = b.id 这个条件,换成 a.organization_no = b.organization_no,下面那个a.id = c.id 换成 a.organization_no = c.organization_no就可以输出你想要的结果了。 |
| LINK:https://ask.csdn.net/questions/7603904?answer=53630072 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603758 |
| ANSWER_ID:53630019 |
| TITLE:在不一致数据转换上遇到问题,表输入预览失败,不知如何推进 |
| ANSWER: 报错是 table "transforms.suppliers" not exists |
| LINK:https://ask.csdn.net/questions/7603758?answer=53630019 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603390 |
| ANSWER_ID:53630000 |
| TITLE:Oracle 如何生成每月累计增加额,查询语句改如何写 |
| ANSWER: 先 生成一个每年每月的数据,然后外关联到基础表,再用你的开窗函数处理。
|
| LINK:https://ask.csdn.net/questions/7603390?answer=53630000 |
| SOURCE:CSDN_ASK |
| ASK_ID:7601803 |
| ANSWER_ID:53629622 |
| TITLE:Mysql查询AS别名显示错误 |
| ANSWER: 猜测字符集设置出了问题,建议尝试先把 "姓名" 改成改成英文字符确认一下看还是否报错 |
| LINK:https://ask.csdn.net/questions/7601803?answer=53629622 |
| SOURCE:CSDN_ASK |
| ASK_ID:7602568 |
| ANSWER_ID:53629606 |
| TITLE:关于Mysql中replace的用法,替换字段的符号处理问题 |
| ANSWER: REPLACE函数的语法为, 在数据库sql中,字符串应该用单引号包起来,像下面这样 |
| LINK:https://ask.csdn.net/questions/7602568?answer=53629606 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603172 |
| ANSWER_ID:53629596 |
| TITLE:请问第一次使用navicat premium发生这个问题,怎么解决 |
| ANSWER: 这是苹果电脑的安全提示,与navicat premium本身无关。破解补丁一般都会报恶意软件的 |
| LINK:https://ask.csdn.net/questions/7603172?answer=53629596 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603254 |
| ANSWER_ID:53629591 |
| TITLE:mysql 时间语句查询 |
| ANSWER: 一条sql的话: 如果要性能好点,先汇总出每天的订单总量,再按上面的方法算,最后用sum(日订单总量)/count(日期) |
| LINK:https://ask.csdn.net/questions/7603254?answer=53629591 |
| SOURCE:CSDN_ASK |
| ASK_ID:7602953 |
| ANSWER_ID:53629576 |
| TITLE:DB2使用with子查询的时候,添加where条件无法进行除法运算 |
| ANSWER: 9除以59的结果是小于1的,你看下是不是显示做了格式化,只保留了整数显示,尝试把显示改成多保留几位小数 |
| LINK:https://ask.csdn.net/questions/7602953?answer=53629576 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603256 |
| ANSWER_ID:53629570 |
| TITLE:谁能将union all之后的多条查询结果横向展示##mysql |
| ANSWER: 看了上面的沟通,这玩意不是excel里面写写公式弄个透视表就出来了么。。。压根不用写什么程序呀。。。 另外,你如果要用sql,完全没必要列转行又转列呀,它本来就是列,你直接一个sql对每个科目的分数进行平均不就好了? |
| LINK:https://ask.csdn.net/questions/7603256?answer=53629570 |
| SOURCE:CSDN_ASK |
| ASK_ID:7602974 |
| ANSWER_ID:53629540 |
| TITLE:mysql 排除指定行数据 |
| ANSWER: 怀疑前端代码处理有误,你可以在数据库中执行一下查询,看结果是否正确 |
| LINK:https://ask.csdn.net/questions/7602974?answer=53629540 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603269 |
| ANSWER_ID:53629531 |
| TITLE:如何提取名称,SQL |
| ANSWER: 截取从第一位到第一个左括号的字符,即 |
| LINK:https://ask.csdn.net/questions/7603269?answer=53629531 |
| SOURCE:CSDN_ASK |
| ASK_ID:7603381 |
| ANSWER_ID:53629525 |
| TITLE:刘哥,我照着你敲代码,网页商品列表查询失败 |
| ANSWER: SELECT COUNT(*) FROM (SELECT id,title,sell_point,price,num,images,item_cat_id,status,created,updated FROM /item) TOTAL |
| LINK:https://ask.csdn.net/questions/7603381?answer=53629525 |
| SOURCE:CSDN_ASK |
| ASK_ID:7602786 |
| ANSWER_ID:53628872 |
| TITLE:dw2021与sql如何建立链接!2021版本 |
| ANSWER: 连数据库其实都是通过其他的公共组件连接的,关它Dreamweaver啥事。。你用其他的工具开发完,用Dreamweaver照样可以打开看页面里面的代码是怎么写的。 |
| LINK:https://ask.csdn.net/questions/7602786?answer=53628872 |
| SOURCE:CSDN_ASK |
| ASK_ID:7602544 |
| ANSWER_ID:53628861 |
| TITLE:一条sql语句怎么删俩张表关联的数据 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7602544?answer=53628861 |
| SOURCE:CSDN_ASK |
| ASK_ID:7602398 |
| ANSWER_ID:53628856 |
| TITLE:什么是数据库事务的一致性 |
ANSWER:
|
| LINK:https://ask.csdn.net/questions/7602398?answer=53628856 |
| SOURCE:CSDN_ASK |
| ASK_ID:7602648 |
| ANSWER_ID:53628835 |
| TITLE:access多条件数据分组怎么做 |
| ANSWER: 用switch函数 |
| LINK:https://ask.csdn.net/questions/7602648?answer=53628835 |
| SOURCE:CSDN_ASK |
| ASK_ID:7602029 |
| ANSWER_ID:53628823 |
| TITLE:将mysql的表同步到oracle后,如何筛选出两端不一致的数据 |
| ANSWER: 同意楼上小彬哥的, |
| LINK:https://ask.csdn.net/questions/7602029?answer=53628823 |
| SOURCE:CSDN_ASK |
| ASK_ID:7601652 |
| ANSWER_ID:53627501 |
| TITLE:sql语句的中定长字符char的疑问 |
| ANSWER: 你对char的定长理解可能有点问题。 |
| LINK:https://ask.csdn.net/questions/7601652?answer=53627501 |
| SOURCE:CSDN_ASK |
| ASK_ID:7601150 |
| ANSWER_ID:53627162 |
| TITLE:请问SQL里面FOR UPDATE加的锁,什么时候释放呢? |
| ANSWER: 不同数据库情况会不一样。 假定你这个过程处于事务中,而且没有自动commit,那么在你执行for update时,就加锁了,而且直到最后你都没有显式的执行"commit;"那么这个锁就没有被释放。 |
| LINK:https://ask.csdn.net/questions/7601150?answer=53627162 |
| SOURCE:CSDN_ASK |
| ASK_ID:7600414 |
| ANSWER_ID:53626757 |
| TITLE:oracle触发器变量不更新 |
| ANSWER: 你不把代码贴出来怎么看是不是有问题? |
| LINK:https://ask.csdn.net/questions/7600414?answer=53626757 |
| SOURCE:CSDN_ASK |
| ASK_ID:7600514 |
| ANSWER_ID:53626729 |
| TITLE:求个ORACLE关于SQL的统计语句 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7600514?answer=53626729 |
| SOURCE:CSDN_ASK |
| ASK_ID:7600547 |
| ANSWER_ID:53626724 |
| TITLE:SQL字段里查询到的在指定位置加- 例如把1999-BGSC-0001改成1999-BGS-C-0001 |
| ANSWER: 先用substr把这个字符串截成两段,然后在中间再拼接一个'-', 其他数据库的字符串拼接方式请自行查找 |
| LINK:https://ask.csdn.net/questions/7600547?answer=53626724 |
| SOURCE:CSDN_ASK |
| ASK_ID:7600603 |
| ANSWER_ID:53626722 |
| TITLE:求一段时间内不连续的时间间隔之和 |
| ANSWER: 开始时间要case when 一下,如果小于8点就当8点算,否则就保留原值; |
| LINK:https://ask.csdn.net/questions/7600603?answer=53626722 |
| SOURCE:CSDN_ASK |
| ASK_ID:7600563 |
| ANSWER_ID:53626711 |
| TITLE:sql里的with as 和视图有什么不同吗 |
| ANSWER: 1.with as 不用创建一个实体对象,可以灵活变化,而视图的sql是固定的 |
| LINK:https://ask.csdn.net/questions/7600563?answer=53626711 |
| SOURCE:CSDN_ASK |
| ASK_ID:7600661 |
| ANSWER_ID:53626704 |
| TITLE:SQL serve咋下载快 |
| ANSWER: 到官网下载,很快,下载页面 |
| LINK:https://ask.csdn.net/questions/7600661?answer=53626704 |
| SOURCE:CSDN_ASK |
| ASK_ID:7600263 |
| ANSWER_ID:53625980 |
| TITLE:SQL2012 错误信息:事务在触发器中结束,批处理已中止。 |
| ANSWER: 这是触发器里面写的业务逻辑,你可以看下这个触发器代码中,"不存在该农户"这句抛错的前面是什么代码,就知道是什么东西数据不满足这个业务要求了 |
| LINK:https://ask.csdn.net/questions/7600263?answer=53625980 |
| SOURCE:CSDN_ASK |
| ASK_ID:7600047 |
| ANSWER_ID:53625779 |
| TITLE:sql server中显示数据时临时改变列名的代码是什么? |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7600047?answer=53625779 |
| SOURCE:CSDN_ASK |
| ASK_ID:7599607 |
| ANSWER_ID:53625624 |
| TITLE:Oracle psu补丁 |
| ANSWER: 此补丁程序已被取代。 31537677 DATABASE PATCH SET UPDATE 11.2.0.4.201020 补丁程序 |
| LINK:https://ask.csdn.net/questions/7599607?answer=53625624 |
| SOURCE:CSDN_ASK |
| ASK_ID:7599390 |
| ANSWER_ID:53625622 |
| TITLE:Oracle11g单机打补丁报Prerequisite check "CheckSystemCommandAvailable" failed. |
| ANSWER: 没有fuser命令,要先安装psmisc |
| LINK:https://ask.csdn.net/questions/7599390?answer=53625622 |
| SOURCE:CSDN_ASK |
| ASK_ID:7598840 |
| ANSWER_ID:53625593 |
| TITLE:SQL 2008 目前有一张销售明细表 有上百万条数据想重置销售流水号如何操作 |
| ANSWER: 你得先说你想要的流水号规则, |
| LINK:https://ask.csdn.net/questions/7598840?answer=53625593 |
| SOURCE:CSDN_ASK |
| ASK_ID:7599446 |
| ANSWER_ID:53625577 |
| TITLE:请问在sql里select只能查询聚合函数或者group by引用过的字段,但有一些表里像name,门店名称,品牌名称这些字段也可以select,是因为这些是主键吗?请问怎么判断哪些字段是主键呢? |
| ANSWER: 所有字段都可以select。 |
| LINK:https://ask.csdn.net/questions/7599446?answer=53625577 |
| SOURCE:CSDN_ASK |
| ASK_ID:7599053 |
| ANSWER_ID:53625569 |
| TITLE:解决oracle 12c中wm_concat函数无效问题 |
| ANSWER: 自问自答?? |
| LINK:https://ask.csdn.net/questions/7599053?answer=53625569 |
| SOURCE:CSDN_ASK |
| ASK_ID:7599787 |
| ANSWER_ID:53625565 |
| TITLE:Oracle巡检脚本大全,服务器可直接部署 |
| ANSWER: 咋发到问答区来了。。。。 |
| LINK:https://ask.csdn.net/questions/7599787?answer=53625565 |
| SOURCE:CSDN_ASK |
| ASK_ID:7599585 |
| ANSWER_ID:53625396 |
| TITLE:sql中给已建表中的列添加数据,为何报错? |
| ANSWER: 插入数据不需要执行alter table,只要执行 insert语句就好了 |
| LINK:https://ask.csdn.net/questions/7599585?answer=53625396 |
| SOURCE:CSDN_ASK |
| ASK_ID:7598781 |
| ANSWER_ID:53624742 |
| TITLE:java的jdbc怎么实现使用有where的select函数? |
| ANSWER: 你可以打印一下 sql + name 这个字符串看长什么样, 这是字符串拼接模式,tom作为一个字符串,在sql中要用单引号引起来, 但是,一般建议用绑定变量的方式,因为这种拼字符串的方式容易被sql注入攻击 |
| LINK:https://ask.csdn.net/questions/7598781?answer=53624742 |
| SOURCE:CSDN_ASK |
| ASK_ID:7598117 |
| ANSWER_ID:53624733 |
| TITLE:sqlzoo懒得复制人名就直接打姓+%为什么显示找不到? |
| ANSWER: 模糊查找要使用 like ,比如 subject like 'prter%' |
| LINK:https://ask.csdn.net/questions/7598117?answer=53624733 |
| SOURCE:CSDN_ASK |
| ASK_ID:7598197 |
| ANSWER_ID:53624724 |
| TITLE:mysql 父节点统计子节点下所有文档数量包括父节点下的文档数量 |
| ANSWER: 由于A表层级不确定,所以肯定要用递归。 如果是8.0版本的mysql,可以使用with递归 效果如下
|
| LINK:https://ask.csdn.net/questions/7598197?answer=53624724 |

| SOURCE:CSDN_ASK |
| ASK_ID:7598136 |
| ANSWER_ID:53624625 |
| TITLE:hibernate ORA-01438: 值大于为此列指定的允许精度 |
| ANSWER: 在plsql developer工具中,使用for update粘贴数据进去,如果存在格式异常的值,对应值的字体颜色会变成红色 |
| LINK:https://ask.csdn.net/questions/7598136?answer=53624625 |
| SOURCE:CSDN_ASK |
| ASK_ID:7597529 |
| ANSWER_ID:53624002 |
| TITLE:存储过程 报 pls-00224 |
| ANSWER: 首先,存储过程中条件判断一般是用if 如果数据小,我建议你直接用merge into; |
| LINK:https://ask.csdn.net/questions/7597529?answer=53624002 |
| SOURCE:CSDN_ASK |
| ASK_ID:7597859 |
| ANSWER_ID:53623994 |
| TITLE:sql语句,同张表内,两个字段A,B,条件是查出b中多个数据符合a字段的值 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7597859?answer=53623994 |
| SOURCE:CSDN_ASK |
| ASK_ID:7597177 |
| ANSWER_ID:53623411 |
| TITLE:SQL 数据转换问题 |
| ANSWER: 这个问题实际上包含了很多个内容,用倒推的思路来分析,
|
| LINK:https://ask.csdn.net/questions/7597177?answer=53623411 |
| SOURCE:CSDN_ASK |
| ASK_ID:7597028 |
| ANSWER_ID:53623390 |
| TITLE:求解这个为什么不出现输密码那一行吗。 |
| ANSWER: -U 参数,这个U是大写的 |
| LINK:https://ask.csdn.net/questions/7597028?answer=53623390 |
| SOURCE:CSDN_ASK |
| ASK_ID:7584062 |
| ANSWER_ID:53622838 |
| TITLE:一个sql优化。求更简单的方法 |
ANSWER: |
| LINK:https://ask.csdn.net/questions/7584062?answer=53622838 |
| SOURCE:CSDN_ASK |
| ASK_ID:7588769 |
| ANSWER_ID:53622833 |
| TITLE:怎么去掉重复列啊,希望得到帮助 |
| ANSWER: 你这对于同一个产品编号的订购数量和单价是有多个值的,你去重后肯定只能留一个值,或者把多个值拼成一个字符串, |
| LINK:https://ask.csdn.net/questions/7588769?answer=53622833 |
| SOURCE:CSDN_ASK |
| ASK_ID:7592371 |
| ANSWER_ID:53622828 |
| TITLE:请问下边的程序咋错了,一直找不到,这个咋改咋改, |
| ANSWER: 你哪里复制的代码,连哪行是要执行的都不知道么?那个query ok是别人执行后返回的结果,你执行它干嘛? |
| LINK:https://ask.csdn.net/questions/7592371?answer=53622828 |
| SOURCE:CSDN_ASK |
| ASK_ID:7595002 |
| ANSWER_ID:53622824 |
| TITLE:sql语句执行问题,group by为什么能用select里用过函数生成的字段 |
| ANSWER: 你这里使用的是别名,这个sql会自动重写为下面这个样子再执行 |
| LINK:https://ask.csdn.net/questions/7595002?answer=53622824 |
| SOURCE:CSDN_ASK |
| ASK_ID:7596987 |
| ANSWER_ID:53622801 |
| TITLE:请问如图的sql应该咋写? |
| ANSWER: 是什么数据库?如果是oracle18c以上的话,你直接把这三个表关联起来,然后查 charge_num, max(money),max(date),listagg(project_num,','),listagg(users,',') 如果是18c以下,listagg要加 within group , 其实你这个问题就是一个将一行数据中的多个值聚合拼接成一个字符串的问题,主流数据库一般都有函数支持,你去找你对应数据库的函数就行了 |
| LINK:https://ask.csdn.net/questions/7596987?answer=53622801 |
| SOURCE:CSDN_ASK |
| ASK_ID:7589060 |
| ANSWER_ID:53622572 |
| TITLE:mysql插入的数据中有分号(;) 如何处理呢 |
| ANSWER: 先说明,在插入语句中 ,插入的字符串都是要用单引号包起来的,单引号里有分号没有任何影响,但题主既然这么问了,肯定是在其他地方遇到了问题,误以为是这个原因,所以: |
| LINK:https://ask.csdn.net/questions/7589060?answer=53622572 |
| SOURCE:CSDN_ASK | ||||||||
| ASK_ID:7594184 | ||||||||
| ANSWER_ID:53622563 | ||||||||
| TITLE:Oracle 函数或者 SQL查询 | ||||||||
ANSWER:输出结果
| ||||||||
| LINK:https://ask.csdn.net/questions/7594184?answer=53622563 |
| SOURCE:CSDN_ASK |
| ASK_ID:7596104 |
| ANSWER_ID:53622530 |
| TITLE:oracle存储过程怎么调用另外一个存储过程 |
| ANSWER: 包里的存储过程在外面调用时,存储过程名称前面要加包名,要不然找不到。另外,这个过程名称也要在包头里声明 |
| LINK:https://ask.csdn.net/questions/7596104?answer=53622530 |
| SOURCE:CSDN_ASK |
| ASK_ID:7596100 |
| ANSWER_ID:53622528 |
| TITLE:oracle未声明绑定变量 |
| ANSWER: 少打了等于号,应该是这样的 |
| LINK:https://ask.csdn.net/questions/7596100?answer=53622528 |
| SOURCE:CSDN_ASK |
| ASK_ID:7596118 |
| ANSWER_ID:53622524 |
| TITLE:Oracle未声明绑定变量 |
| ANSWER: 你如果是想让 7900作为 emp_number的默认值的话,应该要加个等于,在Oracle中,赋值指令是":=" |
| LINK:https://ask.csdn.net/questions/7596118?answer=53622524 |
| SOURCE:CSDN_ASK |
| ASK_ID:7571133 |
| ANSWER_ID:53622516 |
| TITLE:出现符号“”再需要下列之一时:if |
| ANSWER: 少了个end if,因为你是用的 "else if" 而不是 "elsif" |
| LINK:https://ask.csdn.net/questions/7571133?answer=53622516 |
| SOURCE:CSDN_ASK |
| ASK_ID:7576618 |
| ANSWER_ID:53622509 |
| TITLE:Oracle根据月发生额算出每月累计发生额查询该如何写 |
| ANSWER: 很经典的一个开窗函数例子,楼上已有解答 |
| LINK:https://ask.csdn.net/questions/7576618?answer=53622509 |
| SOURCE:CSDN_ASK |
| ASK_ID:7578981 |
| ANSWER_ID:53622508 |
| TITLE:toad for oracle多个spl窗口查询的结果可以输出成一个文件么 |
| ANSWER: 这个用plsql developer是支持的,全部查询并全部展开后,鼠标右键其中一个查询结果,选择复制到excel-全部复制为excel即可将所有数据保存到一个excel文件内 |
| LINK:https://ask.csdn.net/questions/7578981?answer=53622508 |
| SOURCE:CSDN_ASK |
| ASK_ID:7583188 |
| ANSWER_ID:53622505 |
| TITLE:Oracle数据库grant不了为什么? |
| ANSWER: 这个报错就是提示没有SXR这个用户,你可以在这个窗口执行一下 看有没有数据 |
| LINK:https://ask.csdn.net/questions/7583188?answer=53622505 |
| SOURCE:CSDN_ASK |
| ASK_ID:7589226 |
| ANSWER_ID:53622500 |
| TITLE:关于Oracle的目录路径问题 |
| ANSWER: 不存在out_path,请查询all_directory视图确认正确的目录名称 |
| LINK:https://ask.csdn.net/questions/7589226?answer=53622500 |
| SOURCE:CSDN_ASK |
| ASK_ID:7595236 |
| ANSWER_ID:53622494 |
| TITLE:Oracle 19C如何操作? |
| ANSWER: 你既然知道Navicat Premium,那么就用Navicat Premium操作就是了,这个软件支持连接oracle数据库的,而且也提供了导入excel的功能。 |
| LINK:https://ask.csdn.net/questions/7595236?answer=53622494 |
| SOURCE:CSDN_ASK |
| ASK_ID:7596659 |
| ANSWER_ID:53622490 |
| TITLE:SQL 能否通过某一列中的值作为表名,一次性关联查询 |
| ANSWER: 写过程套个游标循环,用动态sql处理吧,动态sql你想怎么拼就怎么拼 如果数据库是oracle的话 输出 另外,你这3个表的BID有没有可能有重复?如果没有重复,建议直接把这3个表union all起来再去关联B表,这样简单得多 |
| LINK:https://ask.csdn.net/questions/7596659?answer=53622490 |
| SOURCE:CSDN_ASK |
| ASK_ID:7576069 |
| ANSWER_ID:53602255 |
| TITLE:关于#docker#的问题:我用的windows,自己把docker转到windows container了,但是在运行dpabisurf还是会报linux的错误 |
| ANSWER: wimdows上的docker是基于的windows内置的linux子系统运行的 |
| LINK:https://ask.csdn.net/questions/7576069?answer=53602255 |
| SOURCE:CSDN_ASK |
| ASK_ID:901868 |
| ANSWER_ID:53549095 |
| TITLE:Oracle中如何对多个字段的值进行判断并计数 |
| ANSWER: 给你个思路, |
| LINK:https://ask.csdn.net/questions/901868?answer=53549095 |
| SOURCE:CSDN_ASK |
| ASK_ID:1008661 |
| ANSWER_ID:53548920 |
| TITLE:oracle子查询中,怎么动态拼接子查询的表名?? |
| ANSWER: 从题目描述来看,题主是有一个A表,A表中有很多id,然后每个id有一个对应的CU表。 |
| LINK:https://ask.csdn.net/questions/1008661?answer=53548920 |
| SOURCE:CSDN_ASK |
| ASK_ID:1091852 |
| ANSWER_ID:53545130 |
| TITLE:oracle 提取 sql中的表名 |
| ANSWER: 在python中使用antlr4解析sql并获取所有表名的代码来了 【python】使用Antlr4实现识别sql中的表或视图名 - Welcome to DarkAthena's World 前言先上成果预览图吧作为一个数据库sql开发者,肯定有很多人和我一样,想要有一个工具,能传入任意sql,解析出sql中的所有表。我之前有一篇文章【AIO】将任意查询sql转换成带远程数据库DBLINK的sql 中就提到了,使用纯文本硬解析会存在很多不确定因素,比如oracle新版本就添加了新的sql https://www.darkathena.top/archives/antlr4-sql-tablename/ |
| LINK:https://ask.csdn.net/questions/1091852?answer=53545130 |
| SOURCE:CSDN_ASK |
| ASK_ID:659976 |
| ANSWER_ID:53543042 |
| TITLE:oracle中按列表分区,插入一个新的列值就要增加分区? |
| ANSWER: 在创建分区的时候,用分区模板来创建,即可实现分区自增,不需要函数或者过程 |
| LINK:https://ask.csdn.net/questions/659976?answer=53543042 |
| SOURCE:CSDN_ASK |
| ASK_ID:796561 |
| ANSWER_ID:53543041 |
| TITLE:oracle 如何解决关联查询字段有保留字或关键字的问题 |
| ANSWER: 这实际上不是冲突,你看下你的表结构,字段名建成小写了,你把你的字段名改成大写就不报错了 |
| LINK:https://ask.csdn.net/questions/796561?answer=53543041 |
| SOURCE:CSDN_ASK |
| ASK_ID:1091852 |
| ANSWER_ID:53543040 |
| TITLE:oracle 提取 sql中的表名 |
| ANSWER: 【AIO】将任意查询sql转换成带远程数据库DBLINK的sql - Welcome to DarkAthena's World 一、背景我工作的时候,有遇到一个场景,有很多个oracle数据库,表结构都一样,但是数据内容不一样,如果要查询一个数据,需要用同一个sql分别去查这很多个数据库的数据,存到同一个地方,再输出合并后的结果。一般情况下,会选择用java/python等语言写个程序来处理这个场景,如果是定时自动收取,这相 https://www.darkathena.top/archives/sqltodblink |
| LINK:https://ask.csdn.net/questions/1091852?answer=53543040 |
| SOURCE:CSDN_ASK |
| ASK_ID:718567 |
| ANSWER_ID:53543039 |
| TITLE:关于ORACLE视图创建ORA-01031问题 |
| ANSWER: grant 赋权的时候,后面加上 with grant option |
| LINK:https://ask.csdn.net/questions/718567?answer=53543039 |
| SOURCE:CSDN_ASK |
| ASK_ID:382974 |
| ANSWER_ID:53543038 |
| TITLE:oracle如何支持存储emoji表情 |
| ANSWER: 存Unicode编码即可 |
| LINK:https://ask.csdn.net/questions/382974?answer=53543038 |
| SOURCE:CSDN_ASK |
| ASK_ID:714491 |
| ANSWER_ID:53543037 |
| TITLE:oracle存储过程中如何写循环? |
| ANSWER: 查DBA分区视图,用你指定的日期条件,得到满足条件的分区名称作为游标,开始循环,拼接动态sql,再execte immediate它,循环结束。注意有锁时的异常处理 |
| LINK:https://ask.csdn.net/questions/714491?answer=53543037 |
| SOURCE:CSDN_ASK |
| ASK_ID:902102 |
| ANSWER_ID:53543036 |
| TITLE:关于oracle如何将一个表多个行转列 |
| ANSWER: 用wm_concat或者listagg即可,选用适当的分隔符,把后面的内容都放到一列里 |
| LINK:https://ask.csdn.net/questions/902102?answer=53543036 |
| SOURCE:CSDN_ASK |
| ASK_ID:676565 |
| ANSWER_ID:53543035 |
| TITLE:oracle中 数据链路(DATABASE LINK),如何查出创建者与创建IP |
| ANSWER: 到数据库服务器上找数据库日志 |
| LINK:https://ask.csdn.net/questions/676565?answer=53543035 |
| SOURCE:CSDN_ASK |
| ASK_ID:674643 |
| ANSWER_ID:53543033 |
| TITLE:ORACLE Date类型怎么去掉星期 |
| ANSWER: 你在你程序里,每次连上数据库后就跑下这段 alter session set nls_date_format='YYYY-MM-DD HH24:MI:SS' oracle的日期在存储里其实是没有格式的,这个显示的格式是客户端会话自己进行的格式化 |
| LINK:https://ask.csdn.net/questions/674643?answer=53543033 |
| SOURCE:CSDN_ASK |
| ASK_ID:675562 |
| ANSWER_ID:53543029 |
| TITLE:本地Oracle数据库访问远程Oracle数据库 |
| ANSWER: 在数据库里访问另一个数据库,最正常的就是用dblink了,也就是题主所说的不希望使用的链路。 |
| LINK:https://ask.csdn.net/questions/675562?answer=53543029 |
| SOURCE:CSDN_ASK |
| ASK_ID:716647 |
| ANSWER_ID:53543028 |
| TITLE:oracle 如何实现一个table,每个用户select * from 表名;查询的结果不同,注意没有where 条件 |
| ANSWER: 创建一个视图,视图中查询这张表并带上where 操作者=user or user='SYS',然后程序里都改用这个视图。 |
| LINK:https://ask.csdn.net/questions/716647?answer=53543028 |
| SOURCE:CSDN_ASK |
| ASK_ID:1103881 |
| ANSWER_ID:53543027 |
| TITLE:oracle数据库加条件查询卡死 |
| ANSWER: 问这种查询效率问题的,应该把会话的等待事件和sql的执行计划贴出来 |
| LINK:https://ask.csdn.net/questions/1103881?answer=53543027 |
| SOURCE:CSDN_ASK |
| ASK_ID:716064 |
| ANSWER_ID:53543026 |
| TITLE:Oracle数据库中如何查询日期大于2018年3月1日的所有数据 |
| ANSWER: 其实吧,这个建议写个函数,遍历所有已知的格式,对传入的字符串进行to_date,报错就换下一种格式,转成功了就return你想要的格式 |
| LINK:https://ask.csdn.net/questions/716064?answer=53543026 |
| SOURCE:CSDN_ASK |
| ASK_ID:684983 |
| ANSWER_ID:53543025 |
| TITLE:请问oracle多列转多行 |
| ANSWER: 用pivot函数直接转它不香么 |
| LINK:https://ask.csdn.net/questions/684983?answer=53543025 |
| SOURCE:CSDN_ASK |
| ASK_ID:815006 |
| ANSWER_ID:53543023 |
| TITLE:如何导出Oracle中数据库的同义词? |
| ANSWER: SELECT * FROM DBA_SYNONYMS |
| LINK:https://ask.csdn.net/questions/815006?answer=53543023 |
| SOURCE:CSDN_ASK |
| ASK_ID:749080 |
| ANSWER_ID:53543022 |
| TITLE:ORACLE触发器如何向客户端抛出自定义错误,同时写表记录该事件? |
| ANSWER: 单独写个自治事务的过程,过程里写插表和commit,触发器遇到错了就调这个过程。 |
| LINK:https://ask.csdn.net/questions/749080?answer=53543022 |
| SOURCE:CSDN_ASK |
| ASK_ID:771435 |
| ANSWER_ID:53543021 |
| TITLE:oracle中怎么截取字符串的某个值 |
| ANSWER: 12c以上版本原生支持json查询及操作 |
| LINK:https://ask.csdn.net/questions/771435?answer=53543021 |
| SOURCE:CSDN_ASK |
| ASK_ID:1082030 |
| ANSWER_ID:53543018 |
| TITLE:Oracle 获取上个月最后三天的时间 |
| ANSWER: trunc(sysdate,'mm')-1,trunc(sysdate,'mm')-2,trunc(sysdate,'mm')-3就行了,to_char自己加。 |
| LINK:https://ask.csdn.net/questions/1082030?answer=53543018 |
| SOURCE:CSDN_ASK |
| ASK_ID:1097886 |
| ANSWER_ID:53543016 |
| TITLE:oracle查询出重复的名称,怎么通过拼接序号区分重复 |
| ANSWER: select name||row_number()over(partition by name order by 你排序的字段 ) from tab |
| LINK:https://ask.csdn.net/questions/1097886?answer=53543016 |
| SOURCE:CSDN_ASK |
| ASK_ID:887433 |
| ANSWER_ID:53543015 |
| TITLE:oracle update 和order by 问题 |
| ANSWER: 要更新哪些数据,已经被where限定了,要更新成什么值,set里也确定了,此时order by没有意义! |
| LINK:https://ask.csdn.net/questions/887433?answer=53543015 |
| SOURCE:CSDN_ASK |
| ASK_ID:716152 |
| ANSWER_ID:53543014 |
| TITLE:关于Oracle依据时间条件查找的问题 |
| ANSWER: 按照你的描述写的就是存储过程。 |
| LINK:https://ask.csdn.net/questions/716152?answer=53543014 |
| SOURCE:CSDN_ASK |
| ASK_ID:1105015 |
| ANSWER_ID:53543013 |
| TITLE:oracle 能否使用语句修改存储过程 |
| ANSWER: 如果你是想要在存储过程中修改另一个存储过程,使用动态sql来执行ddl创建或修改命令即可。 |
| LINK:https://ask.csdn.net/questions/1105015?answer=53543013 |
| SOURCE:CSDN_ASK |
| ASK_ID:1103077 |
| ANSWER_ID:53543012 |
| TITLE:Oracle 19C system账号不能登录 |
| ANSWER: 你启动的sqlplus路径可能不对,读到了另一个tnsnames文件,建议找到你能登录的net Manager 所安装的文件夹中里的sqlplus启动 |
| LINK:https://ask.csdn.net/questions/1103077?answer=53543012 |
从此处向上开始半自动同步
27.https://bbs.csdn.net/topics/600475113
Q:
| id | i1 | i2 | i3 | i4 | i5 | i6 | i7 | i8 | i9 | i10 | i11 | i12 | i13 | flag |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 25644 | 0.23 | 0.25 | 0.24 | 0.26 | 0.24 | 0.25 | 0.26 | 0.24 | ||||||
| 25655 | 0.23 | 0.25 | 0.24 | 0.26 | 0.24 | 0.25 | 0.26 | 0.24 | 0.25 | 0.26 | 0.27 | 0.24 |
如表格所示,如何判断一行内的数据连续4个点为空,将连续4个点为空的行,添加标记。
怎么进行判断,谢谢!
A:
假定你的id是唯一键,要判断的字段名称都是i加连续数字,另外也不确定是否存在为0的值,
方案一:
那么最不用思考的做法就是你的提问本身,即一行一行找,然后每四个连续字段判断是否为空,这里就涉及到两个循环了
DECLARE
I NUMBER;
L_SQL VARCHAR2(4000);
begin
for rec in (select id from test_t) loop
FOR I IN 1 .. 10 LOOP
L_SQL := 'update test_t set flag=1 where id=' || to_char(rec.id) ||
' and coalesce(' || 'i' || to_char(i) || ',' || 'i' ||
to_char(i + 1) || ',' || 'i' || to_char(i + 2) || ',' || 'i' ||
to_char(i + 3) || ') is null';
execute immediate l_sql;
end loop;
end loop;
end;
/
其实代码还能优化,比如某一行已经更新过了就直接跳到下一行,减少无效执行;
如果你要判断的字段名称无规律,那么就结合dba_tab_cols视图来生成动态sql
方案二:
你可以把这些字段名通过unpivot函数转到一列里去,让这些数值都变成一列,然后使用开窗函数count最近四行的值,对这个值进行判断即可(空值不会被count),这样就不用写过程,一个sql就能完成你的要求,你有兴趣可以自己尝试写下
方案三:
另外还有个比较脑洞而且超级简单的做法,大家都知道,空没有长度,几个空拼在一起还是一个空 ,如果使用NVL把空值变成你这个表中不存在的一个值,比如字母"A",然后把这些字段全部用管道符拼成一个字符串,那么就只需要判断这个字符串中是否存在 “AAAA”了,存在的那行就是要标记的那行
update test_t
set flag = 1
where INSTR(nvl(to_char(i1), 'A') || nvl(to_char(i2), 'A') ||
nvl(to_char(i3), 'A') || nvl(to_char(i4), 'A') ||
nvl(to_char(i5), 'A') || nvl(to_char(i6), 'A') ||
nvl(to_char(i7), 'A') || nvl(to_char(i8), 'A') ||
nvl(to_char(i9), 'A') || nvl(to_char(i10), 'A') ||
nvl(to_char(i11), 'A') || nvl(to_char(i12), 'A') ||
nvl(to_char(i13), 'A'),
'AAAA') > 0;
26.https://www.modb.pro/issue/10876
Q:
想把以下的语句,mysql移植到Oracle, 其中的limit offset怎么改呢?
SELECT (SELECT DISTINCT Salary
FROM Employee
ORDER BY Salary DESC
LIMIT 1 OFFSET 1) AS SecondHighestSalary
A:
在oracle12c以后,支持如下写法
select * from emp fetch first 10 row only;
select * from emp order by sal first fetch 5 row only;
select * from emp order by sal offset 3 rows fetch next 5 rows only;
select * from emp fetch next 0.1 percent rows only;
25.https://www.modb.pro/issue/10647
Q:
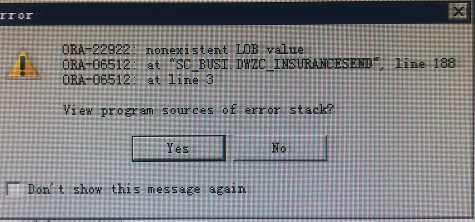
A:
以前我遇到过类似的问题,那个项目中我使用了wm_concat这个函数,sql比较复杂,直接查询没问题,放到存储过程中就报ora-22922,后来换成用listagg就好了,但我不确定题主是不是遇上了同样的问题
24.https://ask.csdn.net/questions/716152
Q:
关于Oracle依据时间条件查找的问题
oracle
我要从Oracle数据库中查询一条数据,SQL语句如下:
select
tb.data1
from table tb
where to_char(tb.date,'yyyy-MM-dd') = '2018-12-06'
要实现的功能是:
如果2018-12-06这天查出的数据为空,则时间向前推一天继续查找,也就是继续查2018-12-05的数据;
如果还没有查找到,继续向前推一天,知道查到的数据不为空为止。
这个功能该怎么实现???
(不限存储过程、存储函数)
在线等。。。
A:
按照你的描述写的就是存储过程。
不过要学会转弯,你想想你这个描述是不是等价于 小于等于指定日期的数据中,日期最大的数据呢?何必写个循环一天天找 ,明明一次性就能找到
23.https://ask.csdn.net/questions/1097886
Q:
oracle查询出重复的名称,怎么通过拼接序号区分重复
oracle
oracle查询出两个重复书名:book,怎么让这个书名查出来是book1、book2,有多个重复的话序号自增
表结构: name
book
pen
book
paper
book
预期的结果 : name
book1
pen
book2
paper
book3
A:
select name||row_number()over(partition by name order by 你排序的字段 ) from tab
22.https://ask.csdn.net/questions/1082030
Q:
Oracle 如何获取当前时间的上个月最后三天的日期以yyyy-MM-dd的格式
A:
trunc(sysdate,'mm')-1,trunc(sysdate,'mm')-2,trunc(sysdate,'mm')-3就行了,to_char自己加。
21.https://ask.csdn.net/questions/771435
Q:
oracle中怎么截取字符串的某个值

oracle中怎么截取红框中的那部分值
A:
12c以上版本原生支持json查询及操作
如果是11g版本或以下,可以安装开源的pljson组件,来支持json的查询
20.https://ask.csdn.net/questions/749080
Q:
ORACLE触发器如何向客户端抛出自定义错误,同时写表记录该事件?
ORACLE建立一个触发器,记录pat_visit 表的某字段被修改的情况,写入tmp_msg表。
记录部分是正常工作的,直到后来为了向客户端抛出错误提示“非法操作,护士……”增加了后面的raise_application_error那一大段。
如果抛出自定义异常的话,前面的记录操作也一同失效,即使是加了commit也不管用。
如何能够即抛出自定义异常同时又能修改(其他表)记录呢?
create or replace trigger TMP_REC_WHO_CHANGE_ADDEPT
before update of dept_admission_to on pat_visit
for each row
--监视pat_visit入院科室改动
declare
mymsg varchar(2000);
begin
select ... into mymsg from v$session where audsid=sys_context('USERENV','SESSIONID');
if :old.dept_admission_to <> :new.dept_admission_to then
insert into tmp_msg(rec_creator,rec_msg)
values ('REC_WHO_CHANGE_ADDEPT',mymsg);
commit; --如果下方向客户端抛出异常,提交也不起作用
if upper(mymsg) like '%NURSE.EXE%' then
if sysdate - nvl(:old.admission_date_time,sysdate) > 0.25 then
raise_application_error('-20002', '非法操作,护士站尝试修改入院日期');
end if;
end if;
end if;
end tmp_rec_who_change_ADDEPT;
A:
单独写个自治事务的过程,过程里写插表和commit,触发器遇到错了就调这个过程。
19.https://ask.csdn.net/questions/716064
Q:
Oracle数据库中如何查询日期大于2018年3月1日的所有数据
现Oracle数据库中有一个表T,表中的字段有T_name,T_sex,T_date
其中T_date的数据类型为varchar2,录入的时间格式多样:
2018-08-01 00:00:00
2018-8-1 9:00:00
2018-8-01 9:00:00
2018-08-1 9:00:00
2018/8/1
2018/08/01 00:00:00
2018/8/1 9:00:00
2018/8/1
2018-10-24 星期日 下午 9:00:00
2018-10-24 星期日 下午 23:00:00
且较多的为:2018-08-01 00:00:00
2018-8-1 9:00:00
2018-8-01 9:00:00
2018-08-1 9:00:00
2018/8/1
2018/08/01 00:00:00
2018/8/1 9:00:00
2018/8/1 ,几万条里会有那么3-4个,2018-10-24 星期日 下午 9:00:00
2018-10-24 星期日 下午 23:00:00.
问:如何查询出字段T_date 中日期大于2018年3月1日的所有数据,最低限度是要查出除了含有2018-10-24 星期日 下午 9:00:00
2018-10-24 星期日 下午 23:00:00这两种格式的所有数据
A:
其实吧,这个建议写个函数,遍历所有已知的格式,对传入的字符串进行to_date,报错就换下一种格式,转成功了就return你想要的格式
18.https://ask.csdn.net/questions/716647
Q:
oracle 如何实现一个table,每个用户select * from 表名;查询的结果不同,注意没有where 条件
oracle 如何实现一个table,每个用户进行查询看到的结果不同;只有管理员可以看到所有的内容
比如说:system用户(或sys)创建了一个表 test;
hr,scott,oe 等非dba权限的用户分别进行多次insert操作
scott用户执行 select * from 该表test;(注意没有where条件)只能看见自己dml后的结果,不能看到hr用户执行DML后的数据,只能update ,delete 自己的数据,
hr用户执行 select * from 该表test;(注意也没有where条件)也只能看见自己dml后的结果,不能看见scott用户的操作,只能update ,delete 自己的数据,
sys或system用户 select * from test; 能看见所有用户DML后的操作,
除sys或system用户外,所有的用户都不能drop table test ;只有sys或system才能drop table test
请问 如何实现上述问题,该用 oracle的什么技术实现??
A:
创建一个视图,视图中查询这张表并带上where 操作者=user or user='SYS',然后程序里都改用这个视图。
至于增删改操作,可以使用视图触发器来操作
17.https://ask.csdn.net/questions/902102
Q:
关于oracle如何将一个表多个行转列
遇到一个复杂点的关系,需要建立一个视图去关联主表,但是公司平台方法只支持同一ID的数据一条对一条,所以需要多行去转列,需要建立视图的表大概是这个样子
table:tmp1
| ID | NAME | AGE |
|---|---|---|
| 1 | 张三 | 25 |
| 2 | 李四 | 27 |
| 2 | 王五 | 30 |
| 3 | 赵六 | 29 |
| 3 | 孙七 | 20 |
| 3 | 周八 | 28 |
| .... | ||
| 大致为有1-4条不定的同ID数据(就是ID有一条为1的,也有俩条为2的,三条为三的这个样子),然后需要把同ID的数据合并成一行,大致期望结果为 |
table:tmp2
| ID | NAME1 | AGE1 | NAME2 | AGE2 | NAME3 | AGE3 |
|---|---|---|---|---|---|---|
| 1 | 张三 | 25 | null | null | null | null |
| 2 | 李四 | 27 | 王五 | 30 | null | null |
| 3 | 赵六 | 29 | 孙七 | 20 | 周八 | 28 |
| .... |
期望得到的表其实也不必要非要一致,只要能把同ID的数据后面的信息全部显示出来就可以,来个大神帮忙啊!!
备注:ID实际为uid
A:
用wm_concat或者listagg即可,选用适当的分隔符,把后面的内容都放到一列里
16.https://ask.csdn.net/questions/714491
Q:
oracle存储过程中如何写循环?
我现在需要一个存储过程,这个存过里只存放删除 XXXX_TABLE表 的分区语句,只保留每个月最后一天的分区,我该怎么写啊
A:
查DBA分区视图,用你指定的日期条件,得到满足条件的分区名称作为游标,开始循环,拼接动态sql,再execte immediate它,循环结束。注意有锁时的异常处理
15.https://ask.csdn.net/questions/796561
Q:
oracle 如何解决关联查询字段有保留字或关键字的问题
如一个表叫TEST_TABLE 其中有个字段名是 main_id
main_id貌似和保留字MAIN冲突
SELECT main_id FROM TEST_TABLE
会报错 ORA-00904: "MAIN_ID": invalid identifier
这样加了双引查询没问题
SELECT "main_id" FROM TEST_TABLE
但是如果关联查询时候应该怎么写
SELECT
A."main_id"
FROM TEST_TABLE A
LEFT JOIN
OTHER_TABLE B
ON A."main_id"=B.other_id
这样报错
SELECT
"A.main_id"
FROM TEST_TABLE A
LEFT JOIN
OTHER_TABLE B
ON "A.main_id"=B.other_id
这样也报错
SELECT
A.'main_id'
FROM TEST_TABLE A
LEFT JOIN
OTHER_TABLE B
ON A.'main_id'=B.other_id
单引也不行
A:
这实际上不是冲突,你看下你的表结构,字段名建成小写了,你把你的字段名改成大写就不报错了
14.https://ask.csdn.net/questions/1008661
Q:
oracle子查询中,怎么动态拼接子查询的表名??
有一张表A,一张表B表,B表的表名为A表的id+‘CU’,
怎么在子查询的时候拼接表名去做查询。
create table A(
id varchar2 not null,
name varchar2 not null,
PRIMARY KEY ("ID")
);
create table A.ID||'CU'(
id varchar2 not null,
num varchar2 not null,
primary key("id")
);
-- 想实现下方这样的动态查询(会报错)
select A.name ,
(select sum(num) from A.ID||'CU' )
from A ;
也有使用函数的方式来拼接表名,也行不同,请问各位大佬有什么方法可以解决。
A:
从题目描述来看,题主是有一个A表,A表中有很多id,然后每个id有一个对应的CU表。
首先第二步建表这个动作肯定是报错的,先假设你是手动拼接已经建好了,只是要看如何实现查询。
假设你这个数据是用于存储过程中,那么使用动态sql拼接sql的字符串再 execute immediate它就行了。
如果是想直接用于select查询出结果展示,那么有两个方案:
方案一:新建个函数,输入sql返回游标,使用select * from table(函数('sql'))的方式查询;
方案二:对于18c以上版本,可以使用多态表函数功能
13.https://www.modb.pro/issue/8092
Q:
ORACLE子表链接主表,主表的数据只显示在第一行怎么做到
像这种,子表链接主表,主表的数据只显示在第一行。
A:
一般来说,主表和子表关联,主表的数据会显示和子表一样的行数,而且会重复,我猜你的意思是,对于主表中的每一行记录,在结果中都只保留一条。
先说问题,从你这个格式中来看,如果有人对这个数据进行了排序,那么你就会丢失子表和主表的关系,如果非得用这个格式,建议至少要新增一个行号。
然后解决方案,你想要的是保留一条,换个角度其实就是,不是第一条的全部置为空。
首先用最基本的关联,然后用count() over(partiotion by 单据编号 order by 产品名称) 构造一列,在不改变行数的情况下,得到每张单据的子表行数,
再用decode或者case when 判断这个值,如果是1,那么就显示单据主表的值,如果不是,就显示空。
注意最后一定要按单据编号加产品名称排序
12.https://www.modb.pro/issue/10804
Q:
达梦数据库之间如何进行数据迁移,在2个库都有表结构和数据的情况下?
A:
和oracle的语法几乎一样,导入的时候带上 IGNORE=Y ,即可忽略表对象已存在的情况,直接插入数据
./dimp USERID=SYSDBA/SYSDBA@192.168.0.248:8888 FILE=db_str.dmp DIRECTORY=/mnt/data/dexp LOG=db_str.log FULL=Y IGNORE=Y
参考 https://www.dameng.com/list_110.html 达梦技术手册-DM8_dexp和dimp使用手册.pdf
11.https://www.modb.pro/issue/10584
Q:
navicat操作oracle怎么创建用户设置表的可见以及可不见权限?
A:
ORACLE中的授权,基本都是通过grant命令来执行的
新建一个用户,当仅仅指定了该用户的用户名及密码,该用户几乎无法执行任何操作
需要授权连接、创建会话,指定表空间及可用大小,此时该用户拥有在该用户下创建表和查询表的权限,没有查询其他用户的表的权限
如果需要让这个用户查询到其他用户的表,那么则需要登录到其他用户,执行
grant select on 表名 to 查询用户
10.https://www.modb.pro/issue/10464
Q:
sql查询怎么计算当列空值与非控制比例?
A:
select decode(count(id),0,null, (count(1)-count(id))/count(id)) from t
9.https://www.modb.pro/issue/10478
Q:
MySQL中 varchar 类型的,用max 函数,有没有什么影响?
A:
没有什么影响,如果内容是纯数字,那么建议+0 或者cast成数字再max,如果包含有非数字,就是按从左往右字母依次排序的结果
8.https://www.modb.pro/issue/10525
Q:
Oracle数据库中表关联查询,其中一个字段为空,怎么能显示出来?
A:
假设T1表数据是全的,T2不全
SELECT * FROM T1 ,T2 WHERE T1.A=T2.A(+)
假设两个表都有不全
select * from t1 full join t2 on t1.a=t2.a
假设有三个表可能都不全
select * from t1 full join t2 on t2.a=t1.a full join t3 on t3.a=nvl(t2.a,t1.a)
7.https://www.modb.pro/issue/10583
Q:
oracle一般什么情况下需要使用视图?
A:
以下内容为个人工作经验,非教科书标准答案
1.数据查询权限控制:
比如不想让指定用户看到某些行或者某些列,就可以创建一个这样的视图,然后将这个视图授权给该用户查询,此时用户无原表权限,但是能看这个视图里的数据
2.精简sql或者模块化sql:
有时候sql会写得比较长,影响可读性,可以把一个具有特定意义的子查询变成一个视图,此时其他场景下也只需要引用这个视图而不需要写一大串sql了,常见于报表sql
3.UI应用程序需要:
有些展现程序只能指定表名和字段名来展现数据,此时就必须建立一个视图了
6.https://www.modb.pro/issue/10585
Q:
mysql有没有类似strip()这种类型的函数?
trim只能是空格
A:
trim的语法 TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
BOTH 首尾
LEADING 首
TRAILING 尾
remstr 要去掉的字符
str 要处理的字符串
例
SELECT TRIM(BOTH ',' FROM ',,aaaa,,,');
aaaa
5.https://www.modb.pro/issue/10408
Q:
先执行sql语句 A(如果id=1存在,就更新X字段为1,如果不存在就插入),然后不等结果返回(异步执行),立即执行语句B(如果id=1存在,就更新X字段为2,如果不存在,就插入)。 那最后的结果,有没有可能 X 字段是 1 呢?
A:
如果id是唯一键,那么在修改或者插入这行的时候,不管有没有执行完,都会把这行锁起来,另一个会话想插入或者修改都是等待的,直到第一个会话commit。这个时候引入到第二个问题,where 条件 是否会检索未commit的数据?答案是不会。也就是说,只要会话A没提交,那么会话B的where就找不到这笔数据,按照题目来说,此时执行insert,是会被会话A锁的,等会话Acommit,会话B马上报错,提示违反唯一约束。
4.https://www.modb.pro/issue/10548
Q:
oracle表没有date类型的字段可以用在线重定义做range分区吗
数据库有一张表80个G了没做分区,本来打算用重定义转成分区表,看了下字段类型,所有字段类型都是varchar2的,比如createtime、updatetime这些字段的类型都是varchar2的,请问可以用在线重定义转吗
A:
--原表
CREATE TABLE table_o (ID NUMBER PRIMARY KEY, TIME varchar2(20))
;
--插入测试数据
insert into table_o values(123,'2021-01-03 12:00:00');
commit;
--新表,用varchar2字段做range分区
CREATE TABLE table_n (ID NUMBER PRIMARY KEY, TIME varchar2(20))
PARTITION BY RANGE (TIME)
(PARTITION P1 VALUES LESS THAN ('2021-01-01 00:00:00'),
PARTITION P2 VALUES LESS THAN ('2021-02-01 00:00:00'),
PARTITION P3 VALUES LESS THAN ('2021-03-01 00:00:00'),
PARTITION P4 VALUES LESS THAN (MAXVALUE));
--校验是否可以重定义
begin
DBMS_REDEFINITION.CAN_REDEF_TABLE(USER, 'table_o', DBMS_REDEFINITION.CONS_USE_PK);
end;
/
--开始重定义
begin
DBMS_REDEFINITION.START_REDEF_TABLE(USER,
'table_o',
'table_n');
end;
/
--模拟增量数据产生
insert into table_o values(456,'2021-02-03 12:00:00');
commit;
--同步增量数据
begin
dbms_redefinition.sync_interim_table(USER, 'table_o', 'table_n');
end;
/
--完成重定义
begin
DBMS_REDEFINITION.FINISH_REDEF_TABLE(USER, 'table_o', 'table_n');
end;
/
3.https://www.modb.pro/issue/10181
Q:
oracle 怎么模拟增加lob大字段数据
oracle 怎么模拟增加lob大字段数据,我想模拟插入数据增大lob的segment大小,一直不成功
我创建了表:
create table itpux03
( id int,
clog clob
)
lob (clog) store as securefile
(tablespace users)
查入数据
begin
for i in 1..500000 loop
INSERT INTO itpux03 VALUES(i, 'asdasdasdasdasdasdasdasdasdad');
commit;
end loop;
end;
/
检查:
SEGMENT_NAME M
------------------------- ----------
ITPUX01 5245
ITPUX03 987
ITPUX02 96
SYS_LOB0000105311C00002$$ .13
SYS_LOB0000105129C00003$$ .13
SYS_LOB0000105314C00002$$ .13
BIDX .06
SYS_IL0000105311C00002$$ .06
SYS_IL0000105129C00003$$ .06
SYS_IL0000105314C00002$$ .06
表的大小一直增加 但是lob字段的大小一直0.13m,想请教大神们,如何增大lob字段的数据。我也尝试过用
DBMS_LOB.Write也是没有效果。。。如果能附带案列 就十分感谢了
A:
你那个创建新行,实际上是增加新的lob,如果要在原lob上增加,应该使用append,如下,已实测通过
create table itpux03
( id int,
clog clob
);
INSERT INTO itpux03 VALUES(1,1);
DECLARE
l_line varchar2(4000);
l_clob clob;
BEGIN
l_line := 'FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF';
SELECT clog
INTO l_clob
FROM itpux03
WHERE id = 1 for update;
dbms_lob.open(l_clob, dbms_lob.lob_readwrite);
for i in 1..5000 loop
dbms_lob.writeappend(l_clob, lengthb(l_line), l_line);
end loop;
dbms_lob.close(l_clob);
commit;
END;
/
插入第一行时,lob大小为 131072,执行过程块后,lob大小变为 2228224
2.来源:https://ask.csdn.net/questions/901868
Q:
数据库中根据业务表创建了视图,存储有SSRQ1-6、SSJB1-6共12个字段,同时新增了四个字段S1-S4用来存储SSJB1-6中对应数值的计数
图片说明
业务场景为:
每一条数据表示一个个案,需要统计每个个案中各级别手术的个数
业务需求是:
当SSRQ1-6中任意两个字段有相同值时,取SSJB1-6中数值最大的,在对应的级别下计数+1;
当SSRQ1-6中存在不同值时,每个对应的SJJB都需要取,在对应的级别下计数+1
例如:
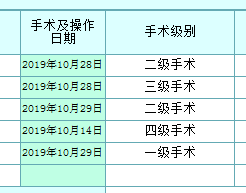
图片说明
28日有二级/三级手术,取三级手术,S3下计数+1;
29日有一级/二级手术,取二级手术,S2下计数+1;
14日有四级手术,S4下计数+1;
汇总后该条个案对应的S1-S4分别为0/1/1/1
求问大神这样用sql语句怎么实现
case when 和decode都试过了
A:
给你个思路,
1.理论上,你这个每行本身应该有个id,假设没有,就先用rownum 替代id。
2.有6个字段表示日期,这6个字段应该可以做行列转换变成一列。
3.手术级别的6个字段,也同样做行列转换变成一列
4.然后用开窗函数,按id加日期分组,取每组数字最大对应的手术级别,得到3列数据
5.distinct 这3个字段,完成
with t as
(select id, 日期, 级别
from temp_test1 unpivot((日期, 级别) for dd in((SSRQ1, SSJB1),
(SSRQ2, SSJB2),
(SSRQ3, SSJB3),
(SSRQ4, SSJB4),
(SSRQ5, SSJB5),
(SSRQ6, SSJB6)))),
t2 as
(select distinct t.id,
t.日期,
first_value(级别) over(partition by ID, 日期 order by 级别 desc) 级别
from t)
1.来源:https://www.modb.pro/issue/10292
Q:
一个麻烦的UNPIVOT实现
表结构如下:
| ENTITY_CODE | A公司 | B公司 |
|---|---|---|
| AMOUNT_A_1YUE | 100 | |
| AMOUNT_B_1YUE | 200 | |
| AMOUNT_C_1YUE | 300 | |
| AMOUNT_A_2YUE | 150 | |
| AMOUNT_B_2YUE | 250 | |
| AMOUNT_C_2YUE | 350 |
如何转换为
| ENTITY_CODE | PERIOD(期间) | AMOUNT_A | AMOUNT_B | AMOUNT_C |
|---|---|---|---|---|
| A公司 | 1月 | 100 | 200 | 300 |
| B公司 | 2月 | 150 | 250 | 350 |
A:
create table test_pivot (ENTITY_CODE varchar2(20),A公司 varchar2(20), B公司 varchar2(20));
with t1 as
(select regexp_substr(ENTITY_CODE, '[^_]+', 1, 2) ENTITY_CODE,
REPLACE(regexp_substr(ENTITY_CODE, '[^_]+', 1, 3), 'YUE', '月') PERIOD,
A公司,
B公司
from test_pivot),
t2 as
(select * from t1 unpivot(amount FOR 公司 in(A公司, B公司)))
select *
from t2
pivot (sum(amount) for ENTITY_CODE in('A' AMOUNT_A,
'B' AMOUNT_B,
'C' AMOUNT_C))
;