





一、前言
经常写报表sql的小伙伴,应该都知道"分析函数"这一强大的功能,常见用法比如 取分组TOP-N、滚动求和、取当前行的上(下)N行等等。不过本篇不会再对这些常见基础用法进行介绍,只会说说那些关于"分析函数"可能不被人注意的事。
二、最早使用分析函数的数据库
有文章里说过,分析函数最早是在ORACLE8.1.6中出现的,我翻了下8.1.6和8.0的文档,发现的确如此(8.1.5版本文档已被移除,暂无法确认)
而ORACLE8.1.6是在1999年11月发布的,因此早在二十多年前(此文创作日期为2022-03-24),分析函数就已经诞生了。
Oracle 8.1.6 分析函数官方文档 :https://docs.oracle.com/cd/A81042_01/DOC/server.816/a76989/functio2.htm#81409
从分析函数诞生开始,就已经支持下面这些函数了,一共26个,但是可以发现,里面混进去了不少普通的聚合函数

根据上面的官方文档比较可得,在8.1.6版本中有以下13个函数是专用于分析函数的,这里也不用过多解释了
CUME_DIST
DENSE_RANK
FIRST_VALUE
LAG
LAST_VALUE
LEAD
NTILE
PERCENT_RANK
RANK
RATIO_TO_REPORT
ROW_NUMBER
STDDEV_POP
VARIANCE
oracle各版本文档,可以在oracle官网查询
最早甚至能查到oracle7
三、其他数据库支持分析函数的时间点及版本
1.“over()”
由于分析函数构成的语法分多个部分,各数据库并不是一开始全部都支持的,因此以最早的 "over()"来看
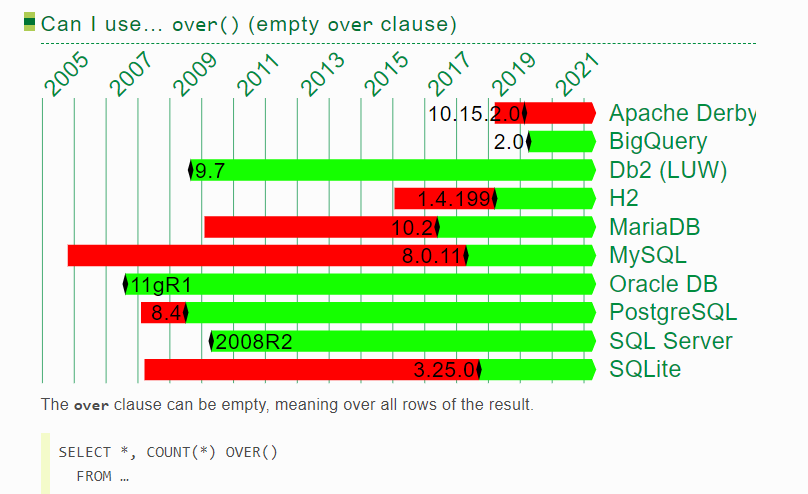
可以发现ORACLE 和DB2在很早就开始支持了,然后postgresql也是支持得相当早。但是这里要注意,虽然sqlserver2008和postgresql8.4已经开始支持over(),但是这个时候它们over的括号里只能分组,不支持排序,更加不支持指定窗口范围
另外一个值得注意的是,MariaDB虽然是从Mysql分支出来的,但前者却更早支持分析函数,这里严重批评mysql,作为最流行的关系型数据库长期榜首兼元老,竟然到了2017年才支持开窗函数,足足比oracle晚了18年!
2.“partition by”
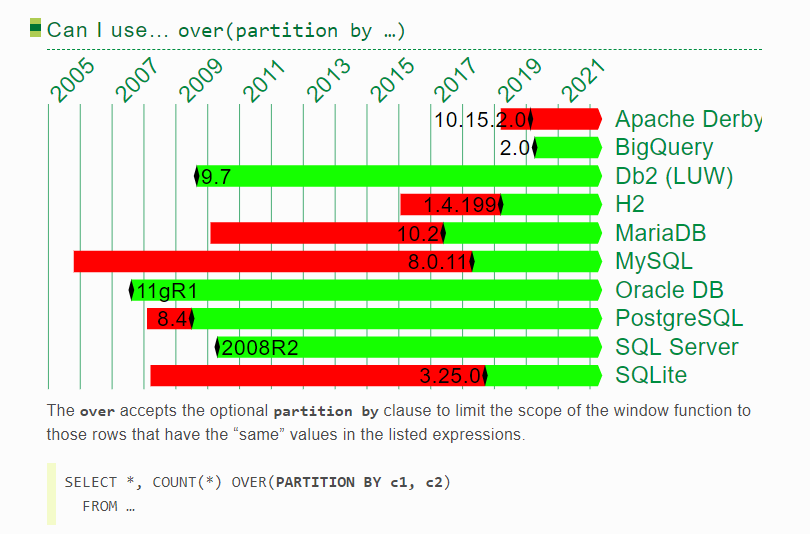
可以发现,这个时间和"over()“完全一致,因此基本可以认定,各数据库,只要支持分析函数,那么必然支持"partition by”
3.“order by”
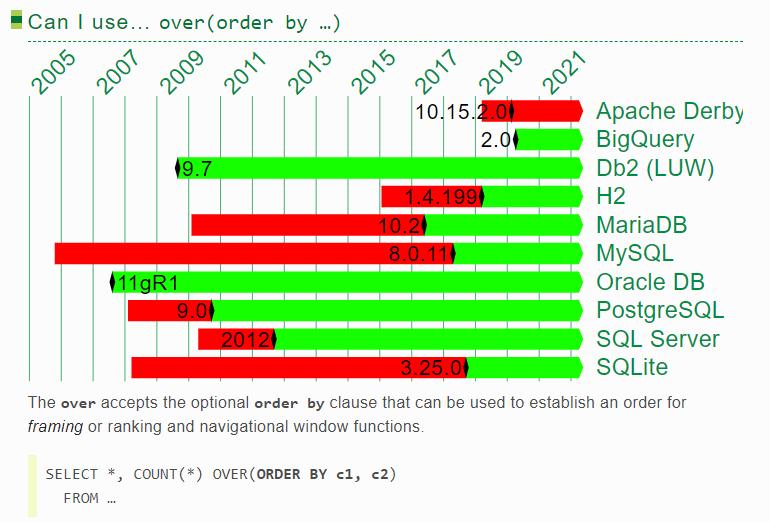
可以发现,postgresql 从9版本起、sqlserver从2012版本起,终于支持了分析函数中的排序,终于能舒坦的写写常用的分析函数sql了
4.“rows /range /groups”
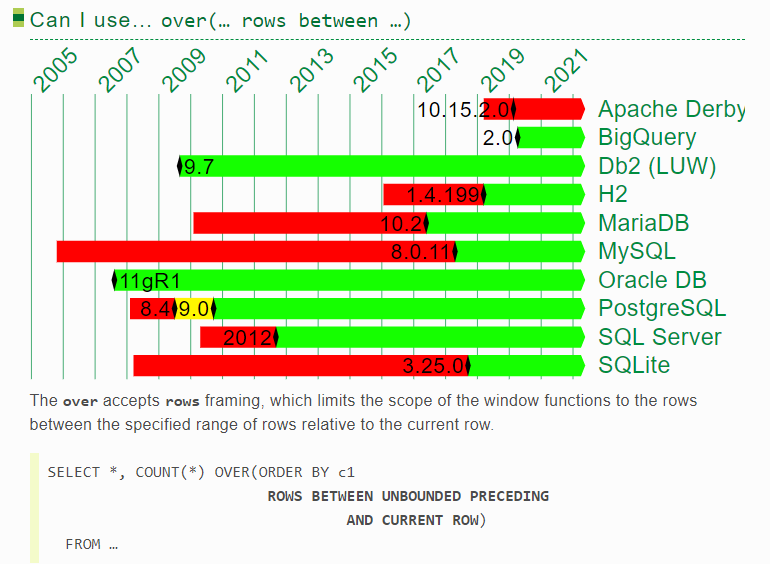
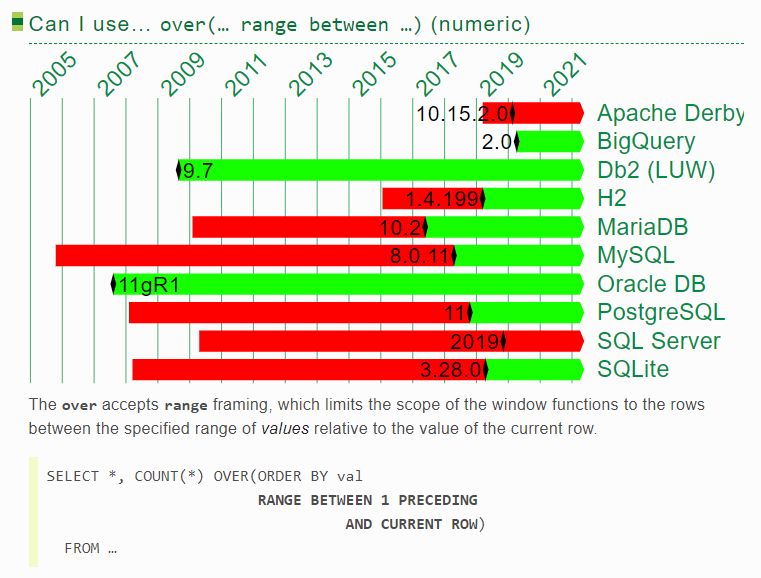
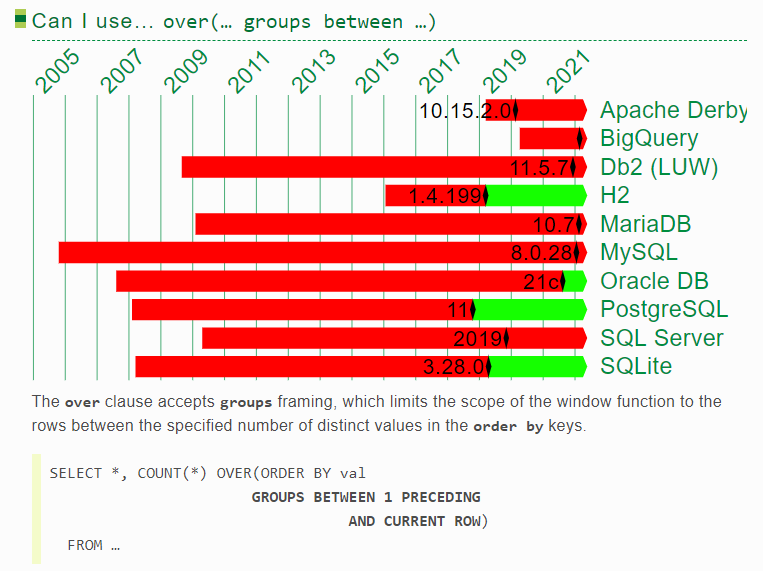
可以发现,ORACLE和DB2几乎一直都有接近最完整的分析函数体验,但在2017年到2020年,被postgresql/h2/sqlite反超了!range一直让人用得不爽,而postgresql率先支持了groups,这就是开源的力量!(关于rows/range/group的区别可参考 这篇文章中的一个示例 https://www.darkathena.top/archives/21c-analytic-functions)
5.“range (datetime)”
range的滑动窗口中,时间的支持可能才更加符合range的场景,但可惜的是,截至到2021年,只有oracle/postgresql/mysql/h2支持(未考虑其他衍生数据库)

6.关于大数据工具的支持
上面都没有提到HIVE,最近几个月有不少人咨询HIVE的一些sql,由于我之前并不常用HIVE,就稍微查了点资料,发现HIVE的分析函数体验基本也是完整的,像分组、排序、滑动窗口基本上都支持。
但某天,有个客户说从我这里拿到的sql在他的hive上执行报错,我一看,他是在imapa上执行的,这其实不是hive,报错的部分为滑动窗口定义。因为imapa的滑动窗口只支持使用上界(UNBOUNDED PRECEDING)、下界(UNBOUNDED FOLLOWING)、当前行(CURRENT ROW)三个参数来定义范围,不能精准的定位前N行或后N行。
也就是说,目前各种五花八门的数据库或者数据库工具,可能有的支持分析函数,但分析函数支持并不一定完整,然后在一些细节上可能也会有所区别
四、几乎所有的普通聚合函数都可用于分析函数
随着时代的发展,数字化时代的到来,人们对数据统计有了更多的要求,在数据库里有了越来越多的聚合函数就是其中的一个体现,从最新的oracle21c官方文档可以看到,它已经从8.1.6版本时的13个聚合函数,增加到了如今超过65个聚合函数!(其中 CORR_*/STATS_T_TEST_*/REGR_ (Linear Regression) Functions 为系列函数,拆开算有79个函数)
https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/Aggregate-Functions.html#GUID-62BE676B-AF18-4E63-BD14-25206FEA0848
五、分析函数本身的个数也在新增
从最新的21c官方文档里提取出专用的分析函数
https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/Analytic-Functions.html#GUID-527832F7-63C0-4445-8C16-307FA5084056
和最初的分析函数相比,增加了十几个专用的分析函数,其中和一般分析函数用法类似的有 “NTH_VALUE”,这个也是目前很多其他数据库还不支持的分析函数;
然后还增加了CLUSTER_*/FEATURE_*/PREDICTION_*三个系列共14个分析函数,语法和之前的分析函数有些不一样,是ORACLE针对机器学习而新增加的函数及语法,可参考官方文档
https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/PREDICTION.html#GUID-DA66A1C3-BFB2-43A1-A3FF-93D4A3DAB9C6;
除此之外,以前的分析函数,也有不少"降级"成了聚合函数,比如CUME_DIST/RANK/DENSE_RANK/PERCENT_RANK 等,但这些和常见的聚合函数不一样,这些函数需要使用"WITHIN GROUP"。眼熟?没错,就是在listagg函数里使用的那个语法
六、除了over,还有keep
相较于over分析函数的相关文章来说,keep分析函数的数量就少多了,但这个真不是什么新鲜玩意,早在oracle9.0.1版本中就出现了
https://docs.oracle.com/cd/A91034_01/DOC/server.901/a90125/functions55.htm#SQLRF00653
SELECT department_id,
MIN(salary) KEEP (DENSE_RANK FIRST ORDER BY commission_pct) "Worst",
MAX(salary) KEEP (DENSE_RANK LAST ORDER BY commission_pct) "Best"
FROM employees
GROUP BY department_id;
与keep相关的也就last和first两个函数,具体我就不在这里介绍了,想了解的请自行在网上用关键词搜索相关文章。
七、关于开窗函数和"group by"混用的情况
这里需要提到一个注意点,开窗函数表达式 只能用于select 及order by 后,不能放在 where 及 group by 后,因此这里所说的混用,其实是指开窗函数和普通聚合函数混用的情况。
先来看一个这样的sql
select job_id,
DEPARTMENT_ID,
sum(salary) over(partition by DEPARTMENT_ID)
from hr.employees
group by job_id,
DEPARTMENT_ID
上面这个sql是错误的,而且是新手常见的错误,执行会提示"ORA-00979: 不是 GROUP BY 表达式",把后面的group by删掉就不会报错了,但是又会发现出现了大量重复的数据,因为没有group by 也没有where,输出的行数就是原表的行数了。或者把salary也放到group by后面去也不会报错,但这样查询结果就更加不对了。
这个sql的本意应该是,一个DEPARTMENT_ID下有多个job_id,然后想得到每个job_id所在的DEPARTMENT_ID的薪水合计,如果思维局限在 分析函数里的字段和group by冲突的矛盾下,最后为了实现目标,可能会写出这样的sql
select distinct job_id,
DEPARTMENT_ID,
sum(salary) over(partition by DEPARTMENT_ID)
from hr.employees
虽然不算错,但这样耗费了大量的性能。
所以,我们要回到group by本身的语法规则来看看。
对于使用的常规聚合函数的sql,它select的非聚合函数字段(且非常量、非变量),必须接在group by 后面;反过来说,如果有使用group by ,那么select的字段必须是聚合函数字段或group by 后面出现的字段。
因此,我们再来看看下面这个sql
select job_id,
DEPARTMENT_ID,
sum(salary),
sum(sum(salary)) over(partition by DEPARTMENT_ID)
from hr.employees
group by job_id, DEPARTMENT_ID
可以看到这里使用了"sum(sum())"聚合函数里包聚合函数的写法,如果只看查询的前3个字段,很容易理解,重点就在于第四个字段中,内部的 sum(salary)其实就等同于第3个查询的字段,我们把其视为一个整体,丢到开窗函数里,再向上一个维度进行求和,这样就避开了上面的那个报错。
继续扩展一下,开窗函数的结构大致长这样
函数名(A) OVER(PARTITION BY B ORDER BY C)
其中的A/B/C三个东西,既可以是字段,也可以是值的表达式。并且,这3个东西,在group by语句的规则里,都属于 select 后面字段的规则,即它们“必须是聚合函数字段或group by 后面出现的字段”,所以,下面这样的sql在语法上也是正确的
select DEPARTMENT_ID,
sum(salary),
sum(sum(salary)) over(partition by sum(salary), DEPARTMENT_ID order by min(job_id))
from hr.employees
group by DEPARTMENT_ID
八、关于排序滑动窗口中使用count(distinct )
select t.*,
count(distinct salary) over(order by salary rows between 1 PRECEDING and 1 FOLLOWING)
from hr.employees t
上面这个sql也是错误的,会提示"ORA-30487: ORDER BY 在此禁用"。如果把order by 整个拿掉,或者把distinct去掉,就不会报错了。
在早几年的时候,我有在网上看过类似的讨论,当时几乎大家都认定了排序窗口(order by)里使用count(distinct )是不符合实际场景的,没有意义,没必要去支持,当时我也没多想,反正是count,排不排序的确没有意义。
但直到最近有个我看到了一个这样的问题
https://ask.csdn.net/questions/7658514?answer=53712384
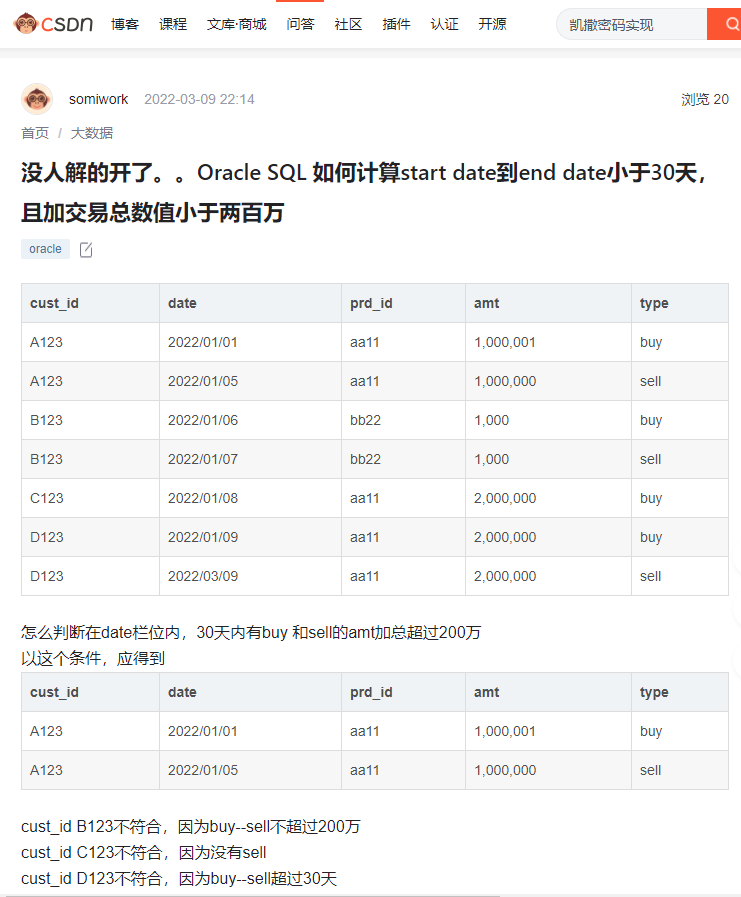
必须同时满足每一个统计区间里的"type"同时有两种不同的值,很容易就想到count(distinct type)=2,但是,这题要求使用30天的滑动窗口,一滑动就必然要排序,正好命中了上面说的这个“没必要去支持” 的场景!
这个需求很合理啊!
但为了解题,我迂回地使用了21c新增的函数bit_and_agg对count(distinct )进行了替代
bit_and_agg(case when type='sell' THEN 1 ELSE 0 END)
这是个聚合函数,在我使用的这个场景里,只要有不一样的值,它就会输出0,全部相同就输出1
我是真没想到这个函数还真的用上了,而且还解决了一个比较棘手的问题。
当然,如果不是21c,也有替代方式
trunc(EXP(SUM(LN(case when type='sell' THEN 2 ELSE 3 END))
这里其实是实现了一个累乘的效果,将两个值映射到两个不相等的质数上去,比如2和3,如果最后累乘的结果能被6整除,说明这一列出现了多个值。
所以经过这题后,我觉得oracle应该要改一下,虽然简单排序加去重的确没有意义,但是滑动窗口使用distinct是有意义的!
九、分析函数的进化、超进化和究极进化
1.ORACLE 10g 的model语法
这玩意是个比较难啃的内容,但model语法的确可以替代一些分析函数的使用场景,不过这是oracle独有的罢了。
SELECT country,prod,year,s
FROM sales_view
MODEL
PARTITION BY (country)
DIMENSION BY (prod, year)
MEASURES (sale s)
IGNORE NAV
UNIQUE DIMENSION
RULES UPSERT SEQUENTIAL ORDER
(
s[prod='Mouse Pad', year=2000] =
s['Mouse Pad', 1998] + s['Mouse Pad', 1999],
s['Standard Mouse', 2001] = s['Standard Mouse', 2000]
)
ORDER BY country, prod, year;
官方文档 https://docs.oracle.com/cd/B14117_01/server.101/b10759/expressions011.htm#sthref847
2.ORACLE 12c 的MATCH_RECOGNIZE语法
这玩意也是个比较难啃的内容,但MATCH_RECOGNIZE语法的确也可以替代一些分析函数的使用场景,尤其是在计算连续数据的拐点上,具有语法简洁易懂(maybe?)的优势,当然这也是oracle独有的罢了。
ELECT *
FROM Ticker MATCH_RECOGNIZE (
PARTITION BY symbol
ORDER BY tstamp
MEASURES STRT.tstamp AS start_tstamp,
LAST(DOWN.tstamp) AS bottom_tstamp,
LAST(UP.tstamp) AS end_tstamp
ONE ROW PER MATCH
AFTER MATCH SKIP TO LAST UP
PATTERN (STRT DOWN+ UP+)
DEFINE
DOWN AS DOWN.price < PREV(DOWN.price),
UP AS UP.price > PREV(UP.price)
) MR
ORDER BY MR.symbol, MR.start_tstamp;
官方文档
https://docs.oracle.com/database/121/DWHSG/pattern.htm#DWHSG8956
这里推荐一下itpub版主newkid的译文
http://www.itpub.net/forum.php?mod=viewthread&tid=2057442&page=1&extra=#pid23315171
3.ORACLE 18c 的分析视图(Analytic View)语法
这玩意名字就起得差劲,"Analytic"和 "View"这两个关键词在搜索时太容易引起歧义了,但这玩意的确是分析函数的究极进化版
SELECT geography_hier.member_name AS "Region",
units AS "Units",
units_geog_rank_level AS "Rank"
FROM ANALYTIC VIEW (
USING sales_av HIERARCHIES (geography_hier)
ADD MEASURES (
units_geog_rank_level AS (
RANK() OVER (
HIERARCHY geography_hier
ORDER BY units desc nulls last
WITHIN LEVEL))
)
)
WHERE geography_hier.level_name IN ('REGION')
ORDER BY units_geog_rank_level;
十、总结
数据库的一个功能不是说支持就支持的,从时间轴上来看,从1999年到最近,分析函数一直在增加新的内容。各大数据库厂商也在你追我赶,尽管直至目前仍然存在一些缺陷,但光从分析函数这一个点上,就已经能看到数据库未来无穷的可能性了,只要能充分发挥想象力,数据库就能不断地增加新的有用的功能
注:本文中关于功能支持时间轴的截图,均来自https://modern-sql.com

