





前言
在21c发布后,很多文章中都提到了SQL宏,但看到的人们大多都有个疑问,这个SQL宏看上去和一般的函数没什么区别,为什么还要重点拿出来说?
我们先看看ORACLE官方是怎么说的
https://docs.oracle.com/en/database/oracle/oracle-database/21/nfcon/sql-macros-282902288.html
You can create SQL Macros (SQM) to factor out common SQL expressions and statements into reusable, parameterized constructs that can be used in other SQL statements. SQL macros can either be scalar expressions, typically used in SELECT lists, WHERE, GROUP BY and HAVING clauses, to encapsulate calculations and business logic or can be table expressions, typically used in a FROM clause.
您可以创建 SQL 宏 (SQM) 以将常见的 SQL 表达式和语句分解为可在其他 SQL 语句中使用的可重用、参数化构造。SQL宏可以是标量表达式,通常用在SELECT 列表中,WHERE,GROUP BY 和HAVING 子句,封装计算和业务逻辑,也可以是在FROM后的表名 。
这个解释还是很难看出到底有什么用,那就看看官方的例子吧
标量 表达式
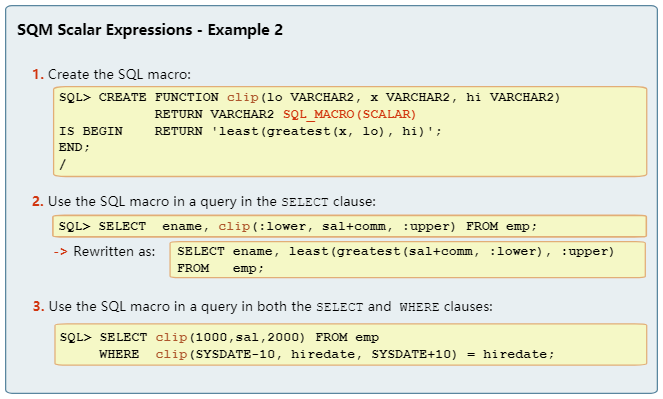
乍一看,还是个函数,但是这里最重要的一个词是"Rewritten as ",即“重写 为”。我为什么说这个最重要呢,因为这个词才是sql宏和普通函数的最大区别。
使用ORACLE自带的一些函数时,它会有原生的优化机制,效率会比使用同等效果的自定义函数要好。比如官方的这个例子,如果我们用普通的函数写法,应该是这个样子的
create function clip2(lo varchar2,x varchar2,hi varchar2)
return varchar2
is begin
return least(greatest(x,lo),hi);
end;
在使用这种函数的时候,会把每行数据中的这3个值,传入此函数,然后再计算出结果返回,相当于写了个循环,一行一行去执行,而且每次都是只对这三个值进行最小最大的计算;而使用sql宏则不一样,它是在执行前,会对sql语句进行重写,相当于把sql宏函数展开,让数据库认为它不是在执行用户自定义函数,而是在执行自带函数,此时它的执行顺序就变成了,先算两列的greatest,再算两列的least,效率得到了极大的提高。经常写plsql的都知道,自定义函数包了一层又一层,效率会变慢,跟踪会话时可以看到同一条sql在不断的循环,比如有时候要写报表对业务代码进行翻译,写个自定义函数去查码表,和直接用decode穷举两种方式,一般都是decode更快,就是这个原因。
我们稍微改造一下上面两个函数,加一个dbms_output进去,再执行
SET serveroutput on
create or replace function clip(lo varchar2,x varchar2,hi varchar2) return
varchar2 sql_macro(scalar)
is begin
dbms_output.put_line(1);
return 'least(greatest(x,lo),hi)';
end;
/
select clip(1000,SALARY,2000) from hr.employees;
create or replace function clip2(lo varchar2,x varchar2,hi varchar2) return
varchar2
is begin
dbms_output.put_line(1);
return least(greatest(x,lo),hi);
end;
/
select clip2(1000,SALARY,2000) from hr.employees;
你会发现,使用了sql宏的,dbms_output.put_line(1)只执行了一次,而普通函数,有多少行数据,dbms_output.put_line(1)就执行了多少次!
所以,当非ORACLE数据库迁移到ORACLE数据库时,虽然以前也可以在Oracle中写自定义函数来使用一些oracle中不存在的函数,但是效率很低,不过灵活使用sql宏后,可以更好的把oracle的性能利用起来。
比如mysql中的locate函数,在oracle中没有,此时我们可以在oracle中创建一个sql宏命名为locate,如下
create or replace function locate(str1 varchar2,str2 varchar2) return
varchar2 sql_macro(scalar)
is begin
return 'instr(str2,str1)';
end;
/
select locate('ab','abcdefg') from dual;
还有now()
create or replace function now return
varchar2 sql_macro(scalar)
is begin
return 'sysdate';
end;
select now() from dual;
sql宏除了上面这种写法,还可以用在from后面,当成表或视图来用。
表 表达式
官方的例子

同样也是重写sql,但是这个例子并不让人觉得惊奇,这和我平时写个视图有什么不同?
but,还是经常写sql报表的人,尤其是被sql视图简洁但效率低的矛盾折磨的人,可能会马上想到,既然它是个函数,里面的sql也是个字符串,那我是不是可以用传进去的参数来拼字符串,而且还可以把这个参数放在任意我想要的位置?
比如,假设我们有个这样的sql,统计每个department的salary,并且展现出这个department的名称
select b.department_id,
any_value(b.department_name) department_name,
sum(a.salary) salary
from hr.employees a, hr.departments b
where a.department_id = b.department_id
group by b.department_id;
或者也有人会这么写
select b.department_id, b.department_name, a.salary
from (select department_id, sum(a.salary) salary
from hr.employees a
group by a.department_id) a,
hr.departments b
where a.department_id = b.department_id;
这两种写法哪种写法效率高,这里不做分析,但,一旦把这两个sql写成视图,然后视图外有查询条件,比如
create view dept_sal_v as
select b.department_id, b.department_name, a.salary
from (select department_id, sum(a.salary) salary
from hr.employees a
group by a.department_id) a,
hr.departments b
where a.department_id = b.department_id;
select * from dept_sal_v where department_id=20;
此时,sql老手一眼就能识别出,这样做效率极低,因为这个查询条件可能影响不到这个视图里的执行计划,视图很可能是先把子查询全部都计算出来放到内存里去了,而最终却只要输出一行记录。如果不用视图,直接写成如下sql,肯定比这个视图效果要好
select b.department_id, b.department_name, a.salary
from (select department_id, sum(a.salary) salary
from hr.employees a
where a.department_id=20
group by a.department_id) a,
hr.departments b
where a.department_id = b.department_id;
所以就有人想了,能不能让视图也像函数那样带参数,参数放在自己指定的位置?在21c上线之前,我当时是想了各种奇技淫巧,比如用table函数加动态游标来实现查询条件“指哪打哪”的效果,或者定义一个全局变量在每次执行前先给变量赋值,但都不如一个简单的视图来得方便。
那么在21c出了这个sql宏后,我们来看看这个应该怎么用新特性来进行优化
CREATE OR REPLACE function dept_sal_macro (department_id number)
return varchar2 SQL_MACRO
is
stmt varchar(2000) := q'(
select b.department_id, b.department_name, a.salary
from (select department_id, sum(a.salary) salary
from hr.employees a
where a.department_id=dept_sal_macro.department_id
group by a.department_id) a,
hr.departments b
where a.department_id = b.department_id )';
begin
return stmt;
end;
/
select * from dept_sal_macro(20);
看看视图和sql宏的执行计划
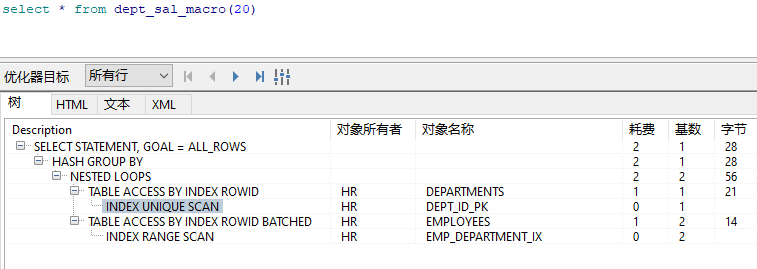
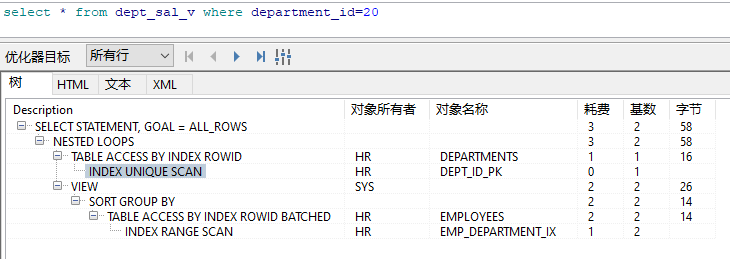
孰优孰劣,一目了然。
错误用法(或者说局限 ?)
既然它也是个函数的形式,自然就会想到一些其他的写法了,但我实测发现,sql宏传入的参数,不能作为对象名或者字段名,而且传入的参数,并不能直接被引用!
----错误用法一
CREATE OR REPLACE function select_table_marco (table_name varchar2)
return varchar2 SQL_MACRO
is
stmt varchar(2000) ;
begin
stmt := 'select * from '||table_name;
dbms_output.put_line(stmt);
return stmt;
end;
/
select * from select_table_marco('hr.countries');
select * from /*这一行输出说明此时table_name 这个参数的值是为空的*/
ORA-64626: invalid SQL text returned from SQL macro:
ORA-00903: invalid table name
----错误用法二
CREATE OR REPLACE function select_table_marco (table_name varchar2)
return varchar2 SQL_MACRO
is
stmt varchar(2000) ;
begin
stmt := 'select * from select_table_marco.table_name';
return stmt;
end;
/
select * from select_table_marco('hr.countries');
ORA-00942: table or view does not exist
----错误用法三
create or replace function select_table_marco (table_name table)
return varchar2 SQL_MACRO
is
stmt varchar(2000) ;
begin
stmt := 'select * from select_table_marco.table_name';
return stmt;
end;
/
FUNCTION SYS.SELECT_TABLE_MARCO 的编译错误
错误:PLS-00765: COLUMNS or TABLE is not allowed in this context
行:1
文本:create or replace function select_table_marco (table_name table)
----错误用法四
CREATE OR REPLACE function select_table_marco (table_name varchar2)
return varchar2 SQL_MACRO
is
stmt varchar(2000) ;
begin
stmt := 'select select_table_marco.table_name from hr.countries';
return stmt;
end;
/
select * from select_table_marco('COUNTRY_ID');
TABLE_NAME
-----
COUNTRY_ID
COUNTRY_ID
COUNTRY_ID
COUNTRY_ID
COUNTRY_ID
从以上错误的用法中可以了解到,这个sql宏绝不是oracle拿着现有的函数改的,它完全是一种新的机制。return 返回的虽然是个字符串变量,但完全不是想象中的把字符串拼完整就好了,传入sql宏的参数也仅仅只能作为要查询的值,而且只在return时,传入参数才会生效。
SQL宏的缺点
ORACLE把方便数据库移植当成了sql宏的一个用处,但是正是这个用处,让我发现了现阶段sql宏的缺点。
MYSQL中有一个函数,叫"ifnull",对应的其实就是oracl的"nvl",说移植,肯定要考虑这个函数,但实际上,ORACLE的SQL宏竟然无法支持完整移植这个函数作为SQL宏!
有些人看完上面的文章,应该会说这不很简单么,但一写代码就发现,咦,我这传入参数应该写什么类型的?
在ORACLE的标准函数里,nvl实际上有二十多个
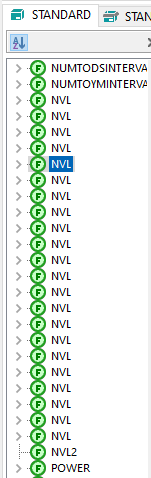
不同的NVL函数分别对应不同的参数类型,比如varchar2/number/date等,但是这种同名但参数类型不同的函数,只能写在package里面,这要如何实现?先写个包试试看看吧
create or replace package CUX_STANDARD is
function ifnull(a number,b number) return varchar2 sql_macro(scalar) ;
function ifnull(a varchar2,b varchar2) return varchar2 sql_macro(scalar) ;
function ifnull(a date,b date) return varchar2 sql_macro(scalar) ;
end CUX_STANDARD;
/
create or replace package body CUX_STANDARD is
function ifnull(a number, b number) return varchar2 sql_macro(scalar) is
begin
return 'nvl(a,b)';
end;
function ifnull(a varchar2, b varchar2) return varchar2 sql_macro(scalar) is
begin
return 'nvl(a,b)';
end;
function ifnull(a date, b date) return varchar2 sql_macro(scalar) is
begin
return 'nvl(a,b)';
end;
end CUX_STANDARD;
/
select CUX_STANDARD.ifnull(a.COMMISSION_PCT, 0),
CUX_STANDARD.ifnull(a.STATE_PROVINCE, '-')
from hr.emp_details_view a
where first_name in ('Susan', 'Alberto');
COMMISSION_PCT STATE_PROVINCE
---- ----
0.3 Oxford
0 -
然而这仅仅只能说明包里也可以使用SQL宏,但你依旧无法只用一个“IFNULL”来使用sql宏,用anydata这种类型也解决不了这个问题,同义词也无法执向包中的函数,至于再包一层函数,那又失去了使用SQL宏的意义。前面也说过了,普通的自定义函数效率不如数据库自带函数好。
不知道ORACLE接下来打算怎么解决这个问题

