





前言
众所周知,在去年年底,知名的免费cdn服务提供商jsdelivr由于大陆域名备案的问题,没有国内的CDN加速了,目前都只能解析到海外,不但速度慢,还会偶发性无法连接到服务器。因此国内超多网站都受到了影响。
有人说可以批量修改引用的url,都改成 unpkg.com,但实测,我的个人网站上有一半的js和css在这个站点上是没有的。
由于我的个人站点并没有提供多少花里胡哨的内容,所以我就想着把所有要从jsdelivr获取的文件都下载到服务器本地,不再从外部获取,没准哪天海外服务都没了那就芭比Q了。
操作步骤
-
打开博客模板文件夹,找出所有包含jsdelivr的链接,去重后发现有39个链接
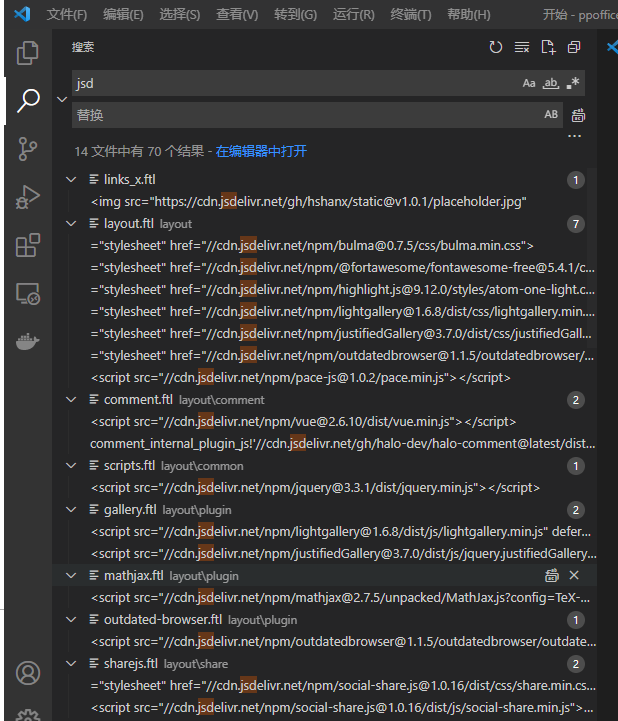
-
然后写入一个文本文件
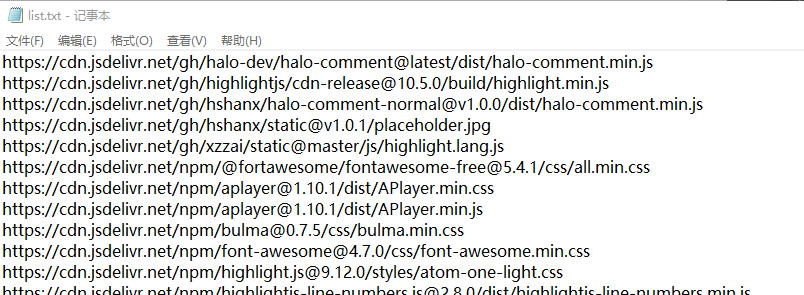
-
编写下载程序
可以看到这个目录结构相当复杂,如果要做最少的改动,应该让下载文件后的目录与链接路径保持一致,于是我想到了我以前曾经用网际快车下载过整个网站,但这玩意早就过时了,也懒得装软件。现在用python应该就可以实现,为避免重复造轮子,这种想法肯定有人也曾有过,于是先搜,轻松找到一篇文章
让Python自动下载网站所有文件 ! https://zhuanlan.zhihu.com/p/62876301
我把里面的程序复制出来,修改了入口函数,遍历url列表传入
import urllib.request
import requests
import re, os
# 基于 https://zhuanlan.zhihu.com/p/62876301 修改
def get_file(url):
'''
递归下载网站的文件
:param url:
:return:
'''
if isFile(url):
print(url)
try:
download(url)
except:
pass
else:
urls = get_url(url)
for u in urls:
get_file(u)
def isFile(url):
'''
判断一个链接是否是文件
:param url:
:return:
'''
if url.endswith('/'):
return False
else:
return True
def download(url):
'''
:param url:文件链接
:return: 下载文件,自动创建目录
'''
full_name = url.split('//')[-1]
filename = full_name.split('/')[-1]
dirname = "/".join(full_name.split('/')[:-1])
if os.path.exists(dirname):
pass
else:
os.makedirs(dirname, exist_ok=True)
urllib.request.urlretrieve(url, full_name)
def get_url(base_url):
'''
:param base_url:给定一个网址
:return: 获取给定网址中的所有链接
'''
text = ''
try:
text = requests.get(base_url).text
except Exception as e:
print("error - > ",base_url,e)
pass
reg = '<a href="(.*)">.*</a>'
urls = [base_url + url for url in re.findall(reg, text) if url != '../']
return urls
if __name__ == '__main__':
with open('list.txt', 'r') as f:
lines = f.readlines()
url_list = []
for line in lines:
get_file(line.strip('\n'))
-
执行
将上面的代码保存成py文件后执行,就会在当前目录下生成cdn.jsdelivr.net的主目录及其子目录和文件
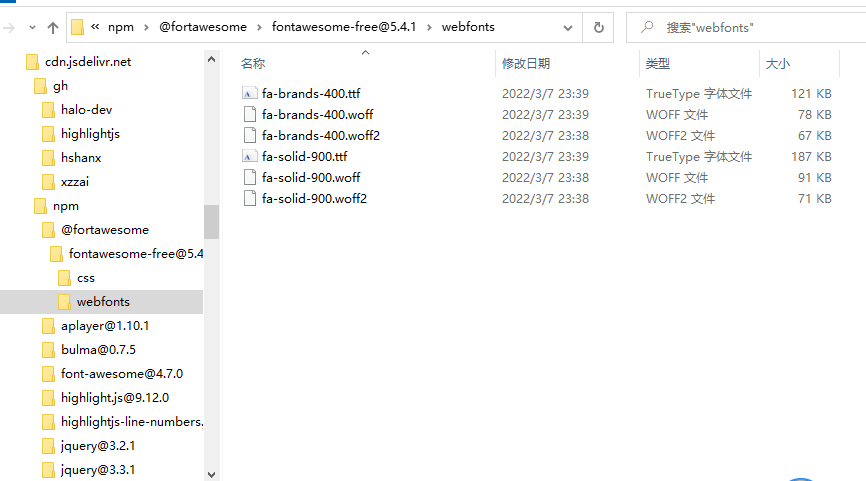
-
上传文件夹到服务器
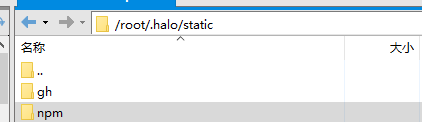
由于我是使用的halo博客,可以自定义添加静态资源,直接把下载的gh和npm两个文件夹整个拖到/root/.halo/static目录即可
-
修改博客模板中的链接
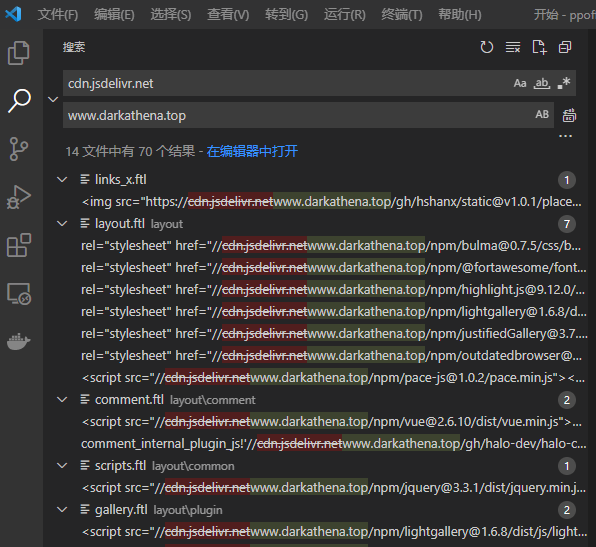
这个就容易了,直接打开模板中的所有文件,批量将cdn.jsdelivr.net替换成我网站的域名,并保存,覆盖到服务器上
-
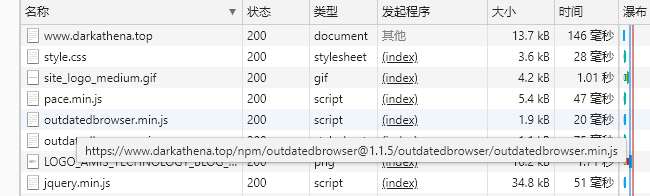
最终效果
说点题外的
有不少程序员习惯使用国外的免费服务,比如github和本文中提到的jsdelivr,大家也应该已经发现了这两个东西在国内已经是属于间歇性抽风的状态了。
当前国际形势越来越紧张,把东西放在国外的服务器上所要承担的风险越来越大,也应该要考虑将国外服务器上的东西迁移回本国了,否则哪天一个制裁,轻则断连,中则账号拉黑,重则把你数据直接删了也说不定。

