





一、背景
一直以来,很多用过ORACLE数据库的开发人员,都知道在ORACLE中,字符类型可以为varchar2,也可以为nvarchar2,但是很多人都不知道这两种类型有什么区别,同样还有char/nchar,clob/nclob这些,所以今天来谈谈我对这些数据类型的理解。
二、传言
老的oracle开发人员中,可能流传这这样一句传言,
“如果要省存储空间,建表时,字段内容里如果中文占了大多数,就用nvarchar2类型;如果内容是英文和数字为主的字符串,就用varchar2类型。”
首先说明一下,这句话在绝大多数情况下,的确是对的。
但是,这其实,是在特定的条件下,仅用例证得到的结论,后面会说明原因。
三、实验及分析
我们先做个实验,看看为什么会有上面这个传言
假设数据库字符集为AL32UTF8,建个表,两个字段,分别为varchar2和nvarchar2,插入数字、英文字母、汉字
CREATE TABLE TEST_CHARSET (A VARCHAR2(100), B NVARCHAR2(100));
INSERT INTO TEST_CHARSET VALUES (12,n'12');
INSERT INTO TEST_CHARSET VALUES ('ab',n'ab');
INSERT INTO TEST_CHARSET VALUES ('啊',n'啊');
然后使用lengthb/dump等函数查看字节长度
select dump(a,1016),dump(b,1016),t.* from TEST_CHARSET t;
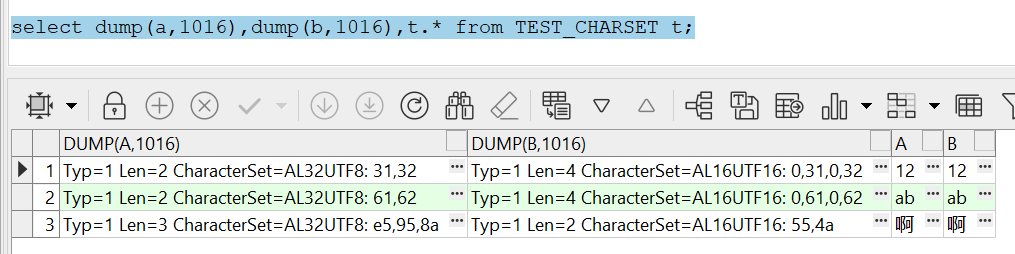
看上去,的确对于汉字,nvarchar2的长度比varchar2要短,看上去不论啥字符插入到nvarchar2中都是2个字节,对于数字和字母就太占空间了。
但是,nvarchar2的字符集显示的是AL16UTF16,而非varchar2对应字段中的AL32UTF8
所以,我们得回头看看,nvarchar2这个数据类型到底是什么
官方文档说
数据类型指定国家字符集中的NVARCHAR2变长字符串。创建数据库时,将国家字符集指定为 AL16UTF16 或 UTF8。AL16UTF16 和 UTF8 是 Unicode 字符集的两种编码形式(对应的 UTF-16 和 CESU-8),因此NVARCHAR2是仅限 Unicode 的数据类型。
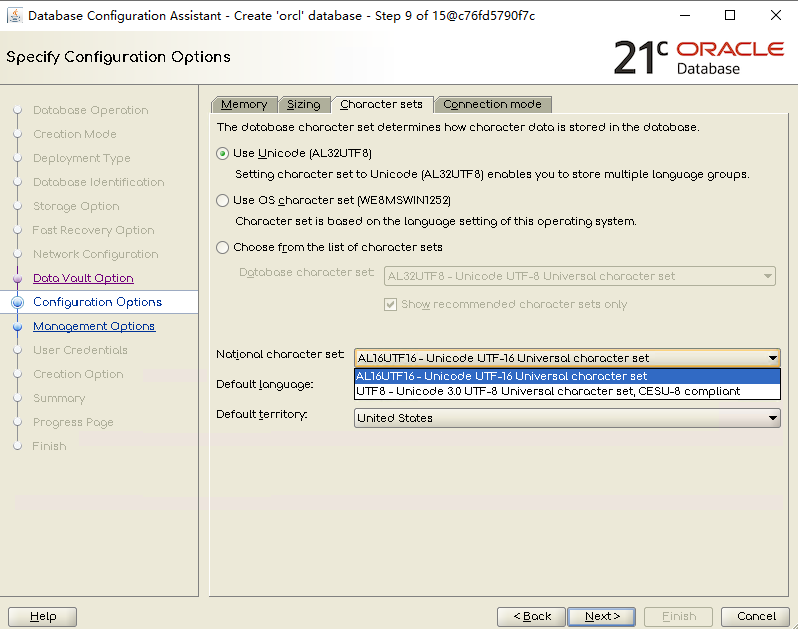
在21c数据库创建界面中可以看到,数据库默认字符集编码为AL32UTF8,国家字符集编码默认为AL16UTF16,可选UTF8。
文档说
一个代码点在 AL16UTF16 中始终具有 2 个字节,在 UTF8 中始终具有 1 到 3 个字节,具体取决于代码点编码的特定字符。
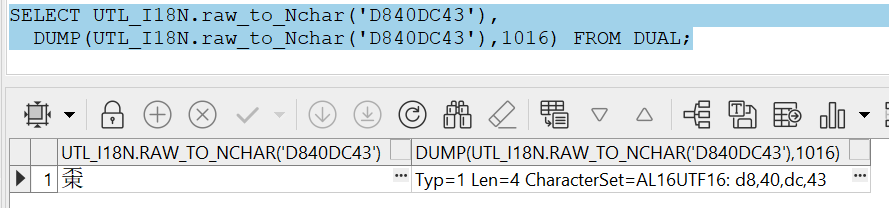
文档此处存在歧义,AL16UTF16也会有4个字节的情况,比如
SELECT UTL_I18N.raw_to_Nchar('D840DC43'),
DUMP(UTL_I18N.raw_to_Nchar('D840DC43'),1016) FROM DUAL;
Oracle Database 21c 支持 Unicode 版本 12.1
我特意去翻了unicode12.1版本的文档,发现补充码的部分对应不上,所以ORACLE这句话其实是有前提条件的
https://www.unicode.org/Public/12.1.0/charts/CodeCharts.pdf
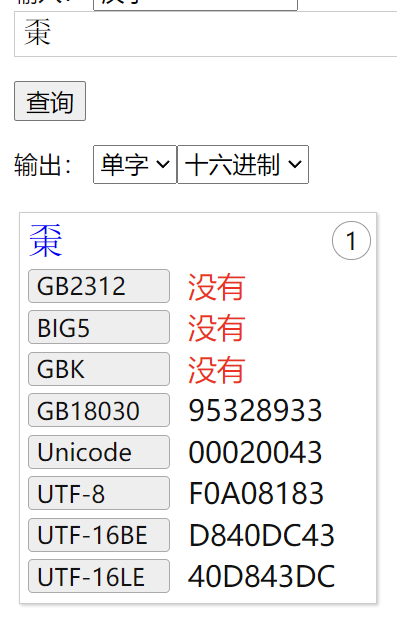
oracle的UTF-8为1到3个字节,而unicode标准中的UTF-8是1~4个字节,所以oracle的UTF-8也不符合unicode标准,甚至还会把unicode中FFFF后面的字符,转换成6个字节来进行存储,比如unicode编码20043(𠁃),对应的UTF-16的D840DC43,存成UTF-8则为eda180edb183,但按照UNICODE标准,它的UTF-8编码应该为F0A08183
其实默认情况下,oracle中的UTF-8根本就不是UTF-8,而是CESU-8,这个在ORACLE官方文档中有提到
https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/Data-Types.html#GUID-CC15FC97-BE94-4FA4-994A-6DDF7F1A9904
AL16UTF16 和 UTF8 是 Unicode 字符集的两种编码形式(对应的 UTF-16 和 CESU-8)
而且ORACLE官方文档还这么说了
https://docs.oracle.com/en/database/oracle/oracle-database/21/nlspg/supporting-multilingual-databases-with-unicode.html#GUID-F3B0B4F7-B6D9-473D-840F-F98998F37981
CESU-8 不是核心 Unicode 标准的一部分。Unicode 联盟发布的 Unicode 技术报告 #26 对此进行了描述。CESU-8 是一种与 UTF-8 相同的兼容性编码形式,除了它的补充字符表示。在 CESU-8 中,补充字符被表示为代理对,就像在 UTF-16 中一样。要获得补充字符的 CESU-8 编码,首先将字符编码为 UTF-16,然后将每个代理代码单元视为具有相同值的代码点。然后,将 UTF-8 编码规则(位转换)应用于每个代码点。这将产生两个三字节表示,总共六个字节。
CESU-8 只有两个好处:
它具有与 UTF-16 相同的二进制排序顺序。
每个字符使用相同数量的代码(一个或两个)。这对于字符串处理中的字符长度语义很重要。
一般来说,应尽可能避免使用 CESU-8 编码形式。
关于CESU-8,可以参考下面这个对比
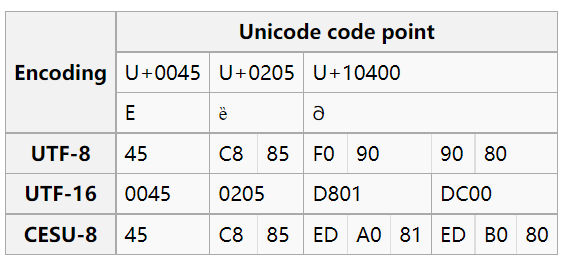
(此表来自https://infogalactic.com/info/CESU-8)
在unicode官方文档中也有一些介绍
https://www.unicode.org/reports/tr26/tr26-2.html
oracle文档中虽然体现出UTF-8和AL32UTF8不是同一种编码
| Character Set | Supported in RDBMS Release | Unicode Encoding Form | Unicode Version | Database Character Set | National Character Set |
|---|---|---|---|---|---|
| AL24UTFFSS | 7.2 to 8i | UTF-8 | 1.1 | Yes | No |
| UTF8 | 8.0 to 21c | CESU-8 | Oracle Database release 8.0 through Oracle8i Release 8.1.6: 2.1 | Yes | Yes |
| Oracle8i Database release 8.1.7 and later: 3.0 | (Oracle9i Database and later versions only) | ||||
| UTFE | 8.0 to 21c | UTF-EBCDIC | Oracle8i Database releases 8.0 through 8.1.6: 2.1 | YesFoot 1 | No |
| For Oracle8i Database release 8.1.7 and later: 3.0 | |||||
| AL32UTF8 | 9i to 21c | UTF-8 | Oracle9i Database release 1: 3.0 | Yes | No |
| Oracle9i Database release 2: 3.1 | |||||
| Oracle Database 10g, release 1: 3.2 | |||||
| Oracle Database 10g, release 2: 4.0 | |||||
| Oracle Database 11g: 5.0 | |||||
| Oracle Database 12c, release 1: 6.2 | |||||
| Oracle Database 12c, release 2: 7.0 | |||||
| Oracle Database 18c to Oracle Database 19c: 9.0 | |||||
| Oracle Database 21c: 12.1 | |||||
| AL16UTF16 | 9i to 21c | UTF-16 | Oracle9i Database release 1: 3.0 | No | Yes |
| Oracle9i Database release 2: 3.1 | |||||
| Oracle Database 10g, release 1: 3.2 | |||||
| Oracle Database 10g, release 2: 4.0 | |||||
| Oracle Database 11g: 5.0 | |||||
| Oracle Database 12c, release 1: 6.2 | |||||
| Oracle Database 12c, release 2: 7.0 | |||||
| Oracle Database 18c to Oracle Database 19c: 9.0 | |||||
| Oracle Database 21c: 12.1 |
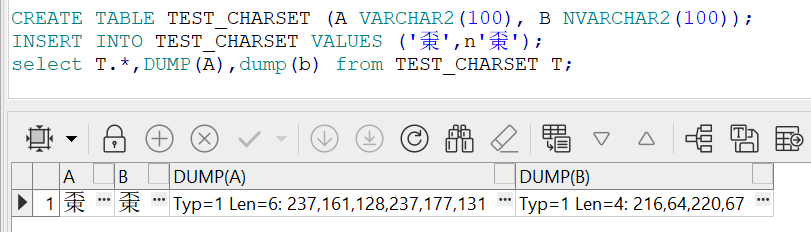
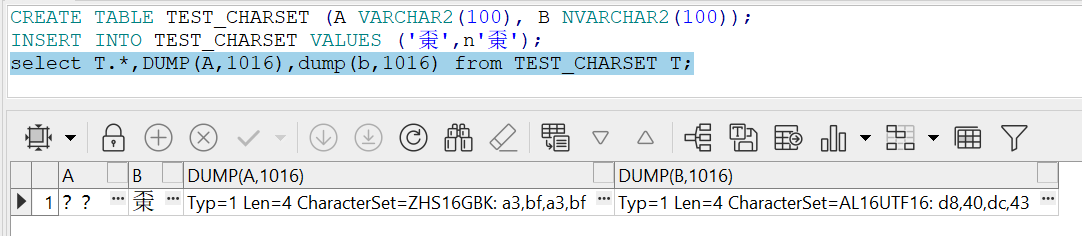
但是,测试会发现,oracle中的AL32UTF8其实还是CESU-8的做法,
CREATE TABLE TEST_CHARSET (A VARCHAR2(100), B NVARCHAR2(100));
INSERT INTO TEST_CHARSET VALUES ('𠁃',n'𠁃');
select T.*,DUMP(A),dump(b) from TEST_CHARSET T;
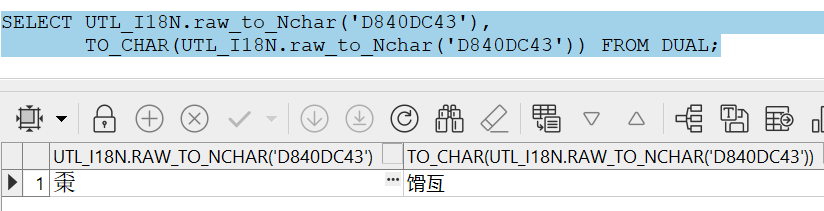
而且可能还会导致严重的字符歧义,比如
SELECT UTL_I18N.raw_to_Nchar('D840DC43'),
TO_CHAR(UTL_I18N.raw_to_Nchar('D840DC43')) FROM DUAL;
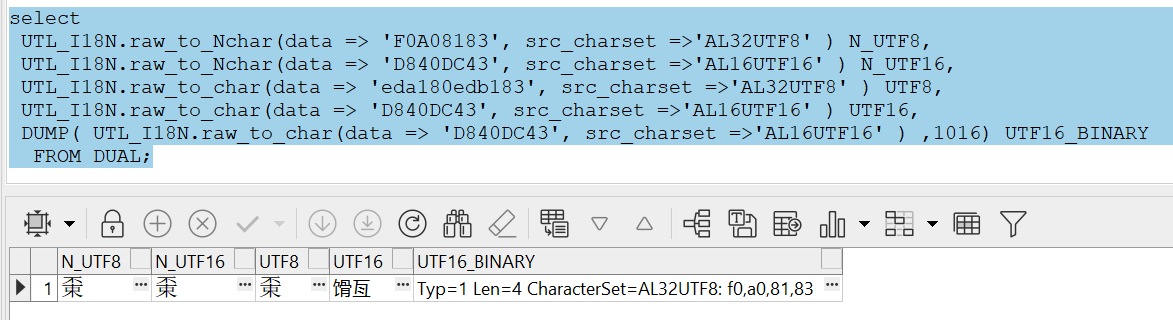
再来看下面的例子,会发现第一列此时又符合UNICODE标准的UTF-8编码了。
也就是说,在ORACLE中,字段类型必须是国家字符集的字符数据类型才会符合UNICODE标准
(注意第四个值的二进制数据其实是对的,符合UTF8的4个字节,但是在非国家字符集的字符类型中无法正确解析)。
select
UTL_I18N.raw_to_Nchar(data => 'F0A08183', src_charset =>'AL32UTF8' ) N_UTF8,
UTL_I18N.raw_to_Nchar(data => 'D840DC43', src_charset =>'AL16UTF16' ) N_UTF16,
UTL_I18N.raw_to_char(data => 'eda180edb183', src_charset =>'AL32UTF8' ) UTF8,
UTL_I18N.raw_to_char(data => 'D840DC43', src_charset =>'AL16UTF16' ) UTF16,
DUMP( UTL_I18N.raw_to_char(data => 'D840DC43', src_charset =>'AL16UTF16' ) ,1016) UTF16_BINARY
FROM DUAL;
所以并不能说ORACLE不遵守UNICODE标准,而是它在兼容原有的CESU-8的基础上,另外提供了一种符合UNICODE标准的方式,即使用国家字符集的字符数据类型来进行数据存储。
四、回顾相关函数
- ascii 传入一个字符,varchar/char类型根据数据库字符集,nvarchar/nchar根据国家字符集,转换成对应的十进制码点
- nchr 将一个十进制数字,根据国家字符集,转换成对应的一个字符
- chr(n) 将一个十进制数字,根据数据库字符集,转换成对应的一个字符
- chr(n using NCHAR_CS) 将一个十进制数字,根据国家字符集,转换成对应的一个字符(等同于nchr)
- unistr 将包含有国家字符集十六进制码点的字符串,转换成人类可识别的字符串
- asciistr 将一个字符串中所有的非ascii字符,根据国家字符集转换成对应的十六进制码点
也就是说,以上的函数,其实都隐含了两个不确定的参数,即数据库字符集和国家字符集。而这两个字符集,在建库的时候可以指定。也就是说,如果建库的时候不是选择的默认值,那么这些函数的查询结果就可能会有不同。
五、推翻传言
经过以上实验分析及相关资料查询后,我们可以做个这样的实验:
创建一个新库,把数据库字符集设置成ZHS16GBK,把国家字符集设置成UTF-8,
那么存入一个常见汉字到varchar2中会占2个字节,存入到nvarchar2中则占3个字节;存入一个英文字母到varchar2中和nvarchar2中均占1个字节,
传言被推翻。
当然,绝大多数情况下,不会有谁把国家字符集选择成UTF-8,甚至连ORACLE官方文档都是强烈建议,国家字符集要选AL16UTF16,所以本文前面说的这个传言依旧具有一定的指导意义。
六、数据长度
关于NVARCHAR2类型的长度
- 在MAX_STRING_SIZE = STANDARD时,
VARCHAR2的最大长度为4000个字节,且建表时,既可以指定最大字节长度也可以指定最大字符个数;
而nvarchar2只能指定最大字符个数,在国家字符集为AL16UTF16时,最大字符个数为2000;在国家字符集为UTF-8时,最大字符个数为4000。但实际上,它限定的最大存储长度依然只能是4000个字节,尽管指定它的列长度时的数字,并不能指定字节数。 - 在MAX_STRING_SIZE = EXTENDED时,相应的长度上限也会扩大。但同样,它的最大存储长度只能是32767个字节,而且指定列长度时只能指定字符个数
| 国家字符集 | NCHAR 数据类型的最大列大小 | NVARCHAR2 数据类型的最大列大小(当 MAX_STRING_SIZE = STANDARD 时) | NVARCHAR2 数据类型的最大列大小(当 MAX_STRING_SIZE = EXTENDED 时) |
|---|---|---|---|
| AL16UTF16 | 1000 个字符 | 2000 个字符 | 16383 个字符 |
| UTF8 | 2000 个字符 | 4000 个字符 | 32767 个字符 |
(注:MAX_STRING_SIZE参数是在oracle12c版本中新增的
https://docs.oracle.com/en/database/oracle/oracle-database/21/refrn/MAX_STRING_SIZE.html#GUID-D424D23B-0933-425F-BC69-9C0E6724693C
)
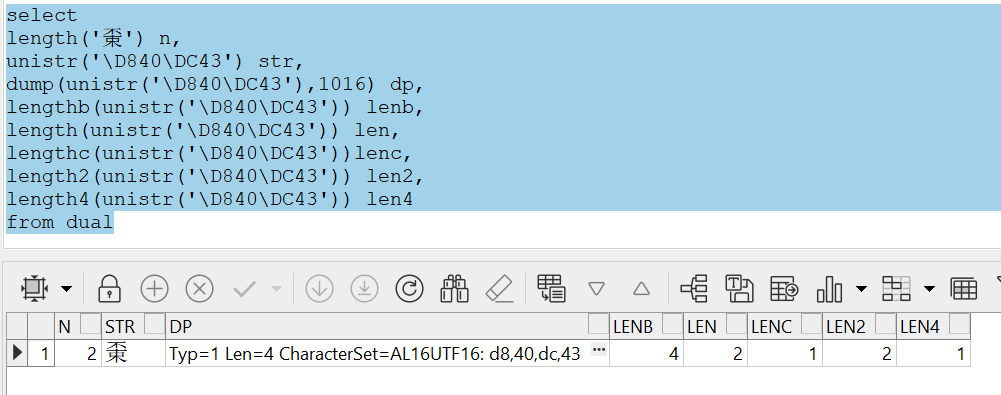
length函数查的是什么?
一直以来,网上各种教程里都是说,lengthb查的是字节数,length查的是字符数。但ORACLE里的字符数,计算标准其实也有很多种,像下面的这个一个汉字,用length函数查它竟然是2个字符!因为length不是按照unicode标准来进行统计的,lengthc才是,另外还有针对UCS2/UCS4标准的长度计算函数
select
length('𠁃') n,
unistr('\D840\DC43') str,
dump(unistr('\D840\DC43'),1016) dp,
lengthb(unistr('\D840\DC43')) lenb,
length(unistr('\D840\DC43')) len,
lengthc(unistr('\D840\DC43'))lenc,
length2(unistr('\D840\DC43')) len2,
length4(unistr('\D840\DC43')) len4
from dual
所以,如果ORACLE 11g中的国家字符集为AL16UTF16,对于nvarchar2(2000)字段,是有可能存入1000个字就满了的(全部存UTF-16编码为4个字节的补充字符的情况下)
七、国家字符集的使用场景
-
假设数据库字符集为ZHS16GBK,某次需要插入一个在这个字符集中不存在的汉字或其他语言的字符,该如何处理?
数据库的字符集建库时就确定了,不能轻易修改,如果把字段类型设置成国家字符集的数据类型,比如nvarchar2,那么就可以把这个ZHS16GBK中不存在的字符存进去了。(如果是子集改成母集,且不用对数据进行编码转换,那么可以使用DMU进行快速字符集修改)
-
某公司正在使用的一个纯英文的软件,对应的数据库字符集为WE8MSWIN1252,该软件把所有UI菜单及选项的描述都存在了数据库中,当该软件需要扩展多国语言时,只需要把描述列改成NVARCHAR2,然后增加一个语言ID,相关查询接口增加语言ID的逻辑,客户端代码采用UTF8,即可在不用重建数据库的情况下,扩展出UI多语言支持。
总结
ORACLE以标准名称命名非标准的东西,而且时而标准时而不标准,的确很让人犯迷糊,我根据本文总结几点
- ORACLE默认国家字符集为AL16UTF16,完全对应UNICODE的UTF-16标准
- ORACLE中的国家字符集,只有在数据类型为NCHAR/NVARCHAR/NCLOB时才会被使用,也就是前面带N(national)的字符类型
- ORACLE中的UTF-8,不是标准的UTF-8,而是CESU-8
- 尽管ORACLE称AL32UTF8是符合UNICODE标准的,但在VARCHAR2类型时体现的依然是CESU-8的特征(单个字符1~3字节,补充字符6字节)
- UNICODE码点在FFFF之前的,其码点和AL16UTF16完全一致,但更大的码点(补充码)就和AL16UTF16不一致了
- ORACLE的length函数把单个补充码字符的字符长度算为2
- UNISTR和ASCIISTR是用国家字符集转换,并非完全是UNICODE编码(不要拿着长度为5的unicode码去转换了,要找到对应4个字节的UTF-16编码去转,AL16UTF16的UNISTR只认"\xxxx"或“\xxxx\xxxx”的格式)
- UNICODE补充字符,存储为UNICODE标准的UTF-8编码,且能无需函数转换,直接select显示出正确字符的,在ORACLE中不支持,需要使用UTL_I18N包来处理,比如
select UTL_I18N.raw_to_Nchar(data => 'F0A08183', src_charset =>'AL32UTF8' ) from dual;

