





起因
目前新的个人博客网站是很难在搜索引擎收录的,就算在搜索引擎注册了站长、提交了sitemap、添加了统计代码和点击热点脚本,也做了SEO,也还是搜不到。
那么为了增加自己文章的曝光度,可以选择多添加友链,但扪心自问,你自己找到一篇文章的时候会去看友链么?当然友链其实作为网站页面内容来被搜索引擎检索的,不过这需要贴你友链的网站本身就已经有相当高的曝光度了。
所以,为了增加曝光度,我想了个方案,就是把自己的文章在各大博客网站上都发一遍,并且文章中偶尔引用到自己个人博客的地址,这样能提高搜索引擎搜索到的概率。
因为我一开始就是用halo在写博客,然后还有个十三年的csdn账号,就想着把halo的文章批量同步到csdn上去。
为了避免重复造轮子,当然是先度娘和github走一遍。
先了解到了各大博客实际上是有个统一的标准接口的,而且微软的word里甚至都可以直接发布到博客。但是前几年,国内博客网站把这个标准接口都关闭了,而且没有提供官方的公共api,所以只能模拟页面上的http请求了。
然后没有找到现成的,不过倒是找到了将本地markdown文章通过api发送到各大博客网站的,用的node.js,
https://github.com/onblog/BlogHelper
我下载下来看了下,先是打开页面手动登录,程序会保存cookie,然后选择md文件发布到用户选择的一个博客网站,程序就会模拟个http请求发布,再校验是否发布成功。
这个程序依赖了很多node.js的库,占用空间比较大,而且功能比较多,所以代码也有点复杂,而且还必须先生成md文件才能用这个程序发布
所以我就想到了干脆自己用python写个简单的。
分析
1.首先,halo是有api的,只要在博客设置里开启了api功能并设置了api_access_key,就可以使用halo提供的各种api了
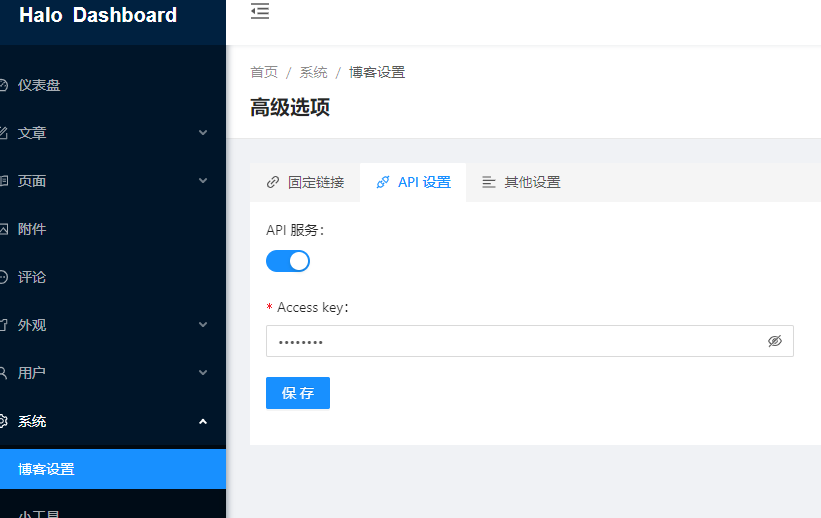
API文档 https://api.halo.run/
2.先获取文章列表,可以通过 /api/content/posts? 这个接口,设定size为一个很大的值,至少要等于在halo博客中发布的文章数,这样就可以不分页,一次性获取所有的文章列表
3.解析出每一篇的文章的 article_id 和 title,这里可以把自己不想同步的文章去掉
4.再使用article_id调用/api/content/posts/$article_id ,获取文章的细节(halo页面上不显示文章id...)
5.提取出文章的markdown文本
6.由于halo博客中可以使用各种相对引用,比如附件和文章,所以这里需要对文章内容中的相对引用替换成绝对引用
7.csdn登录是需要用户名密码加滑块验证码的,虽然python能做,但手动获取cookie也不麻烦,所以就还是手动登录自行保存cookie
8.分析了csdn保存草稿的http请求,几个参数都可以提供,然后发布时实际是调用的同一个接口,又会多几个参数,比如文章id、是否原创、分类、标签等,然后状态由草稿改成发布。我看那个上面那个node.js写的,是100%的复刻了页面上的请求参数,用if区分了是保存草稿还是发布,而且发布还模拟了先保存草稿获取id再发布。但是我想,除了状态不一样,id不用给,其他的参数在保存草稿的时候其实可以一并写入,压根就没必要做什么草稿和发布的判断,因为其他要传的值是完全一样的。
代码
以下代码我使用了手动添加文章列表的方式,因为我只需要指定的几篇同步,而且查文章id还只能用接口查;
如果需要全站同步,可以自行改成用接口获取文章列表的方式
https://github.com/Dark-Athena/sync-halo-to-csdn_py
# -*- coding: utf-8 -*-
#功能 :批量同步halo博客文章到csdn
#日期 :2021-10-03
#作者:Dark-Athena
#email :darkathena@qq.com
"""
Copyright DarkAthena(darkathena@qq.com)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
import requests,json,time
import markdown,urllib
#参数配置
#1.halo博客主站网址,这里改成你自己的
url_halo_main='https://www.darkathena.top'
#2.halo后台配置的api_access_key
halo_key='**********'
#3.提前手动保存好的已登录的csdn的cookie文本文件,可用chrome浏览器F12获得
csdn_cookie_path=r'd:\py\csdn-cookie.txt'
#4.状态: 0发布,2草稿
status=2
#5.要同步的文章完整标题列表,请自行添加
title_list=[]
title_list.append('【python】自动更换本地HOSTS中github.com的ip指向为最低延迟ip')
title_list.append('【云】对象存储服务亚马逊云S3、腾讯云cos、阿里云oss的命令行工具使用方式整理')
title_list.append('【ORACLE】关于多态表函数PTF(Polymorphic Table Functions)的使用')
#csdn保存文章的api,不要动
csdn_url = 'https://blog-console-api.csdn.net/v1/mdeditor/saveArticle'
#获取halo博客文章内容
def get_content(title,key):
url_search =url_halo_main+'/api/content/posts?keyword='+title+'&api_access_key='+halo_key
url_get_content =url_halo_main+'/api/content/posts/articleId?&api_access_key='+halo_key
#查找文章清单
s =requests.get(url_search)
t =json.loads(s.text)
#halo搜索可能找到多篇文章,这里做标题精准匹配以找到唯一的articleId
for i in t['data']['content'] :
if i['title']==title:
id=i['id']
response =requests.get(url_get_content.replace('articleId',str(id)))
t =json.loads(response.text)
#获取原始文章内容
originalContent=t['data']['originalContent']
#将文章内相对路径改成绝对路径
newcontent=originalContent.replace('(/upload/','('+url_halo_main+'/upload/')
newcontent=newcontent.replace('(/archives/','('+url_halo_main+'/archives/')
#csdn部分代码块语言类型不识别
newcontent=newcontent.replace('```plsql','```sql')
newcontent=newcontent.replace('```HTML','```html')
return newcontent
#同步到csdn
def push_csdn(title,content):
data = {"title":title,
"markdowncontent":content,
"content":markdown.markdown(content),
"readType":"public",
"status":status,
"not_auto_saved":"1",
"source":"pc_mdeditor",
"cover_images":[],
"cover_type":0,
"is_new":1,
"vote_id":0,
"pubStatus":"draft",
"type": "original",
"authorized_status":False,
"tags":"",
"categories":""}
cookie=open(csdn_cookie_path,"r+",encoding="utf-8").read()
headers={"content-type": "application/json;charset=UTF-8",
"cookie": cookie,
"user-agent": "Mozilla/5.0"}
response = requests.post(csdn_url,data=json.dumps(data),headers=headers)
result = json.loads(response.text)
return result
#执行
try:
for title in title_list:
content=get_content(title,halo_key)
result=push_csdn(title,content)
if result["code"]==200:
print(result["code"],result["msg"],result["data"]["title"])
else:
print(result["code"],result["msg"])
time.sleep(30)#csdn设置了两篇文章发布间隔小于30秒会报错
except Exception as e:
print(e)
使用
先保存登录csdn的cookie文件,然后把以上代码中的参数12345项都修改好后,直接执行即可
最后
之后还会考虑写同步到博客园和itpub的代码,再看有没有什么办法能集成到halo后台界面里

