




前言
先上成果预览图吧
作为一个数据库sql开发者,肯定有很多人和我一样,想要有一个工具,能传入任意sql,解析出sql中的所有表。
我之前有一篇文章【AIO】将任意查询sql转换成带远程数据库DBLINK的sql 中就提到了,使用纯文本硬解析会存在很多不确定因素,比如oracle新版本就添加了新的sql语法,有些场景太难处理,而解析器则只需要配置好规则,并且标准化规则的语法,那么扩展性就很强了。
antlr4 https://github.com/antlr/antlr4
Antlr这个老早就有了,如今已经比较成熟,像代码高亮插件prism就是用的这个。
但是,我找了好久,竟然在网上没找到一份有关“识别sql中的表名”的现成完整代码或者程序!解析其他语言的倒是有,但最后解析出来一个树就啥也不提了。
另外也找了很多问答,都是说Antlr4再加grammars-v4就可以解析sql了,但是就是不给代码。
无奈之下,我只能抱着github啃作者的文档,这作者只给了个使用Antlr4解析器最简单的例子,没给个实际开发语言解析的例子,我就只能靠着自己的理解加上看源码来看到底是怎么回事了。
首先,翻了很多文章,了解了Antlr4本身是个java程序,定义为解析器生成程序,而不是解析器本身。
可以编写符合规范的解析文档,文件名后缀为"*.g4",然后使用antlr4对这个g4文件生成其对应的解析器程序,在生成之前,可以指定好要生成哪种开发语言的能用的解析器,比如你想在python用,就传个python的参数进去,它就会生成对应的py文件;想生成java的,它就给你生成java文件。Antlr4支持的目标开发语言(不是指要解析的代码)目前多达9种
Cpp
CSharp
Dart
Go
Java
JavaScript
Python2
Python3
Swift
而理论上,Antlr4能解析的语法是无穷的,因为它本身并不带解析规则,解析规则完全依靠g4文件。
所以为了配合Antlr4,这个作者开了个项目,让大家都来写各种语言的g4文件
grammars-v4
https://github.com/antlr/grammars-v4
好家伙,打开这个项目一看,目前(2021-10-08)有多达240种语言的g4文件!
管他三七二十一,先把这两个项目的代码都下载下来。
然后对着Antlr4的文档,开干
https://github.com/antlr/antlr4/blob/master/doc/getting-started.md
操作步骤(windows)
第1步,安装java jdk
1.7版本以上,已安装请略过,前面说过了,Antlr4是java编写的解析器程序的生成程序,要运行java就得安装java,官方地址
https://www.oracle.com/java/technologies/downloads
第2步,下载Antlr4
地址 https://www.antlr.org/download/
找最新版的,文件名是这个格式的 antlr-4.9.2-complete.jar
建一个项目文件夹,我这里命名为 d:\sql_table,
把下载好的antlr-4.9.2-complete.jar文件,放入sql_table文件夹
第3步,设置环境变量
在系统环境变量中,添加 CLASSPATH 指向 d:\sql_table\antlr-4.9.2-complete.jar
第4步,下载并安装Antlr4的runtime
下载Antlr4的整个库
https://github.com/antlr/antlr4
打开压缩包,解压 \runtime\python3 文件夹至任意目录,
然后打开cmd,进入这个解压后的文件夹,
在cmd中运行
python setup.py install
第5步,获得plsql的语法文件
下载grammars-v4的整个库
https://github.com/antlr/grammars-v4
下载后,解压压缩包中以下几个文件,放到我们的项目目录d:\sql_table中去
- sql\plsql\PlSqlLexer.g4
- sql\plsql\PlSqlParser.g4
- sql\plsql\Python3\PlSqlLexerBase.py
- sql\plsql\Python3\PlSqlParserBase.py
第6步,生成解析器程序
打开cmd,定位到我们的项目目录 d:\sql_table
在cmd窗口中依次运行以下三条命令
doskey antlr4vpy3=java org.antlr.v4.Tool -Dlanguage=Python3 -no-listener -visitor $*
antlr4vpy3 PlSqlLexer.g4
antlr4vpy3 PlSqlParser.g4
运行后,目录内会生成以下几个文件
PlSqlLexer.py
PlSqlParserVisitor.py
PlSqlParser.py
PlSqlLexer.tokens
PlSqlLexer.interp
PlSqlParser.interp
PlSqlParser.tokens
至此,原材料才算准备齐全,接下来开始使用这个东西
第7步,测试
在刚刚解压的Antlr4\runtime\python3\bin目录下,有个pygrun文件,是用python语言编写的,把这个文件复制到我们的项目目录 d:\sql_table ,
然后打开cmd窗口,定位这里,在cmd'中执行,注意区分大小写
python pygrun -t PlSql sql_script
然后再输入一个sql,注意必须都大写, 比如
SELECT A FROM B
再 ctrl+z,回车
稍等一会儿,程序就会返回
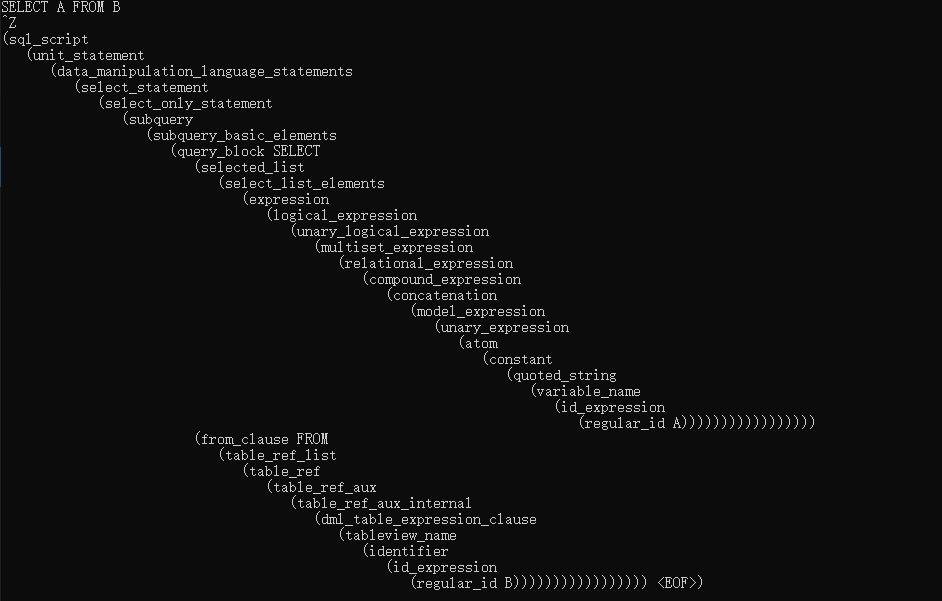
有一说一,这个性能真的有点差。
这里提几点,
- pygrun 后面的参数中 -t表示生成树显示出来,不加就只解析语法是否正确。
- 必填的两个参数为 语法名称 和 开始规则
- 语法名称即为PlSqlLexer.py这个文件中, Lexer.py之前的几个字符,如果不匹配就会说找不到
- 传入SQL必须大写,作者说是希望规范化,但是实际上大小写混用真的很难识别
这个开始规则传什么,我研究了不少时间,它来源于PlSqlParser.g4文件中,一开始我想的是我要找from后面的表,就传了个from_clause,结果没识别出来,然后我又换成query_block,才识别出来,中间还被sql的大小写坑了,但是我换了个例子,用WITH开头的sql,又识别不出来了。仔细看这个PlSqlParser.g4文件的内容,是分一段一段的,其中有一段这个
subquery_basic_elements
: query_block
| '(' subquery ')'
;
subquery_operation_part
: (UNION ALL? | INTERSECT | MINUS) subquery_basic_elements
;
query_block
: SELECT (DISTINCT | UNIQUE | ALL)? selected_list
into_clause? from_clause where_clause? hierarchical_query_clause? group_by_clause? model_clause? order_by_clause? fetch_clause?
;
query_block作为一个开始规则,同时出现在了subquery_basic_elements下面,是不是代表这个是包含关系?
所以我一路找,找到了最顶层的,就是
sql_script
: ((unit_statement | sql_plus_command) SEMICOLON?)* EOF
;
把sql_script带进去,没错了,只是速度会比之前用query_block更慢,但这样兼容性更高
另外,这个pygrun有更新版本,支持界面显示树,加上 -g 参数即可,下载在这里
https://github.com/jszheng/py3antlr4book/tree/master/bin
效果如下
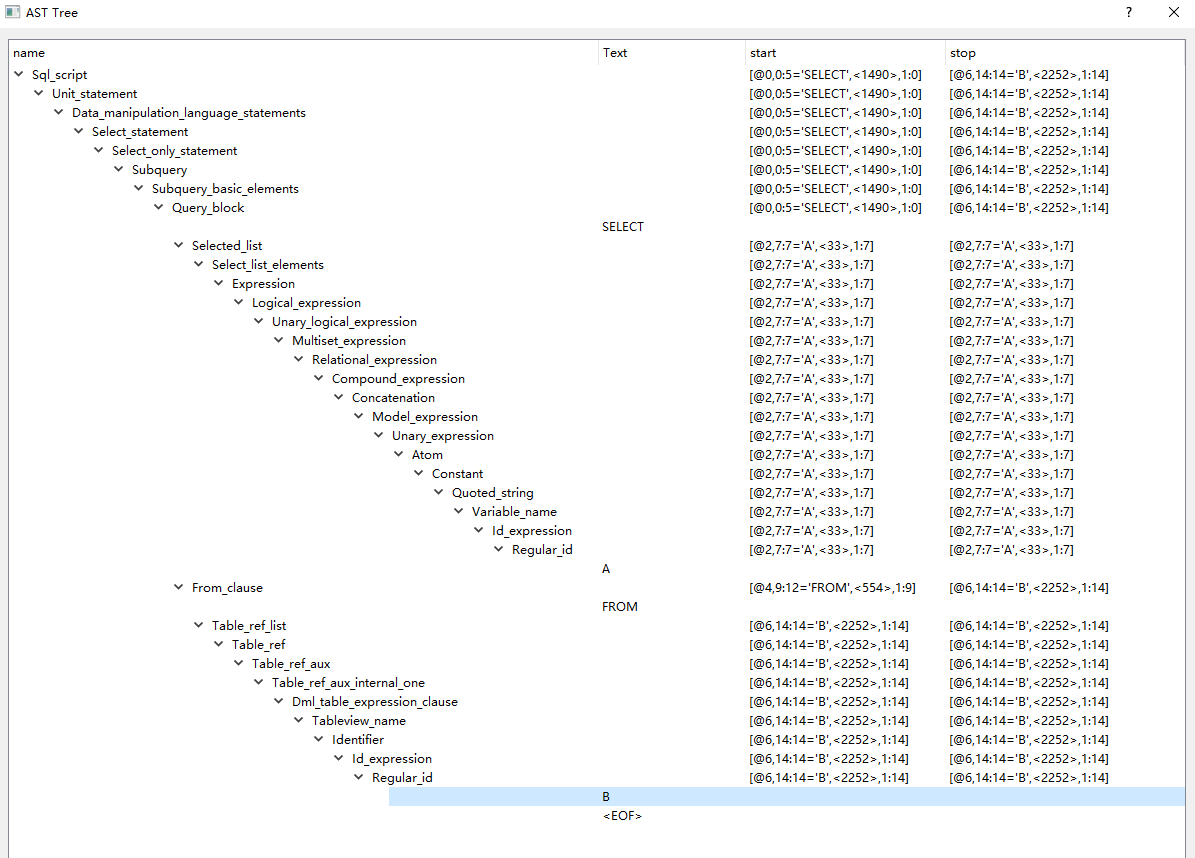
有了这个例子,我们就要看怎么把我们要的东西挑出来了
第8步,编写获取表名的程序
这里提一个名词 ,叫 面向对象编程, 之前看python教程的时候不觉得咋样,这次是真被折磨了,如果懂java的估计早就习惯了,但我纯自己写java实在太少,属于那种能查问题但不会写的。这个解析器里面用了好多自定义类,进去是啥知道,要不是开了源,压根就不知道出来的是啥,也不知道它有哪些方法(虽然用命令可查,但是我习惯了“记事本编程”,没有一边查定义一边编程的习惯),所以参考它这个带界面的那段程序,是一行一行写进去的,我们不需要界面,只需要知道怎样循环它,怎样拿它的值就行了,说这些,我肯定被java大佬鄙视了吧,这里python的逻辑和java太像了。。。
根据这个界面分析,拿着原始sql,一个个位置数,看哪些关键字用得上。
最后经过多种sql的验证,找出了Tableview_name这一层对应的start和stop中,包含有这个表名的开始位置和结束位置。
因为表名 可能由 “用户名.表名@DBLINK 别名” 这一长串组成,这个解析器会把这些词分成很多截,我需要的是个完整的,但不包含别名的部分,只有Tableview_name中的几个数字才能凑出准确的位置
即start中 第一个 逗号和第一个冒号之间的数字为开始位置,
stop中 ,第一个冒号和第一个等于号之间的数字加1为结束位置
分析到这里,
程序来了
import os
import re
from antlr4 import *
#file_name=r'test.sql'
tb_list=[]
def get_table_position( node):
if isinstance(node, ParserRuleContext):
class_name = str(type(node))
if str(class_name)=="<class 'PlSqlParser.PlSqlParser.Tableview_nameContext'>":
tb_list.append([re.split(r'[,:]',str(node.start))[1],re.split(r'[:=]',str(node.stop))[1]])
if hasattr(node, 'children'):
for child in getattr(node, 'children'):
get_table_position(child)
return tb_list
def get_table(l_sql):
lexerName = grammar + 'Lexer'
parserName = grammar + 'Parser'
module_lexer = __import__(lexerName, globals(), locals(), lexerName)
class_lexer = getattr(module_lexer, lexerName)
module_parser = __import__(parserName, globals(), locals(), parserName)
class_parser = getattr(module_parser, parserName)
#input_stream = FileStream(file_name)
input_stream = InputStream(l_sql.upper())
lexer = class_lexer(input_stream)
token_stream = CommonTokenStream(lexer)
token_stream.fill()
parser = class_parser(token_stream)
parser.buildParseTrees = True
func_start_rule = getattr(parser, start_rule)
parser_ret = func_start_rule()
tb_p=get_table_position(parser_ret)
return tb_p
grammar='PlSql'
start_rule='sql_script'
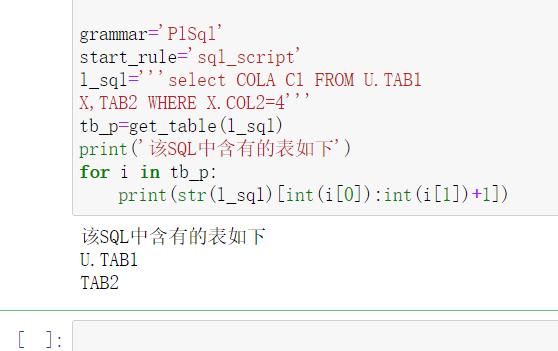
l_sql='''select COLA C1 FROM U.TAB1
X,TAB2 WHERE X.COL2=4'''
tb_p=get_table(l_sql)
print('该SQL中含有的表如下')
for i in tb_p:
print(str(l_sql)[int(i[0]):int(i[1])+1])
直接运行,就得到了本文最开始的那个效果。
有两行注释掉了,可以切换传入文件名
完整程序包
已完成新建文件夹,最近天气不好,有点累,休息一下,以后再弄
我打算把整个过程需要用到的文件,包括安装命令,封一个包出来,然后程序也封装成一个函数,输入文件或者字符串返回结果,另外加上那个自动转换成dblink的功能,再让这个程序兼容在oracle中使用,就完美了。
另外java版本的制作方式也极其类似,只多了一步,在生成解析器程序后,要用javac命令编译生成的解析器程序,我本地已测试成功,大佬们应该比我会玩,就不多说了
2021-10-15 更新
项目已上传github
https://github.com/Dark-Athena/list_table_sql-py

