





前言
在oracle数据库上进行开发的时候,经常会使用到raw类型,raw其实就是一段十六进制形式的二进制数据,最长长度和varchar2一致,都是32767个字节。在各种数据加解密或者数据传输时,使用二进制数据可以避免字符集异常或者特殊符号引起的程序运行错误。
在postgresql(截止到当前最新的14版本)中,没有raw类型,只能使用text或者bytea转换来处理,所以这个点可能会让迁移项目变得很头疼。
最近在写openGauss的兼容plsql包,正好写到了utl_raw,一开始我是完全按照postgresql中的bytea来写的,但后来突然发现在openGauss中有rawtohex和hextoraw两个函数,就去查了下,发现openGauss里竟然支持raw类型,而且还有一些raw类型的专用函数,就稍微研究了下(偶然发现目前openGauss官方文档内容比华为GaussDB官方文档内容要少,导致走了不少弯路)
官方文档
https://support.huaweicloud.com/devg-opengauss/opengauss_devg_0390.html
https://support.huaweicloud.com/devg-opengauss/opengauss_devg_0372.html
https://opengauss.org/zh/docs/2.1.0/docs/Developerguide/%E4%BA%8C%E8%BF%9B%E5%88%B6%E5%AD%97%E7%AC%A6%E4%B8%B2%E5%87%BD%E6%95%B0%E5%92%8C%E6%93%8D%E4%BD%9C%E7%AC%A6.html
文档这东西,看编写者的心思,可详细可简单,如果是要做研究,那还是结合看源码及实际测试来的好。
于是我先查了数据库里所有名称里带"raw"的函数,一共有18个,其中还有1个是重名的
select * from pg_proc h where h.proname like '%raw%'
| proname | prolang | prosrc | probin |
|---|---|---|---|
| bucketraw | 12 | bucketraw | |
| hextoraw | 12 | texttoraw | |
| rawcat | 12 | rawcat | |
| rawcmp | 12 | rawcmp | |
| raweq | 12 | raweq | |
| rawge | 12 | rawge | |
| rawgt | 12 | rawgt | |
| rawin | 12 | rawin | |
| rawle | 12 | rawle | |
| rawlike | 12 | rawlike | |
| rawlt | 12 | rawlt | |
| rawne | 12 | rawne | |
| rawnlike | 12 | rawnlike | |
| rawout | 12 | rawout | |
| rawrecv | 12 | bytearecv | |
| rawsend | 12 | byteasend | |
| rawtohex | 12 | rawtotext | |
| rawtohex | 13 | rawtohex | $libdir/plpgsql |
然后对照华为GaussDB的官方文档来看,可以发现文档里,这些函数绝大部分都没写清楚功能及测试案例,比如下面这四个函数,文档里的描述写的竟然都是一样的
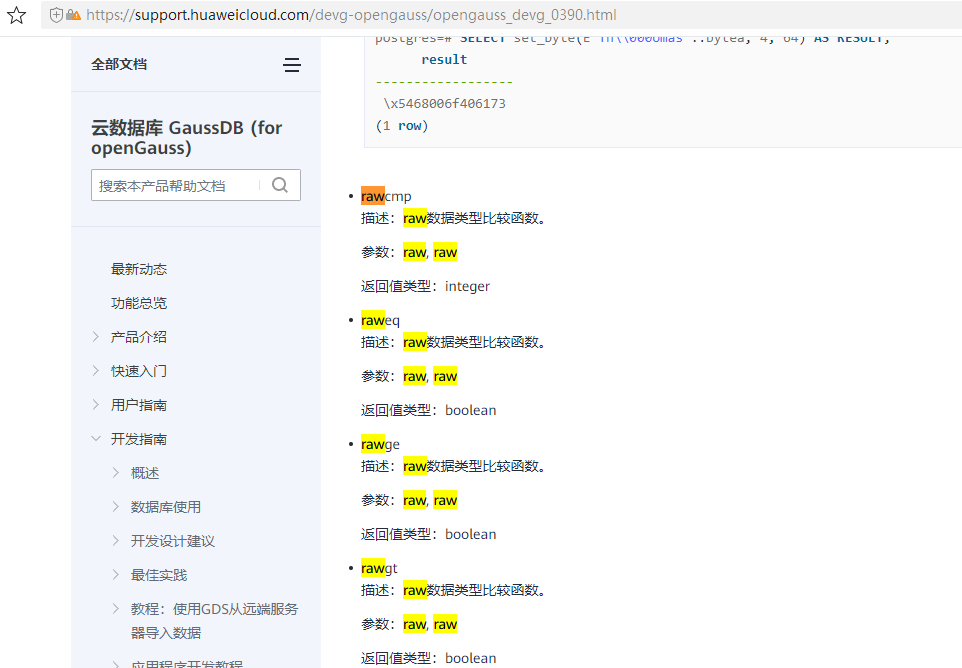
但好在大部分函数的命令是参考的基本运算符,所以能看懂个大概。
不过,绝对不能自以为是的以为这些函数的输出结果和你想的一样,稍不留神就会被坑了,所以我通过实际测试及结合看源代码,对这个函数列表整理了一份较为完整的说明,请重点留意下表中最后一列的注意事项
整理后的函数说明
| proname | prosrc | 功能说明 | 输入参数 | 输出参数 | 例 | 注意事项 |
|---|---|---|---|---|---|---|
| hextoraw | texttoraw | 将十六进制字符串转换成raw类型 | text | raw | select hextoraw('abcd') | |
| rawtohex | rawtotext | 将raw转换成十六进制字符串 | raw | cstring | select rawtohex('FF1122335566778899'::raw) | 同名函数,注意参数类型的区别 |
| rawtohex | rawtohex | 将字符串转换成十六进制RAW字符串 | text | text | select rawtohex('FF1122335566778899'::text) | 同名函数,注意参数类型的区别,输出结果不一样,这个是字符串的二进制数据再转成raw |
| rawcat | rawcat | 将两个raw按参数顺序从左至右拼成一个raw | raw,raw | raw | select rawcat('ab','cd') | 如果有多个值需要拼接,建议比较一些和管道符拼接的效率,实测,当拼接值很多的时候,管道符拼接的效率可能更高 |
| rawcmp | rawcmp | 先将两个raw按照较短的截至同样长度(字节长度),然后转换成十进制数字再相减得到的差 | raw,raw | int | select rawcmp('ffff','feff'),rawcmp('feff','1'),rawcmp('1','f'),rawcmp('FFF','FF'),rawcmp('FFFF','FF') | 这个内置函数是用的C语言的memcmp进行的处理,获得的是差,注意和python的cmp函数的区别 |
| raweq | raweq | 判断两个raw是否相等 | raw,raw | bool | select raweq('ab','aa') | |
| rawge | rawge | 判断第一个raw是否大于或等于第二个raw | raw,raw | bool | select rawge('ab','aa') | |
| rawgt | rawgt | 判断第一个raw是否大于第二个raw | raw,raw | bool | select rawgt('ab','aa') | |
| rawle | rawle | 判断第一个raw是否小于或等于第二个raw | raw,raw | bool | select rawle('ab','aa') | |
| rawlt | rawlt | 判断第一个raw是否小于第二个raw | raw,raw | bool | select rawlt('ab','aa') | |
| rawne | rawne | 判断两个raw是否不相等 | raw,raw | bool | select rawne('ab','aa') | |
| rawlike | rawlike | 先把两个raw转成字符串,再看是否like | raw,raw | bool | select rawlike('43616D65726F6E'::raw,'4325'::raw) | 第二个参数里,需要将通配符(%_)及转移符(\)的二进制数据转换成raw类型,此例实际上相当于'Cameron' like 'C%' |
| rawnlike | rawnlike | 先把两个raw转成字符串,再看是否 not like | raw,raw | bool | select rawnlike('43616D65726F6E'::raw,'4325'::raw) | 注意要进行和上面rawlike类似的处理 |
| rawin | rawin | 将raw字符串转换成bytea类型 | cstring | bytea | select rawin('43616D65726F6E') | 注意这里的输入类型不是raw也不是text |
| rawout | rawout | 将bytea转换成raw字符串 | bytea | cstring | select rawout('C%'::BYTEA) | 注意返回的类型不是raw,而是raw的十六进制字符串,而且也不是TEXT类型 |
| rawsend | byteasend | 将RAW转换成bytea类型 | raw | bytea | select rawsend('43616D65726F6E') | 和rawin一样的功能但输入参数类型不一样 |
| rawrecv | bytearecv | 将一个内部二进制数据转换成raw | internal | raw | 这个bytearecv在官方文档里没有介绍,属于pg的函数,但pg官方文档里同样没有介绍,不过根据源码可以得知功能 | |
| bucketraw | bucketraw | 计算raw参数的hash值 | raw,int | int | select bucketraw('FF',1) | 第二个参数表示数据分布方式,0表示hash分布。单节点模式无法使用此函数 |
其他
对于以上函数,还要注意的有以下几点
- 在存储过程中,cstring类型需要显式的转换成text才能输出,比如 参数::text
- raw和text之间可以直接显式转换 ,比如 参数::raw,参数::text
- raw在内核中其实也是相当于bytea进行的处理,可以使用到c语言的内存指令操作,一般会比字符串要处理得快。
但是如果不是用上述函数,而是用其他函数来处理raw,就会先隐式的转换成text再进行处理,这点尤其要注意,不仅执行效率会有变化,而且得到的结果可能会和预期不一致,比如使用length或substring函数时就和处理bytea类型时不一样

